 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling MLP Neuron Weights in Vocabulary Space
Apr 07, 2026Interpreting the information encoded in model weights remains a fundamental challenge in mechanistic interpretability. In this work, we introduce ROTATE (Rotation-Optimized Token Alignment in weighT spacE), a data-free method requiring no forward passes that disentangles MLP neurons directly in weight space. Our approach relies on a key statistical observation: neurons that encode coherent, monosemantic concepts exhibit high kurtosis when projected onto the model's vocabulary. By optimizing rotations of neuron weights to maximize their vocabulary-space kurtosis, our method recovers sparse, interpretable directions which we name vocabulary channels. Experiments on Llama-3.1-8B-Instruct and Gemma-2-2B-it demonstrate that ROTATE consistently recovers vocabulary channels that are faithful to the neuron's behavior. ablating individual channels selectively disables corresponding input activations or the promotion of specific concepts. Moreover, aggregating channel-level descriptions yields comprehensive neuron descriptions that outperform optimized activation-based baselines by 2-3x in head-to-head comparisons. By providing a data-free decomposition of neuron weights, ROTATE offers a scalable, fine-grained building block for interpreting LMs.
Friends and Grandmothers in Silico: Localizing Entity Cells in Language Models
Apr 01, 2026Language models can answer many entity-centric factual questions, but it remains unclear which internal mechanisms are involved in this process. We study this question across multiple language models. We localize entity-selective MLP neurons using templated prompts about each entity, and then validate them with causal interventions on PopQA-based QA examples. On a curated set of 200 entities drawn from PopQA, localized neurons concentrate in early layers. Negative ablation produces entity-specific amnesia, while controlled injection at a placeholder token improves answer retrieval relative to mean-entity and wrong-cell controls. For many entities, activating a single localized neuron is sufficient to recover entity-consistent predictions once the context is initialized, consistent with compact entity retrieval rather than purely gradual enrichment across depth. Robustness to aliases, acronyms, misspellings, and multilingual forms supports a canonicalization interpretation. The effect is strong but not universal: not every entity admits a reliable single-neuron handle, and coverage is higher for popular entities. Overall, these results identify sparse, causally actionable access points for analyzing and modulating entity-conditioned factual behavior.
Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs
Mar 10, 2026While reasoning in LLMs plays a natural role in math, code generation, and multi-hop factual questions, its effect on simple, single-hop factual questions remains unclear. Such questions do not require step-by-step logical decomposition, making the utility of reasoning highly counterintuitive. Nevertheless, we find that enabling reasoning substantially expands the capability boundary of the model's parametric knowledge recall, unlocking correct answers that are otherwise effectively unreachable. Why does reasoning aid parametric knowledge recall when there are no complex reasoning steps to be done? To answer this, we design a series of hypothesis-driven controlled experiments, and identify two key driving mechanisms: (1) a computational buffer effect, where the model uses the generated reasoning tokens to perform latent computation independent of their semantic content; and (2) factual priming, where generating topically related facts acts as a semantic bridge that facilitates correct answer retrieval. Importantly, this latter generative self-retrieval mechanism carries inherent risks: we demonstrate that hallucinating intermediate facts during reasoning increases the likelihood of hallucinations in the final answer. Finally, we show that our insights can be harnessed to directly improve model accuracy by prioritizing reasoning trajectories that contain hallucination-free factual statements.
Latent Reasoning with Supervised Thinking States
Feb 09, 2026Reasoning with a chain-of-thought (CoT) enables Large Language Models (LLMs) to solve complex tasks but incurs significant inference costs due to the generation of long rationales. We propose Thinking States, a method that performs reasoning {\em while} the input is processing. Specifically, Thinking States generates sequences of thinking tokens every few input tokens, transforms the thoughts back into embedding space, and adds them to the following input tokens. This has two key advantages. First, it captures the recurrent nature of CoT, but where the thought tokens are generated as input is processing. Second, since the thoughts are represented as tokens, they can be learned from natural language supervision, and using teacher-forcing, which is parallelizable. Empirically, Thinking States outperforms other latent reasoning methods on multiple reasoning tasks, narrowing the gap to CoT on math problems, and matching its performance on 2-Hop QA with improved latency. On state-tracking tasks, we show Thinking States leads to stronger reasoning behavior than CoT, successfully extrapolating to longer sequences than seen during training.
