 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Policy Search for Multi-agent Collaboration with Imperfect Information
Aug 24, 2020

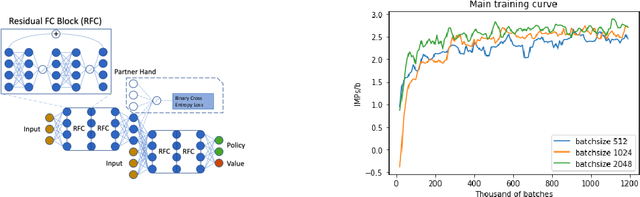

To learn good joint policies for multi-agent collaboration with imperfect information remains a fundamental challenge. While for two-player zero-sum games, coordinate-ascent approaches (optimizing one agent's policy at a time, e.g., self-play) work with guarantees, in multi-agent cooperative setting they often converge to sub-optimal Nash equilibrium. On the other hand, directly modeling joint policy changes in imperfect information game is nontrivial due to complicated interplay of policies (e.g., upstream updates affect downstream state reachability). In this paper, we show global changes of game values can be decomposed to policy changes localized at each information set, with a novel term named policy-change density. Based on this, we propose Joint Policy Search(JPS) that iteratively improves joint policies of collaborative agents in imperfect information games, without re-evaluating the entire game. On multi-agent collaborative tabular games, JPS is proven to never worsen performance and can improve solutions provided by unilateral approaches (e.g, CFR), outperforming algorithms designed for collaborative policy learning (e.g. BAD). Furthermore, for real-world games, JPS has an online form that naturally links with gradient updates. We test it to Contract Bridge, a 4-player imperfect-information game where a team of $2$ collaborates to compete against the other. In its bidding phase, players bid in turn to find a good contract through a limited information channel. Based on a strong baseline agent that bids competitive bridge purely through domain-agnostic self-play, JPS improves collaboration of team players and outperforms WBridge5, a championship-winning software, by $+0.63$ IMPs (International Matching Points) per board over 1k games, substantially better than previous SoTA ($+0.41$ IMPs/b) under Double-Dummy evaluation.
Combining Deep Reinforcement Learning and Search for Imperfect-Information Games
Jul 27, 2020
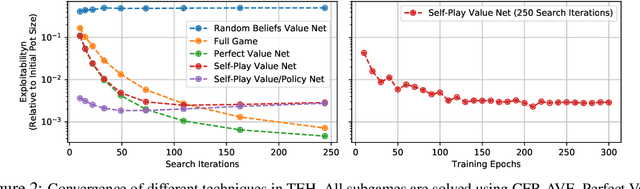
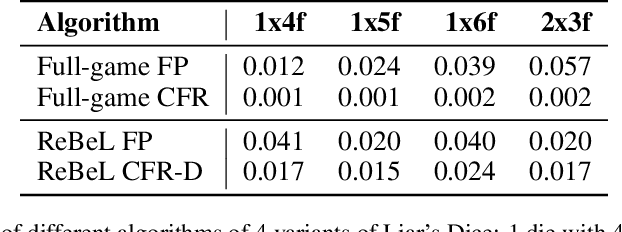
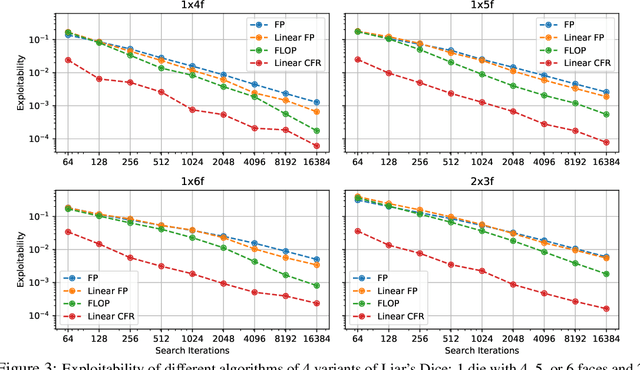
The combination of deep reinforcement learning and search at both training and test time is a powerful paradigm that has led to a number of a successes in single-agent settings and perfect-information games, best exemplified by the success of AlphaZero. However, algorithms of this form have been unable to cope with imperfect-information games. This paper presents ReBeL, a general framework for self-play reinforcement learning and search for imperfect-information games. In the simpler setting of perfect-information games, ReBeL reduces to an algorithm similar to AlphaZero. Results show ReBeL leads to low exploitability in benchmark imperfect-information games and achieves superhuman performance in heads-up no-limit Texas hold'em poker, while using far less domain knowledge than any prior poker AI. We also prove that ReBeL converges to a Nash equilibrium in two-player zero-sum games in tabular settings.
