 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIMP: Contrastive Language-Image Mamba Pretraining
Jan 11, 2026Contrastive Language-Image Pre-training (CLIP) relies on Vision Transformers whose attention mechanism is susceptible to spurious correlations, and scales quadratically with resolution. To address these limitations, We present CLIMP, the first fully Mamba-based contrastive vision-language model that replaces both the vision and text encoders with Mamba. The new architecture encodes sequential structure in both vision and language, with VMamba capturing visual spatial inductive biases, reducing reliance on spurious correlations and producing an embedding space favorable for cross-modal retrieval and out-of-distribution robustness-surpassing OpenAI's CLIP-ViT-B by 7.5% on ImageNet-O. CLIMP naturally supports variable input resolutions without positional encoding interpolation or specialized training, achieving up to 6.6% higher retrieval accuracy at 16x training resolution while using 5x less memory and 1.8x fewer FLOPs. The autoregressive text encoder further overcomes CLIP's fixed context limitation, enabling dense captioning retrieval. Our findings suggest that Mamba exhibits advantageous properties for vision-language learning, making it a compelling alternative to Transformer-based CLIP.
DIP-GS: Deep Image Prior For Gaussian Splatting Sparse View Recovery
Aug 10, 20253D Gaussian Splatting (3DGS) is a leading 3D scene reconstruction method, obtaining high-quality reconstruction with real-time rendering runtime performance. The main idea behind 3DGS is to represent the scene as a collection of 3D gaussians, while learning their parameters to fit the given views of the scene. While achieving superior performance in the presence of many views, 3DGS struggles with sparse view reconstruction, where the input views are sparse and do not fully cover the scene and have low overlaps. In this paper, we propose DIP-GS, a Deep Image Prior (DIP) 3DGS representation. By using the DIP prior, which utilizes internal structure and patterns, with coarse-to-fine manner, DIP-based 3DGS can operate in scenarios where vanilla 3DGS fails, such as sparse view recovery. Note that our approach does not use any pre-trained models such as generative models and depth estimation, but rather relies only on the input frames. Among such methods, DIP-GS obtains state-of-the-art (SOTA) competitive results on various sparse-view reconstruction tasks, demonstrating its capabilities.
ConlangCrafter: Constructing Languages with a Multi-Hop LLM Pipeline
Aug 08, 2025Constructed languages (conlangs) such as Esperanto and Quenya have played diverse roles in art, philosophy, and international communication. Meanwhile, large-scale foundation models have revolutionized creative generation in text, images, and beyond. In this work, we leverage modern LLMs as computational creativity aids for end-to-end conlang creation. We introduce ConlangCrafter, a multi-hop pipeline that decomposes language design into modular stages -- phonology, morphology, syntax, lexicon generation, and translation. At each stage, our method leverages LLMs' meta-linguistic reasoning capabilities, injecting randomness to encourage diversity and leveraging self-refinement feedback to encourage consistency in the emerging language description. We evaluate ConlangCrafter on metrics measuring coherence and typological diversity, demonstrating its ability to produce coherent and varied conlangs without human linguistic expertise.
Mamba Knockout for Unraveling Factual Information Flow
May 30, 2025This paper investigates the flow of factual information in Mamba State-Space Model (SSM)-based language models. We rely on theoretical and empirical connections to Transformer-based architectures and their attention mechanisms. Exploiting this relationship, we adapt attentional interpretability techniques originally developed for Transformers--specifically, the Attention Knockout methodology--to both Mamba-1 and Mamba-2. Using them we trace how information is transmitted and localized across tokens and layers, revealing patterns of subject-token information emergence and layer-wise dynamics. Notably, some phenomena vary between mamba models and Transformer based models, while others appear universally across all models inspected--hinting that these may be inherent to LLMs in general. By further leveraging Mamba's structured factorization, we disentangle how distinct "features" either enable token-to-token information exchange or enrich individual tokens, thus offering a unified lens to understand Mamba internal operations.