Indications of Belief-Guided Agency and Meta-Cognitive Monitoring in Large Language Models
Feb 02, 2026Rapid advancements in large language models (LLMs) have sparked the question whether these models possess some form of consciousness. To tackle this challenge, Butlin et al. (2023) introduced a list of indicators for consciousness in artificial systems based on neuroscientific theories. In this work, we evaluate a key indicator from this list, called HOT-3, which tests for agency guided by a general belief-formation and action selection system that updates beliefs based on meta-cognitive monitoring. We view beliefs as representations in the model's latent space that emerge in response to a given input, and introduce a metric to quantify their dominance during generation. Analyzing the dynamics between competing beliefs across models and tasks reveals three key findings: (1) external manipulations systematically modulate internal belief formation, (2) belief formation causally drives the model's action selection, and (3) models can monitor and report their own belief states. Together, these results provide empirical support for the existence of belief-guided agency and meta-cognitive monitoring in LLMs. More broadly, our work lays methodological groundwork for investigating the emergence of agency, beliefs, and meta-cognition in LLMs.
From Directions to Regions: Decomposing Activations in Language Models via Local Geometry
Feb 02, 2026Activation decomposition methods in language models are tightly coupled to geometric assumptions on how concepts are realized in activation space. Existing approaches search for individual global directions, implicitly assuming linear separability, which overlooks concepts with nonlinear or multi-dimensional structure. In this work, we leverage Mixture of Factor Analyzers (MFA) as a scalable, unsupervised alternative that models the activation space as a collection of Gaussian regions with their local covariance structure. MFA decomposes activations into two compositional geometric objects: the region's centroid in activation space, and the local variation from the centroid. We train large-scale MFAs for Llama-3.1-8B and Gemma-2-2B, and show they capture complex, nonlinear structures in activation space. Moreover, evaluations on localization and steering benchmarks show that MFA outperforms unsupervised baselines, is competitive with supervised localization methods, and often achieves stronger steering performance than sparse autoencoders. Together, our findings position local geometry, expressed through subspaces, as a promising unit of analysis for scalable concept discovery and model control, accounting for complex structures that isolated directions fail to capture.
Rethinking Selective Knowledge Distillation
Feb 01, 2026Growing efforts to improve knowledge distillation (KD) in large language models (LLMs) replace dense teacher supervision with selective distillation, which uses a subset of token positions, vocabulary classes, or training samples for supervision. However, it remains unclear which importance signals, selection policies, and their interplay are most effective. In this work, we revisit where and how to distill in autoregressive LLMs. We disentangle selective KD along the position, class, and sample axes and systematically compare importance signals and selection policies. Then, guided by this analysis, we identify underexplored opportunities and introduce student-entropy-guided position selection (SE-KD). Across a suite of benchmarks, SE-KD often improves accuracy, downstream task adherence, and memory efficiency over dense distillation. Extending this approach across the class and sample axes (SE-KD 3X) yields complementary efficiency gains that make offline teacher caching feasible. In practice, this reduces wall time by 70% and peak memory by 18%, while cutting storage usage by 80% over prior methods without sacrificing performance.
Detecting (Un)answerability in Large Language Models with Linear Directions
Sep 26, 2025


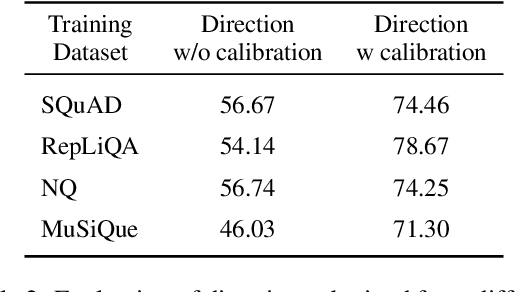
Large language models (LLMs) often respond confidently to questions even when they lack the necessary information, leading to hallucinated answers. In this work, we study the problem of (un)answerability detection, focusing on extractive question answering (QA) where the model should determine if a passage contains sufficient information to answer a given question. We propose a simple approach for identifying a direction in the model's activation space that captures unanswerability and uses it for classification. This direction is selected by applying activation additions during inference and measuring their impact on the model's abstention behavior. We show that projecting hidden activations onto this direction yields a reliable score for (un)answerability classification. Experiments on two open-weight LLMs and four extractive QA benchmarks show that our method effectively detects unanswerable questions and generalizes better across datasets than existing prompt-based and classifier-based approaches. Moreover, the obtained directions extend beyond extractive QA to unanswerability that stems from factors, such as lack of scientific consensus and subjectivity. Last, causal interventions show that adding or ablating the directions effectively controls the abstention behavior of the model.