Polygames: Improved Zero Learning
Jan 27, 2020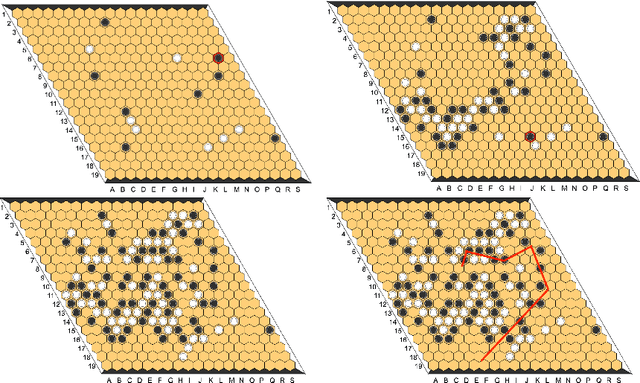
Since DeepMind's AlphaZero, Zero learning quickly became the state-of-the-art method for many board games. It can be improved using a fully convolutional structure (no fully connected layer). Using such an architecture plus global pooling, we can create bots independent of the board size. The training can be made more robust by keeping track of the best checkpoints during the training and by training against them. Using these features, we release Polygames, our framework for Zero learning, with its library of games and its checkpoints. We won against strong humans at the game of Hex in 19x19, which was often said to be untractable for zero learning; and in Havannah. We also won several first places at the TAAI competitions.
Hierarchical Decision Making by Generating and Following Natural Language Instructions
Jun 12, 2019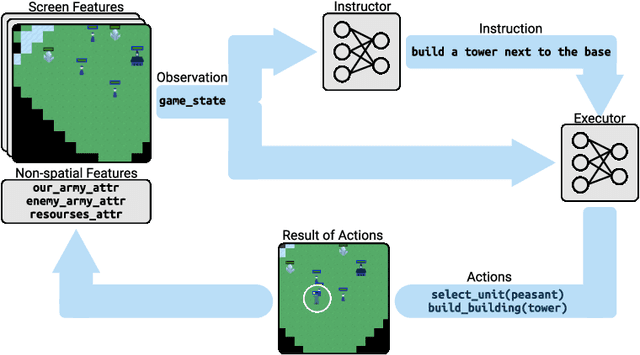

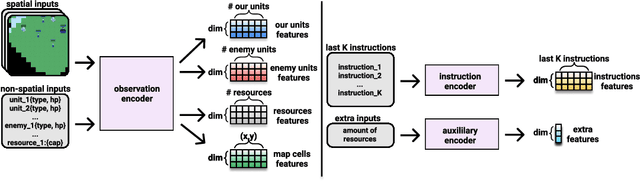
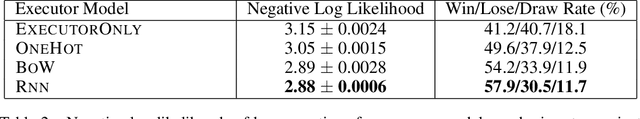
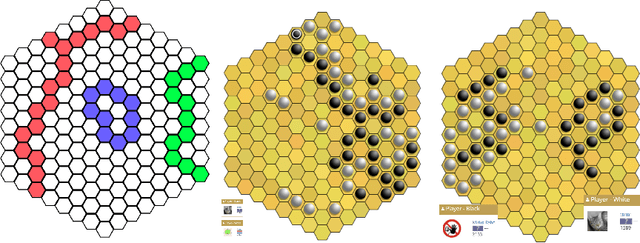
We explore using latent natural language instructions as an expressive and compositional representation of complex actions for hierarchical decision making. Rather than directly selecting micro-actions, our agent first generates a latent plan in natural language, which is then executed by a separate model. We introduce a challenging real-time strategy game environment in which the actions of a large number of units must be coordinated across long time scales. We gather a dataset of 76 thousand pairs of instructions and executions from human play, and train instructor and executor models. Experiments show that models using natural language as a latent variable significantly outperform models that directly imitate human actions. The compositional structure of language proves crucial to its effectiveness for action representation. We also release our code, models and data.