Revisiting Glorot Initialization for Long-Range Linear Recurrences
May 26, 2025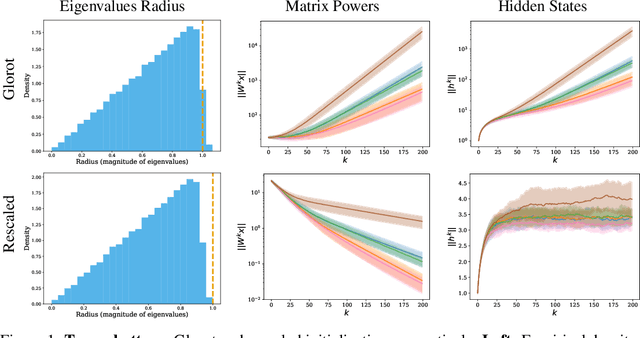
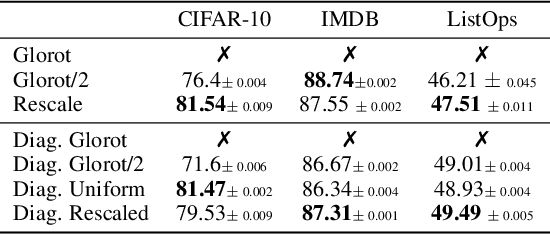
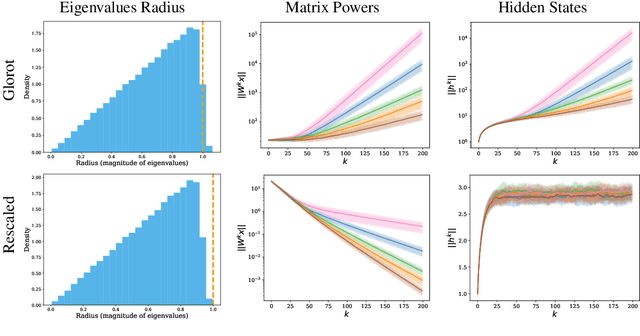
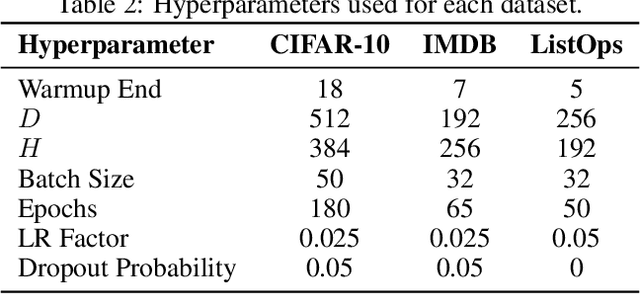
Proper initialization is critical for Recurrent Neural Networks (RNNs), particularly in long-range reasoning tasks, where repeated application of the same weight matrix can cause vanishing or exploding signals. A common baseline for linear recurrences is Glorot initialization, designed to ensure stable signal propagation--but derived under the infinite-width, fixed-length regime--an unrealistic setting for RNNs processing long sequences. In this work, we show that Glorot initialization is in fact unstable: small positive deviations in the spectral radius are amplified through time and cause the hidden state to explode. Our theoretical analysis demonstrates that sequences of length $t = O(\sqrt{n})$, where $n$ is the hidden width, are sufficient to induce instability. To address this, we propose a simple, dimension-aware rescaling of Glorot that shifts the spectral radius slightly below one, preventing rapid signal explosion or decay. These results suggest that standard initialization schemes may break down in the long-sequence regime, motivating a separate line of theory for stable recurrent initialization.
Overflow Prevention Enhances Long-Context Recurrent LLMs
May 12, 2025A recent trend in LLMs is developing recurrent sub-quadratic models that improve long-context processing efficiency. We investigate leading large long-context models, focusing on how their fixed-size recurrent memory affects their performance. Our experiments reveal that, even when these models are trained for extended contexts, their use of long contexts remains underutilized. Specifically, we demonstrate that a chunk-based inference procedure, which identifies and processes only the most relevant portion of the input can mitigate recurrent memory failures and be effective for many long-context tasks: On LongBench, our method improves the overall performance of Falcon3-Mamba-Inst-7B by 14%, Falcon-Mamba-Inst-7B by 28%, RecurrentGemma-IT-9B by 50%, and RWKV6-Finch-7B by 51%. Surprisingly, this simple approach also leads to state-of-the-art results in the challenging LongBench v2 benchmark, showing competitive performance with equivalent size Transformers. Furthermore, our findings raise questions about whether recurrent models genuinely exploit long-range dependencies, as our single-chunk strategy delivers stronger performance - even in tasks that presumably require cross-context relations.
