 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARKitScenes -- A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Nov 17, 2021
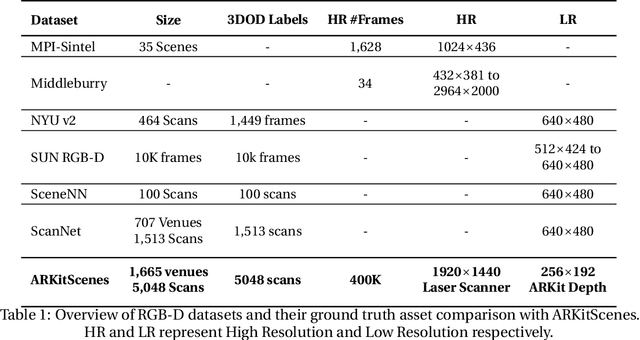

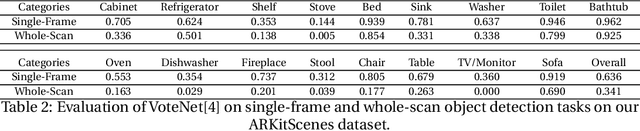
Scene understanding is an active research area. Commercial depth sensors, such as Kinect, have enabled the release of several RGB-D datasets over the past few years which spawned novel methods in 3D scene understanding. More recently with the launch of the LiDAR sensor in Apple's iPads and iPhones, high quality RGB-D data is accessible to millions of people on a device they commonly use. This opens a whole new era in scene understanding for the Computer Vision community as well as app developers. The fundamental research in scene understanding together with the advances in machine learning can now impact people's everyday experiences. However, transforming these scene understanding methods to real-world experiences requires additional innovation and development. In this paper we introduce ARKitScenes. It is not only the first RGB-D dataset that is captured with a now widely available depth sensor, but to our best knowledge, it also is the largest indoor scene understanding data released. In addition to the raw and processed data from the mobile device, ARKitScenes includes high resolution depth maps captured using a stationary laser scanner, as well as manually labeled 3D oriented bounding boxes for a large taxonomy of furniture. We further analyze the usefulness of the data for two downstream tasks: 3D object detection and color-guided depth upsampling. We demonstrate that our dataset can help push the boundaries of existing state-of-the-art methods and it introduces new challenges that better represent real-world scenarios.
Reconstructing Training Data from Diverse ML Models by Ensemble Inversion
Nov 05, 2021
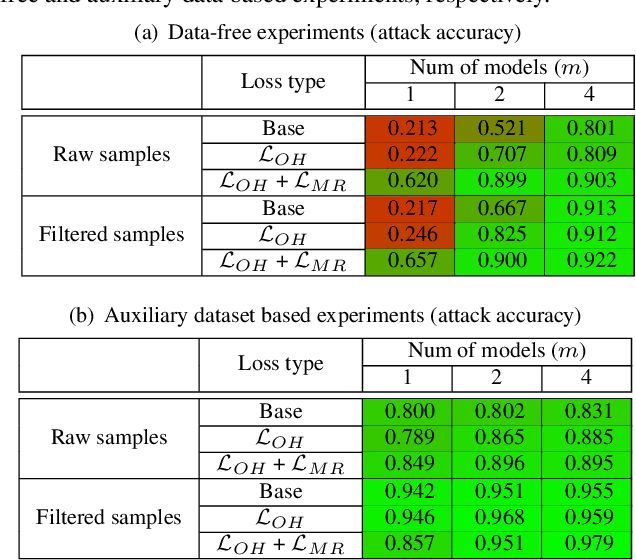

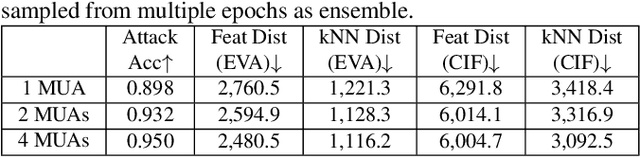
Model Inversion (MI), in which an adversary abuses access to a trained Machine Learning (ML) model attempting to infer sensitive information about its original training data, has attracted increasing research attention. During MI, the trained model under attack (MUA) is usually frozen and used to guide the training of a generator, such as a Generative Adversarial Network (GAN), to reconstruct the distribution of the original training data of that model. This might cause leakage of original training samples, and if successful, the privacy of dataset subjects will be at risk if the training data contains Personally Identifiable Information (PII). Therefore, an in-depth investigation of the potentials of MI techniques is crucial for the development of corresponding defense techniques. High-quality reconstruction of training data based on a single model is challenging. However, existing MI literature does not explore targeting multiple models jointly, which may provide additional information and diverse perspectives to the adversary. We propose the ensemble inversion technique that estimates the distribution of original training data by training a generator constrained by an ensemble (or set) of trained models with shared subjects or entities. This technique leads to noticeable improvements of the quality of the generated samples with distinguishable features of the dataset entities compared to MI of a single ML model. We achieve high quality results without any dataset and show how utilizing an auxiliary dataset that's similar to the presumed training data improves the results. The impact of model diversity in the ensemble is thoroughly investigated and additional constraints are utilized to encourage sharp predictions and high activations for the reconstructed samples, leading to more accurate reconstruction of training images.
HDR Environment Map Estimation for Real-Time Augmented Reality
Nov 21, 2020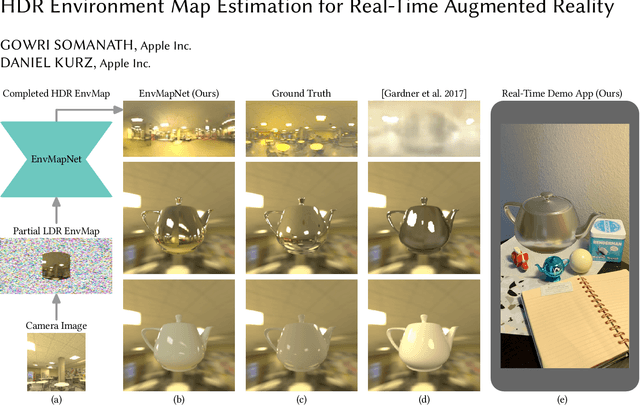



We present a method to estimate an HDR environment map from a narrow field-of-view LDR camera image in real-time. This enables perceptually appealing reflections and shading on virtual objects of any material finish, from mirror to diffuse, rendered into a real physical environment using augmented reality. Our method is based on our efficient convolutional neural network architecture, EnvMapNet, trained end-to-end with two novel losses, ProjectionLoss for the generated image, and ClusterLoss for adversarial training. Through qualitative and quantitative comparison to state-of-the-art methods, we demonstrate that our algorithm reduces the directional error of estimated light sources by more than 50%, and achieves 3.7 times lower Frechet Inception Distance (FID). We further showcase a mobile application that is able to run our neural network model in under 9 ms on an iPhone XS, and render in real-time, visually coherent virtual objects in previously unseen real-world environments.