 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-Box Optimization Revisited: Improving Algorithm Selection Wizards through Massive Benchmarking
Oct 12, 2020


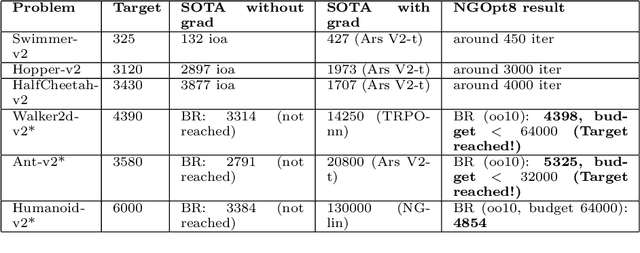
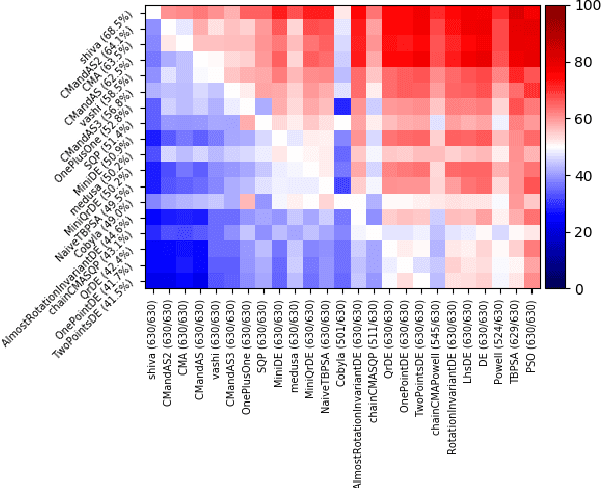
Existing studies in black-box optimization suffer from low generalizability, caused by a typically selective choice of problem instances used for training and testing different optimization algorithms. Among other issues, this practice promotes overfitting and poor-performing user guide-lines. To address this shortcoming, we propose in this work a benchmark suite which covers a broad range of black-box optimization problems, ranging from academic benchmarks to real-world optimization problems, from discrete over numerical to mixed-integer problems, from small to very large-scale problems, from noisy over dynamic to static problems, etc. We demonstrate the advantages of such a broad collection by deriving from it NGOpt8, a general-purpose algorithm selection wizard. Using three different types of algorithm selection techniques, NGOpt8 achieves competitive performance on all benchmark suites. It significantly outperforms previous state of the art on some of them, including the MuJoCo collection,YABBOB, and LSGO. A single algorithm therefore performed best on these three important benchmarks, without any task-specific parametrization. The benchmark collection, the wizard, its low-level solvers, as well as all experimental data are fully reproducible and open source. They are made available as a fork of Nevergrad, termed OptimSuite.
EvolGAN: Evolutionary Generative Adversarial Networks
Sep 28, 2020

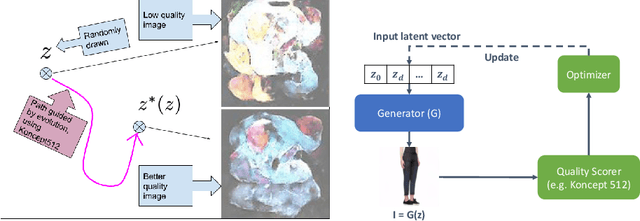
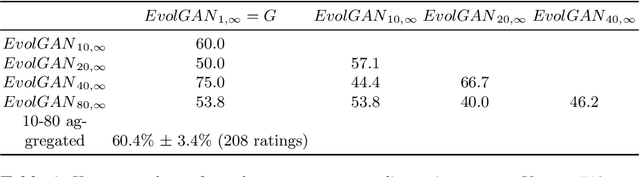
We propose to use a quality estimator and evolutionary methods to search the latent space of generative adversarial networks trained on small, difficult datasets, or both. The new method leads to the generation of significantly higher quality images while preserving the original generator's diversity. Human raters preferred an image from the new version with frequency 83.7pc for Cats, 74pc for FashionGen, 70.4pc for Horses, and 69.2pc for Artworks, and minor improvements for the already excellent GANs for faces. This approach applies to any quality scorer and GAN generator.
Proving $μ>1$
May 13, 2020

Choosing the right selection rate is a long standing issue in evolutionary computation. In the continuous unconstrained case, we prove mathematically that $\mu=1$ leads to a sub-optimal simple regret in the case of the sphere function. We provide a theoretically-based selection rate $\mu/\lambda$ that leads to better convergence rates. With our choice of selection rate, we get a provable regret of order $O(\lambda^{-1})$ which has to be compared with $O(\lambda^{-2/d})$ in the case where $\mu=1$. We complete our study with experiments to confirm our theoretical claims.