LMEnt: A Suite for Analyzing Knowledge in Language Models from Pretraining Data to Representations
Sep 03, 2025

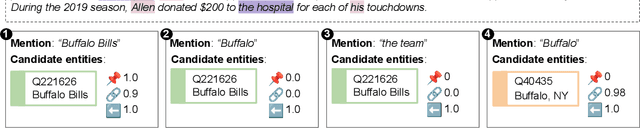
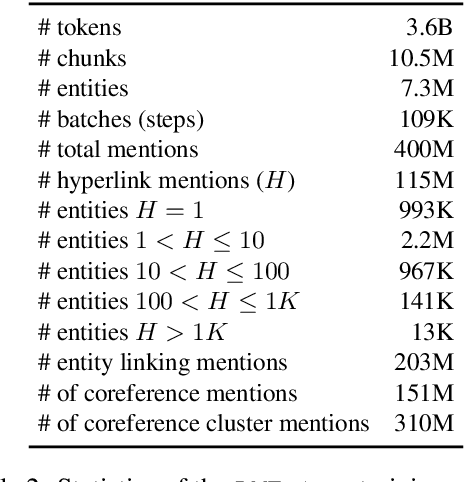
Language models (LMs) increasingly drive real-world applications that require world knowledge. However, the internal processes through which models turn data into representations of knowledge and beliefs about the world, are poorly understood. Insights into these processes could pave the way for developing LMs with knowledge representations that are more consistent, robust, and complete. To facilitate studying these questions, we present LMEnt, a suite for analyzing knowledge acquisition in LMs during pretraining. LMEnt introduces: (1) a knowledge-rich pretraining corpus, fully annotated with entity mentions, based on Wikipedia, (2) an entity-based retrieval method over pretraining data that outperforms previous approaches by as much as 80.4%, and (3) 12 pretrained models with up to 1B parameters and 4K intermediate checkpoints, with comparable performance to popular open-sourced models on knowledge benchmarks. Together, these resources provide a controlled environment for analyzing connections between entity mentions in pretraining and downstream performance, and the effects of causal interventions in pretraining data. We show the utility of LMEnt by studying knowledge acquisition across checkpoints, finding that fact frequency is key, but does not fully explain learning trends. We release LMEnt to support studies of knowledge in LMs, including knowledge representations, plasticity, editing, attribution, and learning dynamics.
Decomposing MLP Activations into Interpretable Features via Semi-Nonnegative Matrix Factorization
Jun 12, 2025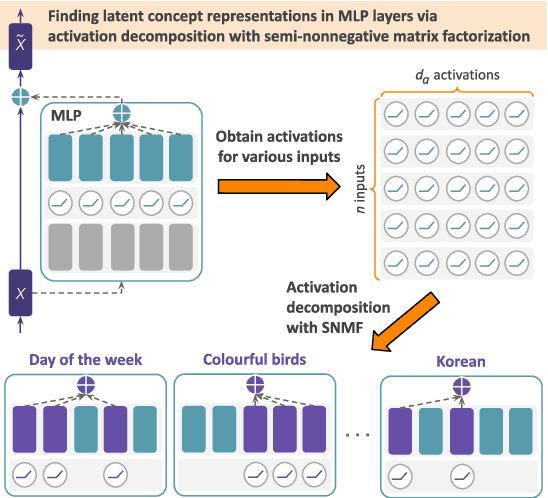



A central goal for mechanistic interpretability has been to identify the right units of analysis in large language models (LLMs) that causally explain their outputs. While early work focused on individual neurons, evidence that neurons often encode multiple concepts has motivated a shift toward analyzing directions in activation space. A key question is how to find directions that capture interpretable features in an unsupervised manner. Current methods rely on dictionary learning with sparse autoencoders (SAEs), commonly trained over residual stream activations to learn directions from scratch. However, SAEs often struggle in causal evaluations and lack intrinsic interpretability, as their learning is not explicitly tied to the computations of the model. Here, we tackle these limitations by directly decomposing MLP activations with semi-nonnegative matrix factorization (SNMF), such that the learned features are (a) sparse linear combinations of co-activated neurons, and (b) mapped to their activating inputs, making them directly interpretable. Experiments on Llama 3.1, Gemma 2 and GPT-2 show that SNMF derived features outperform SAEs and a strong supervised baseline (difference-in-means) on causal steering, while aligning with human-interpretable concepts. Further analysis reveals that specific neuron combinations are reused across semantically-related features, exposing a hierarchical structure in the MLP's activation space. Together, these results position SNMF as a simple and effective tool for identifying interpretable features and dissecting concept representations in LLMs.