 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAUDI: A Neural Architect for Immersive 3D Scene Generation
Jul 27, 2022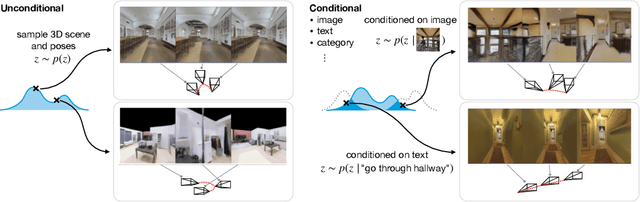
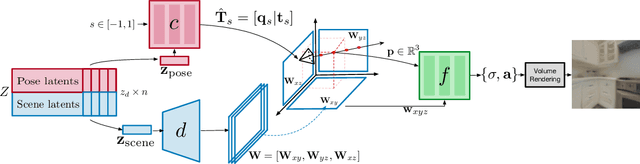

We introduce GAUDI, a generative model capable of capturing the distribution of complex and realistic 3D scenes that can be rendered immersively from a moving camera. We tackle this challenging problem with a scalable yet powerful approach, where we first optimize a latent representation that disentangles radiance fields and camera poses. This latent representation is then used to learn a generative model that enables both unconditional and conditional generation of 3D scenes. Our model generalizes previous works that focus on single objects by removing the assumption that the camera pose distribution can be shared across samples. We show that GAUDI obtains state-of-the-art performance in the unconditional generative setting across multiple datasets and allows for conditional generation of 3D scenes given conditioning variables like sparse image observations or text that describes the scene.
ARKitScenes -- A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Nov 17, 2021
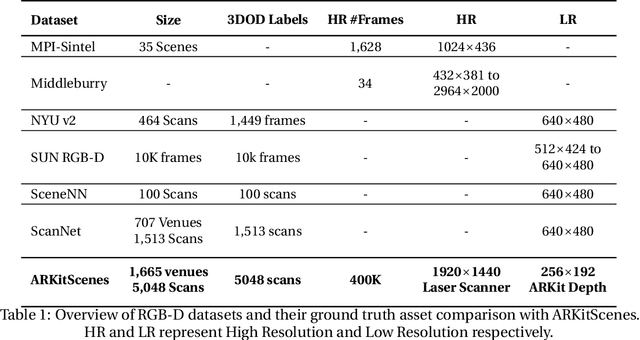

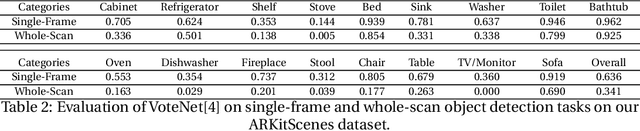
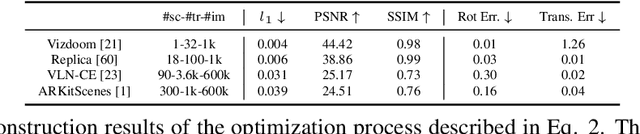
Scene understanding is an active research area. Commercial depth sensors, such as Kinect, have enabled the release of several RGB-D datasets over the past few years which spawned novel methods in 3D scene understanding. More recently with the launch of the LiDAR sensor in Apple's iPads and iPhones, high quality RGB-D data is accessible to millions of people on a device they commonly use. This opens a whole new era in scene understanding for the Computer Vision community as well as app developers. The fundamental research in scene understanding together with the advances in machine learning can now impact people's everyday experiences. However, transforming these scene understanding methods to real-world experiences requires additional innovation and development. In this paper we introduce ARKitScenes. It is not only the first RGB-D dataset that is captured with a now widely available depth sensor, but to our best knowledge, it also is the largest indoor scene understanding data released. In addition to the raw and processed data from the mobile device, ARKitScenes includes high resolution depth maps captured using a stationary laser scanner, as well as manually labeled 3D oriented bounding boxes for a large taxonomy of furniture. We further analyze the usefulness of the data for two downstream tasks: 3D object detection and color-guided depth upsampling. We demonstrate that our dataset can help push the boundaries of existing state-of-the-art methods and it introduces new challenges that better represent real-world scenarios.