Versatile Black-Box Optimization
Apr 29, 2020


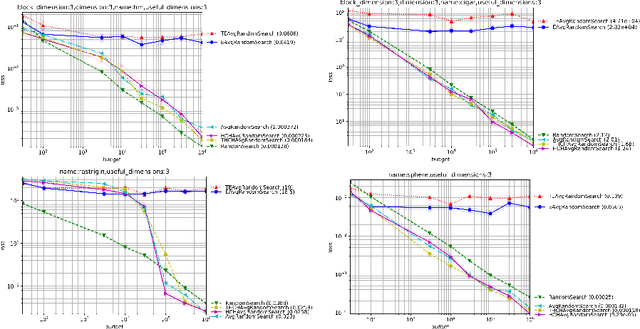
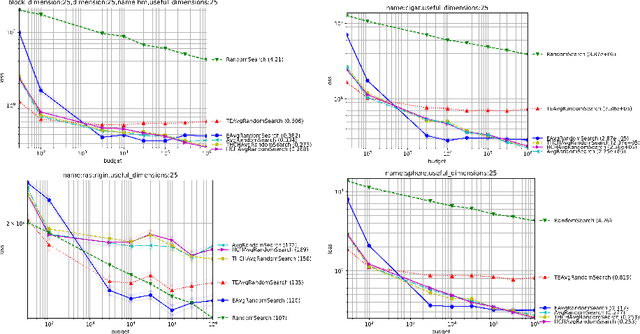
Choosing automatically the right algorithm using problem descriptors is a classical component of combinatorial optimization. It is also a good tool for making evolutionary algorithms fast, robust and versatile. We present Shiwa, an algorithm good at both discrete and continuous, noisy and noise-free, sequential and parallel, black-box optimization. Our algorithm is experimentally compared to competitors on YABBOB, a BBOB comparable testbed, and on some variants of it, and then validated on several real world testbeds.
Variance Reduction for Better Sampling in Continuous Domains
Apr 24, 2020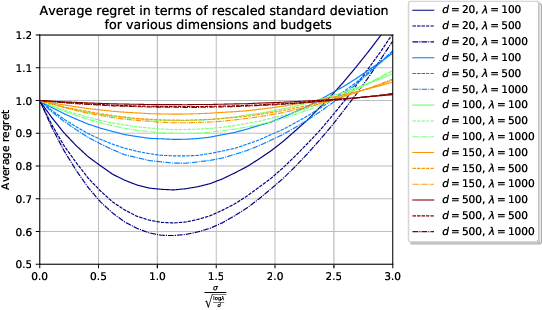



Design of experiments, random search, initialization of population-based methods, or sampling inside an epoch of an evolutionary algorithm use a sample drawn according to some probability distribution for approximating the location of an optimum. Recent papers have shown that the optimal search distribution, used for the sampling, might be more peaked around the center of the distribution than the prior distribution modelling our uncertainty about the location of the optimum. We confirm this statement, provide explicit values for this reshaping of the search distribution depending on the population size $\lambda$ and the dimension $d$, and validate our results experimentally.
Polygames: Improved Zero Learning
Jan 27, 2020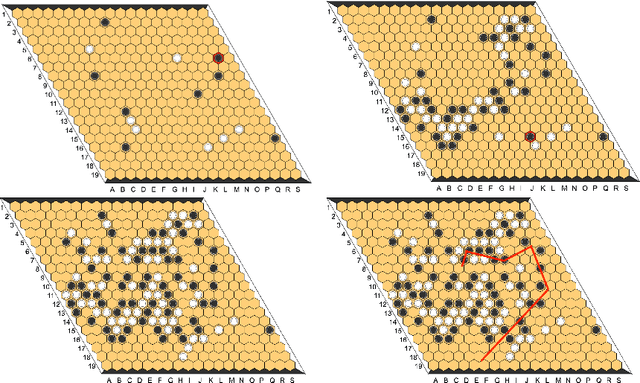
Since DeepMind's AlphaZero, Zero learning quickly became the state-of-the-art method for many board games. It can be improved using a fully convolutional structure (no fully connected layer). Using such an architecture plus global pooling, we can create bots independent of the board size. The training can be made more robust by keeping track of the best checkpoints during the training and by training against them. Using these features, we release Polygames, our framework for Zero learning, with its library of games and its checkpoints. We won against strong humans at the game of Hex in 19x19, which was often said to be untractable for zero learning; and in Havannah. We also won several first places at the TAAI competitions.