Luck Matters: Understanding Training Dynamics of Deep ReLU Networks
Jun 10, 2019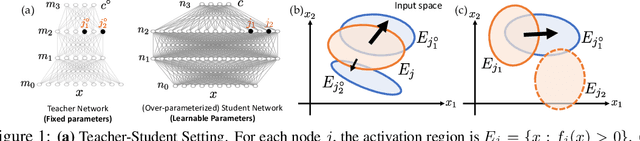

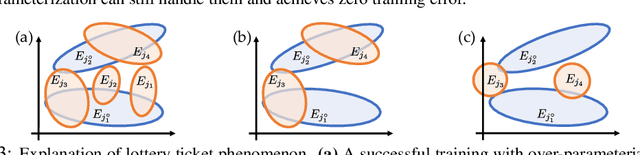
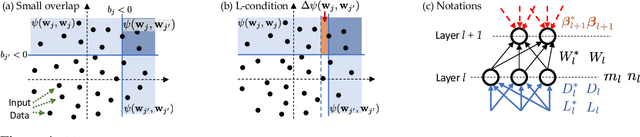
We analyze the dynamics of training deep ReLU networks and their implications on generalization capability. Using a teacher-student setting, we discovered a novel relationship between the gradient received by hidden student nodes and the activations of teacher nodes for deep ReLU networks. With this relationship and the assumption of small overlapping teacher node activations, we prove that (1) student nodes whose weights are initialized to be close to teacher nodes converge to them at a faster rate, and (2) in over-parameterized regimes and 2-layer case, while a small set of lucky nodes do converge to the teacher nodes, the fan-out weights of other nodes converge to zero. This framework provides insight into multiple puzzling phenomena in deep learning like over-parameterization, implicit regularization, lottery tickets, etc. We verify our assumption by showing that the majority of BatchNorm biases of pre-trained VGG11/16 models are negative. Experiments on (1) random deep teacher networks with Gaussian inputs, (2) teacher network pre-trained on CIFAR-10 and (3) extensive ablation studies validate our multiple theoretical predictions.
ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero
Feb 13, 2019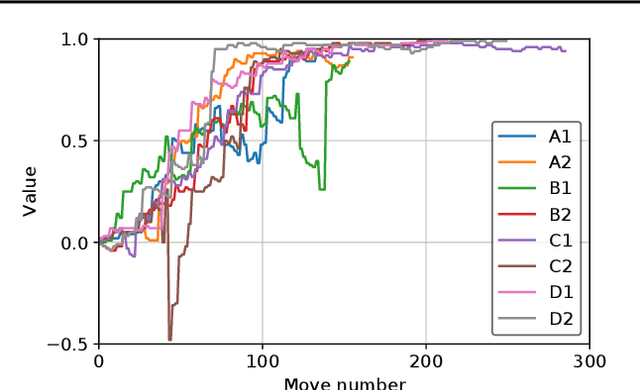

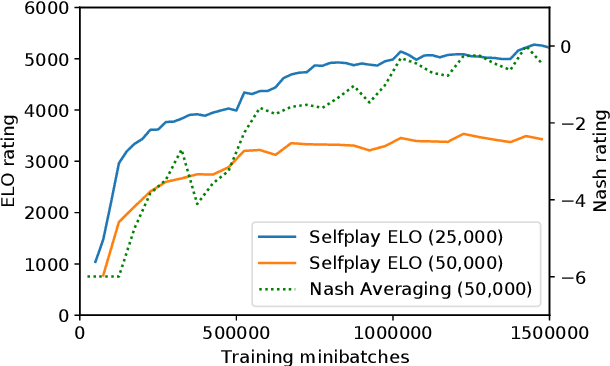
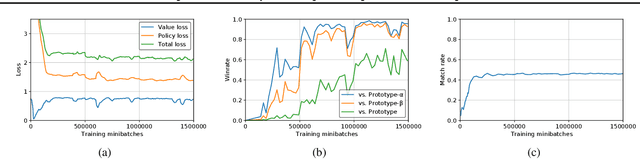
The AlphaGo, AlphaGo Zero, and AlphaZero series of algorithms are a remarkable demonstration of deep reinforcement learning's capabilities, achieving superhuman performance in the complex game of Go with progressively increasing autonomy. However, many obstacles remain in the understanding of and usability of these promising approaches by the research community. Toward elucidating unresolved mysteries and facilitating future research, we propose ELF OpenGo, an open-source reimplementation of the AlphaZero algorithm. ELF OpenGo is the first open-source Go AI to convincingly demonstrate superhuman performance with a perfect (20:0) record against global top professionals. We apply ELF OpenGo to conduct extensive ablation studies, and to identify and analyze numerous interesting phenomena in both the model training and in the gameplay inference procedures. Our code, models, selfplay datasets, and auxiliary data are publicly available.
ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games
Nov 10, 2017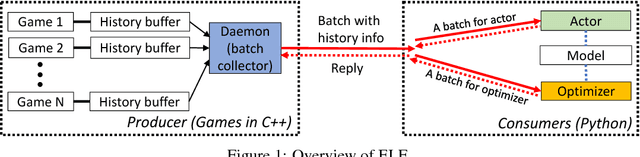

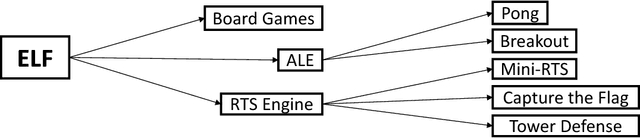
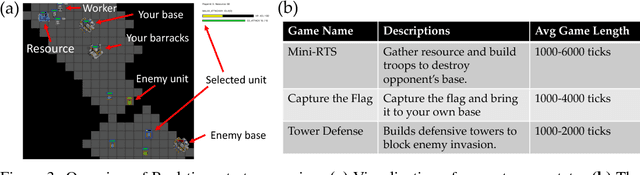
In this paper, we propose ELF, an Extensive, Lightweight and Flexible platform for fundamental reinforcement learning research. Using ELF, we implement a highly customizable real-time strategy (RTS) engine with three game environments (Mini-RTS, Capture the Flag and Tower Defense). Mini-RTS, as a miniature version of StarCraft, captures key game dynamics and runs at 40K frame-per-second (FPS) per core on a Macbook Pro notebook. When coupled with modern reinforcement learning methods, the system can train a full-game bot against built-in AIs end-to-end in one day with 6 CPUs and 1 GPU. In addition, our platform is flexible in terms of environment-agent communication topologies, choices of RL methods, changes in game parameters, and can host existing C/C++-based game environments like Arcade Learning Environment. Using ELF, we thoroughly explore training parameters and show that a network with Leaky ReLU and Batch Normalization coupled with long-horizon training and progressive curriculum beats the rule-based built-in AI more than $70\%$ of the time in the full game of Mini-RTS. Strong performance is also achieved on the other two games. In game replays, we show our agents learn interesting strategies. ELF, along with its RL platform, is open-sourced at https://github.com/facebookresearch/ELF.