ShapeAdv: Generating Shape-Aware Adversarial 3D Point Clouds
May 24, 2020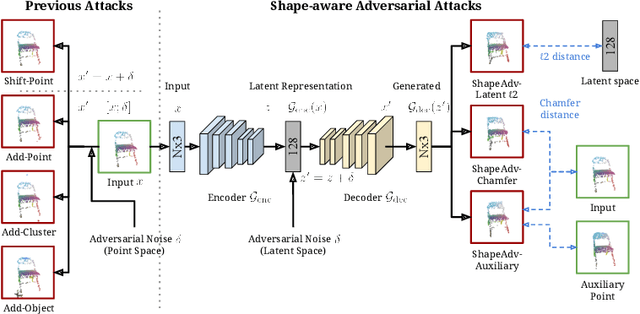
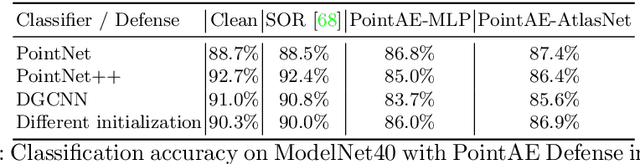
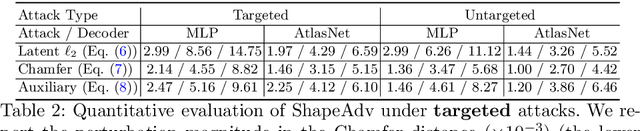
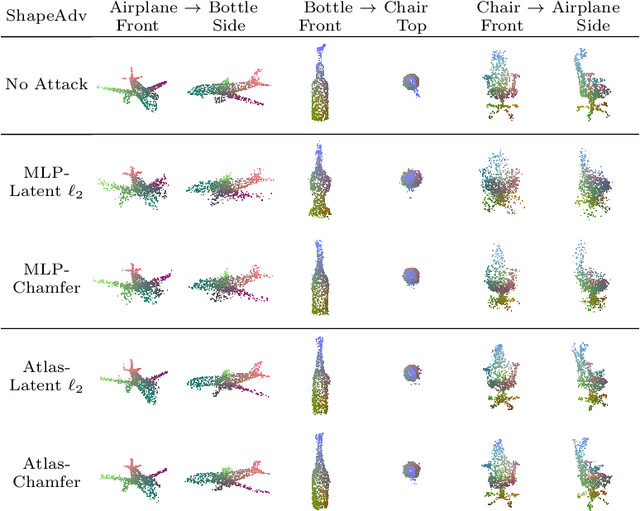
We introduce ShapeAdv, a novel framework to study shape-aware adversarial perturbations that reflect the underlying shape variations (e.g., geometric deformations and structural differences) in the 3D point cloud space. We develop shape-aware adversarial 3D point cloud attacks by leveraging the learned latent space of a point cloud auto-encoder where the adversarial noise is applied in the latent space. Specifically, we propose three different variants including an exemplar-based one by guiding the shape deformation with auxiliary data, such that the generated point cloud resembles the shape morphing between objects in the same category. Different from prior works, the resulting adversarial 3D point clouds reflect the shape variations in the 3D point cloud space while still being close to the original one. In addition, experimental evaluations on the ModelNet40 benchmark demonstrate that our adversaries are more difficult to defend with existing point cloud defense methods and exhibit a higher attack transferability across classifiers. Our shape-aware adversarial attacks are orthogonal to existing point cloud based attacks and shed light on the vulnerability of 3D deep neural networks.
Why Build an Assistant in Minecraft?
Jul 25, 2019In this document we describe a rationale for a research program aimed at building an open "assistant" in the game Minecraft, in order to make progress on the problems of natural language understanding and learning from dialogue.