Robust Sparse Blind Source Separation
Apr 25, 2016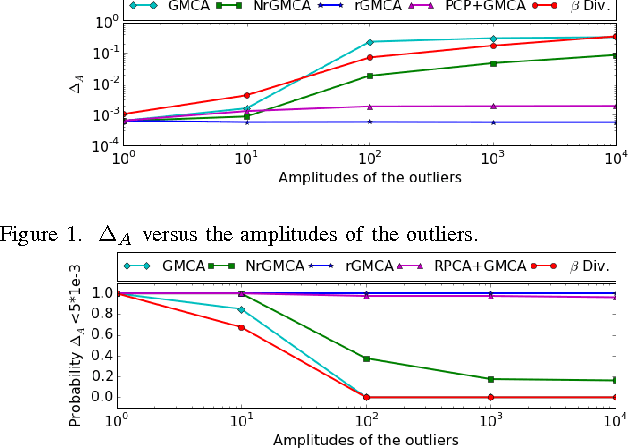
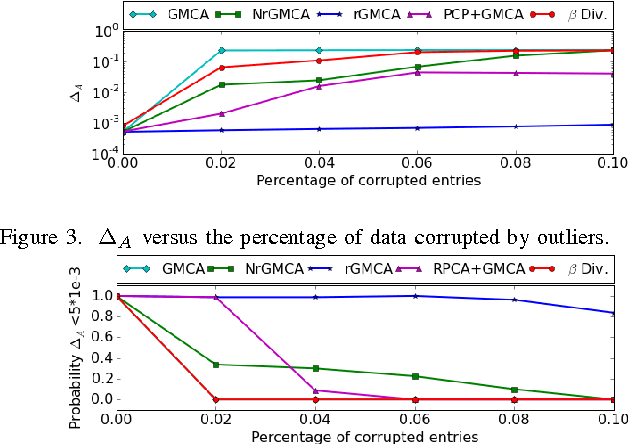
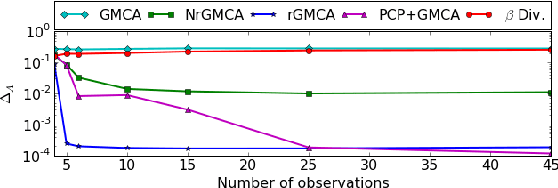
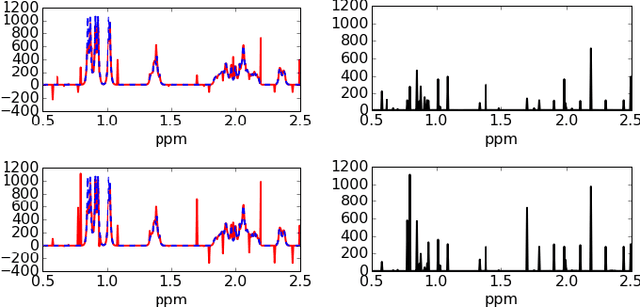
Blind Source Separation is a widely used technique to analyze multichannel data. In many real-world applications, its results can be significantly hampered by the presence of unknown outliers. In this paper, a novel algorithm coined rGMCA (robust Generalized Morphological Component Analysis) is introduced to retrieve sparse sources in the presence of outliers. It explicitly estimates the sources, the mixing matrix, and the outliers. It also takes advantage of the estimation of the outliers to further implement a weighting scheme, which provides a highly robust separation procedure. Numerical experiments demonstrate the efficiency of rGMCA to estimate the mixing matrix in comparison with standard BSS techniques.
