 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARKitScenes -- A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
Nov 17, 2021

Scene understanding is an active research area. Commercial depth sensors, such as Kinect, have enabled the release of several RGB-D datasets over the past few years which spawned novel methods in 3D scene understanding. More recently with the launch of the LiDAR sensor in Apple's iPads and iPhones, high quality RGB-D data is accessible to millions of people on a device they commonly use. This opens a whole new era in scene understanding for the Computer Vision community as well as app developers. The fundamental research in scene understanding together with the advances in machine learning can now impact people's everyday experiences. However, transforming these scene understanding methods to real-world experiences requires additional innovation and development. In this paper we introduce ARKitScenes. It is not only the first RGB-D dataset that is captured with a now widely available depth sensor, but to our best knowledge, it also is the largest indoor scene understanding data released. In addition to the raw and processed data from the mobile device, ARKitScenes includes high resolution depth maps captured using a stationary laser scanner, as well as manually labeled 3D oriented bounding boxes for a large taxonomy of furniture. We further analyze the usefulness of the data for two downstream tasks: 3D object detection and color-guided depth upsampling. We demonstrate that our dataset can help push the boundaries of existing state-of-the-art methods and it introduces new challenges that better represent real-world scenarios.
GMM-Based Generative Adversarial Encoder Learning
Dec 08, 2020
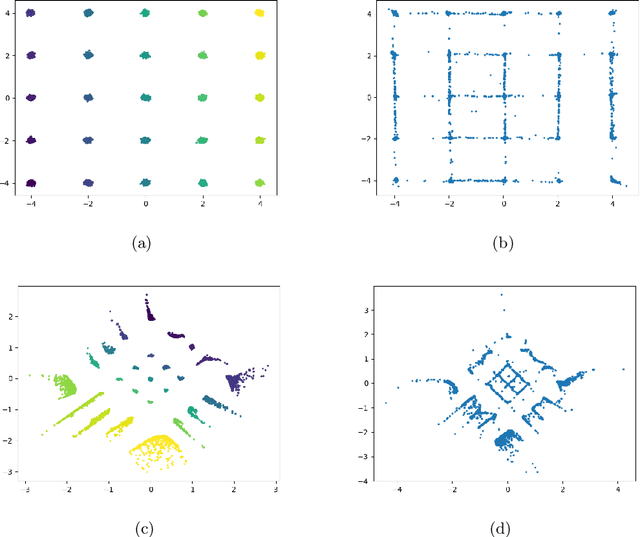

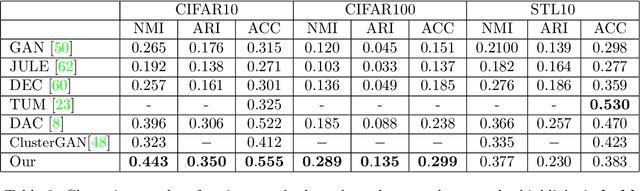
While GAN is a powerful model for generating images, its inability to infer a latent space directly limits its use in applications requiring an encoder. Our paper presents a simple architectural setup that combines the generative capabilities of GAN with an encoder. We accomplish this by combining the encoder with the discriminator using shared weights, then training them simultaneously using a new loss term. We model the output of the encoder latent space via a GMM, which leads to both good clustering using this latent space and improved image generation by the GAN. Our framework is generic and can be easily plugged into any GAN strategy. In particular, we demonstrate it both with Vanilla GAN and Wasserstein GAN, where in both it leads to an improvement in the generated images in terms of both the IS and FID scores. Moreover, we show that our encoder learns a meaningful representation as its clustering results are competitive with the current GAN-based state-of-the-art in clustering.