ZOQO: Zero-Order Quantized Optimization
Jan 12, 2025


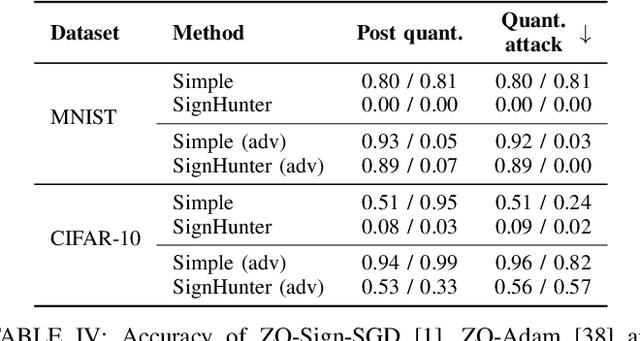
The increasing computational and memory demands in deep learning present significant challenges, especially in resource-constrained environments. We introduce a zero-order quantized optimization (ZOQO) method designed for training models with quantized parameters and operations. Our approach leverages zero-order approximations of the gradient sign and adapts the learning process to maintain the parameters' quantization without the need for full-precision gradient calculations. We demonstrate the effectiveness of ZOQO through experiments in fine-tuning of large language models and black-box adversarial attacks. Despite the limitations of zero-order and quantized operations training, our method achieves competitive performance compared to full-precision methods, highlighting its potential for low-resource environments.
Performance Gap in Entity Knowledge Extraction Across Modalities in Vision Language Models
Dec 18, 2024



Vision-language models (VLMs) excel at extracting and reasoning about information from images. Yet, their capacity to leverage internal knowledge about specific entities remains underexplored. This work investigates the disparity in model performance when answering factual questions about an entity described in text versus depicted in an image. Our results reveal a significant accuracy drop --averaging 19%-- when the entity is presented visually instead of textually. We hypothesize that this decline arises from limitations in how information flows from image tokens to query tokens. We use mechanistic interpretability tools to reveal that, although image tokens are preprocessed by the vision encoder, meaningful information flow from these tokens occurs only in the much deeper layers. Furthermore, critical image processing happens in the language model's middle layers, allowing few layers for consecutive reasoning, highlighting a potential inefficiency in how the model utilizes its layers for reasoning. These insights shed light on the internal mechanics of VLMs and offer pathways for enhancing their reasoning capabilities.
Teaching VLMs to Localize Specific Objects from In-context Examples
Nov 20, 2024



Vision-Language Models (VLMs) have shown remarkable capabilities across diverse visual tasks, including image recognition, video understanding, and Visual Question Answering (VQA) when explicitly trained for these tasks. Despite these advances, we find that current VLMs lack a fundamental cognitive ability: learning to localize objects in a scene by taking into account the context. In this work, we focus on the task of few-shot personalized localization, where a model is given a small set of annotated images (in-context examples) -- each with a category label and bounding box -- and is tasked with localizing the same object type in a query image. To provoke personalized localization abilities in models, we present a data-centric solution that fine-tunes them using carefully curated data from video object tracking datasets. By leveraging sequences of frames tracking the same object across multiple shots, we simulate instruction-tuning dialogues that promote context awareness. To reinforce this, we introduce a novel regularization technique that replaces object labels with pseudo-names, ensuring the model relies on visual context rather than prior knowledge. Our method significantly enhances few-shot localization performance without sacrificing generalization, as demonstrated on several benchmarks tailored to personalized localization. This work is the first to explore and benchmark personalized few-shot localization for VLMs, laying a foundation for future research in context-driven vision-language applications. The code for our project is available at https://github.com/SivanDoveh/IPLoc
Bridging the Visual Gap: Fine-Tuning Multimodal Models with Knowledge-Adapted Captions
Nov 13, 2024



Recent research increasingly focuses on training vision-language models (VLMs) with long, detailed image captions. However, small-scale VLMs often struggle to balance the richness of these captions with the risk of hallucinating content during fine-tuning. In this paper, we explore how well VLMs adapt to such captions. To quantify caption quality, we propose Decomposed NLI (DNLI), an evaluation framework that breaks down generated captions into individual propositions, assessing each in isolation. This fine-grained analysis reveals a critical balance between capturing descriptive details and preventing hallucinations. Our findings show that simply reducing caption complexity or employing standard data curation techniques does not effectively resolve this issue. To tackle this challenge, we introduce Knowledge Adapted (KnowAda) fine-tuning, a data-centric approach that automatically adapts training data with the model's existing knowledge and visual understanding. KnowAda minimizes hallucinations while preserving high descriptiveness. We validate this approach across several small-scale VLMs (up to 7B parameters) and dense caption datasets, demonstrating that KnowAda effectively balances hallucination reduction and descriptiveness. Our results show that KnowAda outperforms various baselines in both automatic metrics and human evaluations. We will release our code and models.