CraftAssist: A Framework for Dialogue-enabled Interactive Agents
Jul 19, 2019
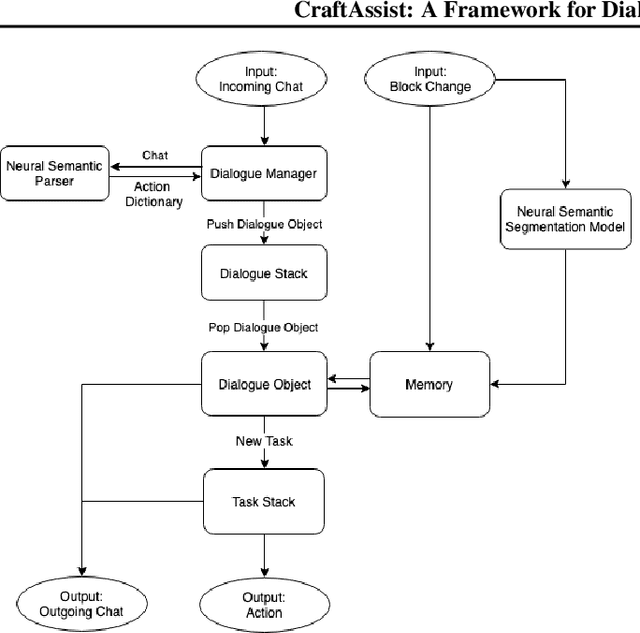

This paper describes an implementation of a bot assistant in Minecraft, and the tools and platform allowing players to interact with the bot and to record those interactions. The purpose of building such an assistant is to facilitate the study of agents that can complete tasks specified by dialogue, and eventually, to learn from dialogue interactions.
ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero
Feb 13, 2019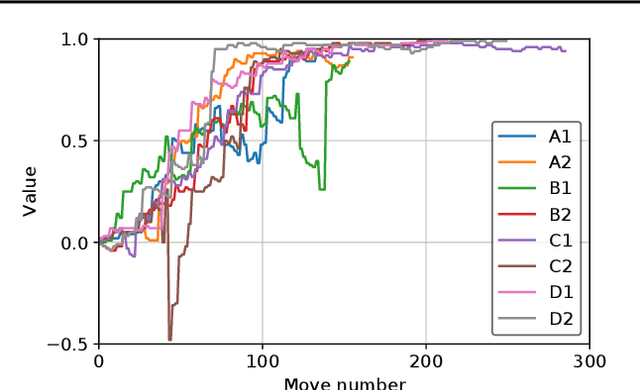

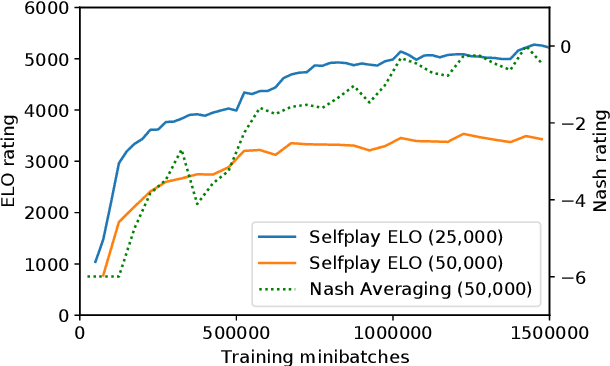
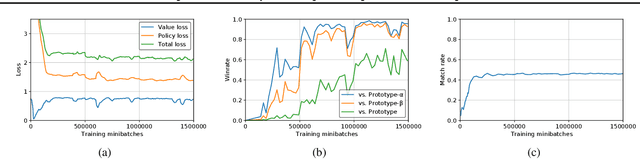
The AlphaGo, AlphaGo Zero, and AlphaZero series of algorithms are a remarkable demonstration of deep reinforcement learning's capabilities, achieving superhuman performance in the complex game of Go with progressively increasing autonomy. However, many obstacles remain in the understanding of and usability of these promising approaches by the research community. Toward elucidating unresolved mysteries and facilitating future research, we propose ELF OpenGo, an open-source reimplementation of the AlphaZero algorithm. ELF OpenGo is the first open-source Go AI to convincingly demonstrate superhuman performance with a perfect (20:0) record against global top professionals. We apply ELF OpenGo to conduct extensive ablation studies, and to identify and analyze numerous interesting phenomena in both the model training and in the gameplay inference procedures. Our code, models, selfplay datasets, and auxiliary data are publicly available.