Sparsity and adaptivity for the blind separation of partially correlated sources
Dec 09, 2014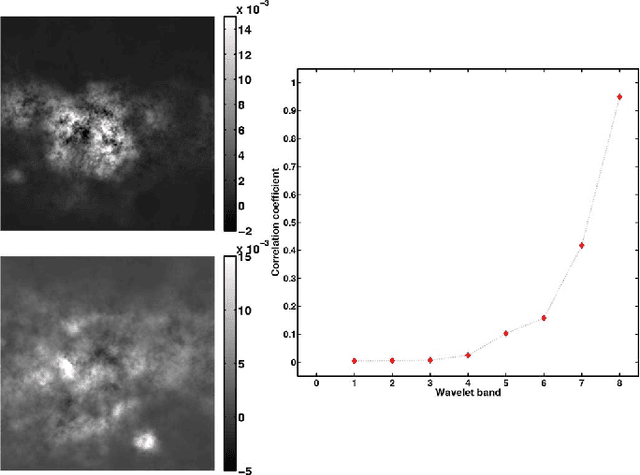
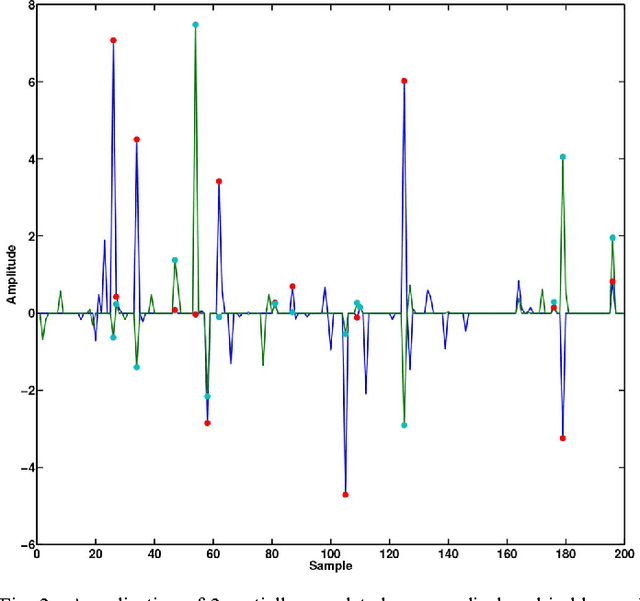
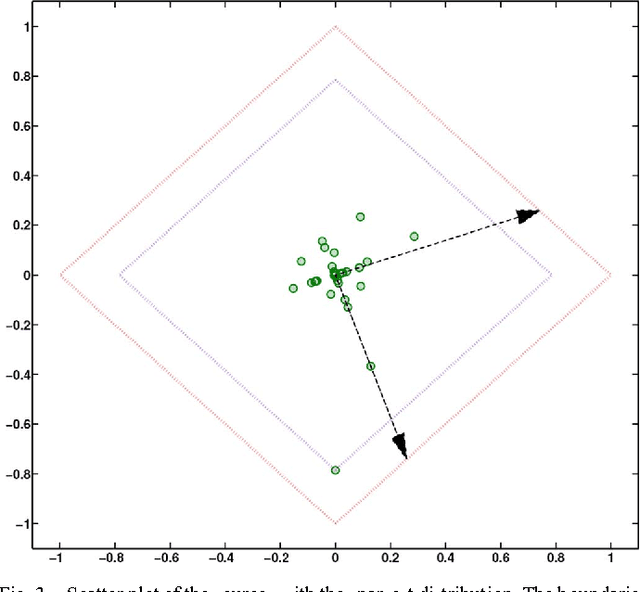
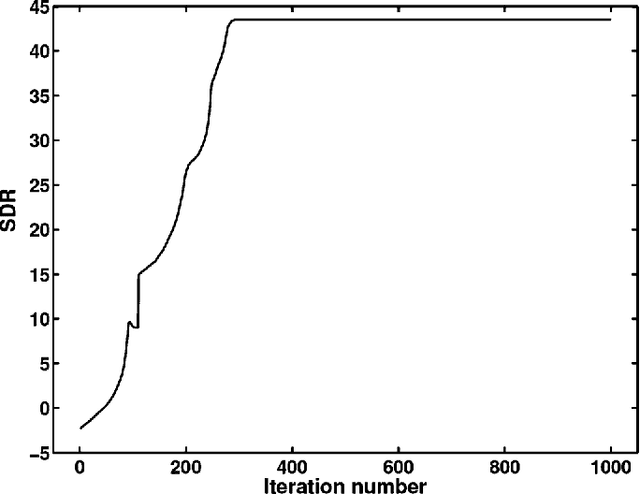
Blind source separation (BSS) is a very popular technique to analyze multichannel data. In this context, the data are modeled as the linear combination of sources to be retrieved. For that purpose, standard BSS methods all rely on some discrimination principle, whether it is statistical independence or morphological diversity, to distinguish between the sources. However, dealing with real-world data reveals that such assumptions are rarely valid in practice: the signals of interest are more likely partially correlated, which generally hampers the performances of standard BSS methods. In this article, we introduce a novel sparsity-enforcing BSS method coined Adaptive Morphological Component Analysis (AMCA), which is designed to retrieve sparse and partially correlated sources. More precisely, it makes profit of an adaptive re-weighting scheme to favor/penalize samples based on their level of correlation. Extensive numerical experiments have been carried out which show that the proposed method is robust to the partial correlation of sources while standard BSS techniques fail. The AMCA algorithm is evaluated in the field of astrophysics for the separation of physical components from microwave data.