 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Retrofitting
Oct 15, 2024AfterLearnER (After Learning Evolutionary Retrofitting) consists in applying non-differentiable optimization, including evolutionary methods, to refine fully-trained machine learning models by optimizing a set of carefully chosen parameters or hyperparameters of the model, with respect to some actual, exact, and hence possibly non-differentiable error signal, performed on a subset of the standard validation set. The efficiency of AfterLearnER is demonstrated by tackling non-differentiable signals such as threshold-based criteria in depth sensing, the word error rate in speech re-synthesis, image quality in 3D generative adversarial networks (GANs), image generation via Latent Diffusion Models (LDM), the number of kills per life at Doom, computational accuracy or BLEU in code translation, and human appreciations in image synthesis. In some cases, this retrofitting is performed dynamically at inference time by taking into account user inputs. The advantages of AfterLearnER are its versatility (no gradient is needed), the possibility to use non-differentiable feedback including human evaluations, the limited overfitting, supported by a theoretical study and its anytime behavior. Last but not least, AfterLearnER requires only a minimal amount of feedback, i.e., a few dozens to a few hundreds of scalars, rather than the tens of thousands needed in most related published works. Compared to fine-tuning (typically using the same loss, and gradient-based optimization on a smaller but still big dataset at a fine grain), AfterLearnER uses a minimum amount of data on the real objective function without requiring differentiability.
Diverse Diffusion: Enhancing Image Diversity in Text-to-Image Generation
Oct 19, 2023Latent diffusion models excel at producing high-quality images from text. Yet, concerns appear about the lack of diversity in the generated imagery. To tackle this, we introduce Diverse Diffusion, a method for boosting image diversity beyond gender and ethnicity, spanning into richer realms, including color diversity.Diverse Diffusion is a general unsupervised technique that can be applied to existing text-to-image models. Our approach focuses on finding vectors in the Stable Diffusion latent space that are distant from each other. We generate multiple vectors in the latent space until we find a set of vectors that meets the desired distance requirements and the required batch size.To evaluate the effectiveness of our diversity methods, we conduct experiments examining various characteristics, including color diversity, LPIPS metric, and ethnicity/gender representation in images featuring humans.The results of our experiments emphasize the significance of diversity in generating realistic and varied images, offering valuable insights for improving text-to-image models. Through the enhancement of image diversity, our approach contributes to the creation of more inclusive and representative AI-generated art.
PrivacyGAN: robust generative image privacy
Oct 19, 2023Classical techniques for protecting facial image privacy typically fall into two categories: data-poisoning methods, exemplified by Fawkes, which introduce subtle perturbations to images, or anonymization methods that generate images resembling the original only in several characteristics, such as gender, ethnicity, or facial expression.In this study, we introduce a novel approach, PrivacyGAN, that uses the power of image generation techniques, such as VQGAN and StyleGAN, to safeguard privacy while maintaining image usability, particularly for social media applications. Drawing inspiration from Fawkes, our method entails shifting the original image within the embedding space towards a decoy image.We evaluate our approach using privacy metrics on traditional and novel facial image datasets. Additionally, we propose new criteria for evaluating the robustness of privacy-protection methods against unknown image recognition techniques, and we demonstrate that our approach is effective even in unknown embedding transfer scenarios. We also provide a human evaluation that further proves that the modified image preserves its utility as it remains recognisable as an image of the same person by friends and family.
Fairness in generative modeling
Oct 06, 2022
We design general-purpose algorithms for addressing fairness issues and mode collapse in generative modeling. More precisely, to design fair algorithms for as many sensitive variables as possible, including variables we might not be aware of, we assume no prior knowledge of sensitive variables: our algorithms use unsupervised fairness only, meaning no information related to the sensitive variables is used for our fairness-improving methods. All images of faces (even generated ones) have been removed to mitigate legal risks.
EvolGAN: Evolutionary Generative Adversarial Networks
Sep 28, 2020

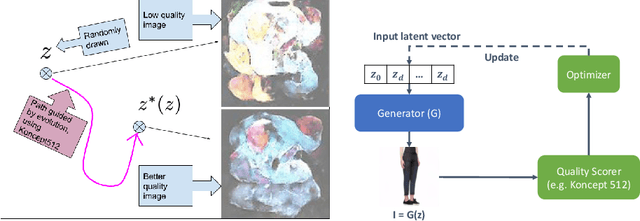
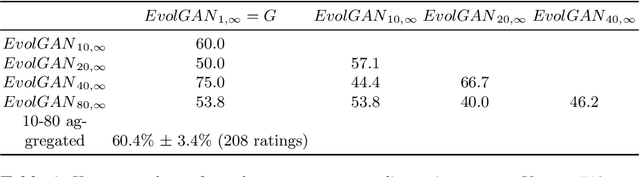
We propose to use a quality estimator and evolutionary methods to search the latent space of generative adversarial networks trained on small, difficult datasets, or both. The new method leads to the generation of significantly higher quality images while preserving the original generator's diversity. Human raters preferred an image from the new version with frequency 83.7pc for Cats, 74pc for FashionGen, 70.4pc for Horses, and 69.2pc for Artworks, and minor improvements for the already excellent GANs for faces. This approach applies to any quality scorer and GAN generator.