 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Can Reasoning Models Identify and Recover from Unhelpful Thoughts?
Jun 12, 2025Recent reasoning models show the ability to reflect, backtrack, and self-validate their reasoning, which is crucial in spotting mistakes and arriving at accurate solutions. A natural question that arises is how effectively models can perform such self-reevaluation. We tackle this question by investigating how well reasoning models identify and recover from four types of unhelpful thoughts: uninformative rambling thoughts, thoughts irrelevant to the question, thoughts misdirecting the question as a slightly different question, and thoughts that lead to incorrect answers. We show that models are effective at identifying most unhelpful thoughts but struggle to recover from the same thoughts when these are injected into their thinking process, causing significant performance drops. Models tend to naively continue the line of reasoning of the injected irrelevant thoughts, which showcases that their self-reevaluation abilities are far from a general "meta-cognitive" awareness. Moreover, we observe non/inverse-scaling trends, where larger models struggle more than smaller ones to recover from short irrelevant thoughts, even when instructed to reevaluate their reasoning. We demonstrate the implications of these findings with a jailbreak experiment using irrelevant thought injection, showing that the smallest models are the least distracted by harmful-response-triggering thoughts. Overall, our findings call for improvement in self-reevaluation of reasoning models to develop better reasoning and safer systems.
SuRe: Summarizing Retrievals using Answer Candidates for Open-domain QA of LLMs
Apr 17, 2024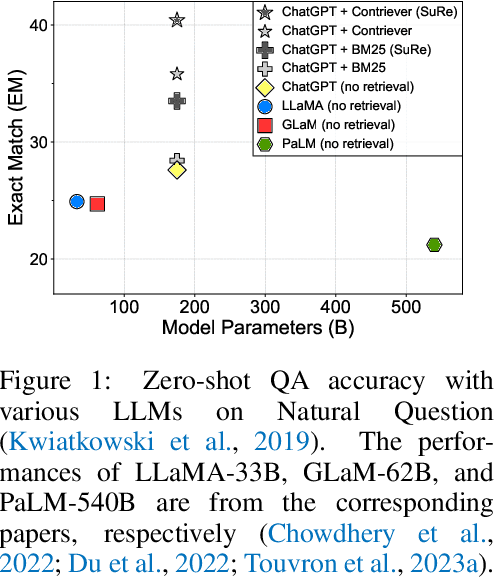
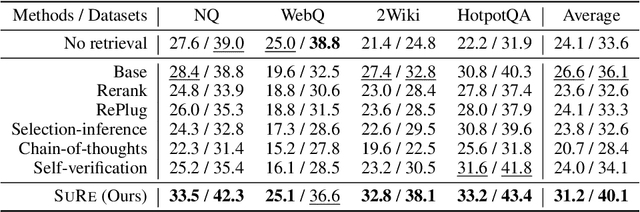

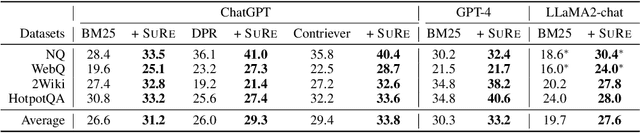
Large language models (LLMs) have made significant advancements in various natural language processing tasks, including question answering (QA) tasks. While incorporating new information with the retrieval of relevant passages is a promising way to improve QA with LLMs, the existing methods often require additional fine-tuning which becomes infeasible with recent LLMs. Augmenting retrieved passages via prompting has the potential to address this limitation, but this direction has been limitedly explored. To this end, we design a simple yet effective framework to enhance open-domain QA (ODQA) with LLMs, based on the summarized retrieval (SuRe). SuRe helps LLMs predict more accurate answers for a given question, which are well-supported by the summarized retrieval that could be viewed as an explicit rationale extracted from the retrieved passages. Specifically, SuRe first constructs summaries of the retrieved passages for each of the multiple answer candidates. Then, SuRe confirms the most plausible answer from the candidate set by evaluating the validity and ranking of the generated summaries. Experimental results on diverse ODQA benchmarks demonstrate the superiority of SuRe, with improvements of up to 4.6% in exact match (EM) and 4.0% in F1 score over standard prompting approaches. SuRe also can be integrated with a broad range of retrieval methods and LLMs. Finally, the generated summaries from SuRe show additional advantages to measure the importance of retrieved passages and serve as more preferred rationales by models and humans.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Universal Domain Adaptation for Robust Handling of Distributional Shifts in NLP
Oct 23, 2023When deploying machine learning systems to the wild, it is highly desirable for them to effectively leverage prior knowledge to the unfamiliar domain while also firing alarms to anomalous inputs. In order to address these requirements, Universal Domain Adaptation (UniDA) has emerged as a novel research area in computer vision, focusing on achieving both adaptation ability and robustness (i.e., the ability to detect out-of-distribution samples). While UniDA has led significant progress in computer vision, its application on language input still needs to be explored despite its feasibility. In this paper, we propose a comprehensive benchmark for natural language that offers thorough viewpoints of the model's generalizability and robustness. Our benchmark encompasses multiple datasets with varying difficulty levels and characteristics, including temporal shifts and diverse domains. On top of our testbed, we validate existing UniDA methods from computer vision and state-of-the-art domain adaptation techniques from NLP literature, yielding valuable findings: We observe that UniDA methods originally designed for image input can be effectively transferred to the natural language domain while also underscoring the effect of adaptation difficulty in determining the model's performance.
Query-Efficient Black-Box Red Teaming via Bayesian Optimization
May 27, 2023



The deployment of large-scale generative models is often restricted by their potential risk of causing harm to users in unpredictable ways. We focus on the problem of black-box red teaming, where a red team generates test cases and interacts with the victim model to discover a diverse set of failures with limited query access. Existing red teaming methods construct test cases based on human supervision or language model (LM) and query all test cases in a brute-force manner without incorporating any information from past evaluations, resulting in a prohibitively large number of queries. To this end, we propose Bayesian red teaming (BRT), novel query-efficient black-box red teaming methods based on Bayesian optimization, which iteratively identify diverse positive test cases leading to model failures by utilizing the pre-defined user input pool and the past evaluations. Experimental results on various user input pools demonstrate that our method consistently finds a significantly larger number of diverse positive test cases under the limited query budget than the baseline methods. The source code is available at https://github.com/snu-mllab/Bayesian-Red-Teaming.
Asking Clarification Questions to Handle Ambiguity in Open-Domain QA
May 23, 2023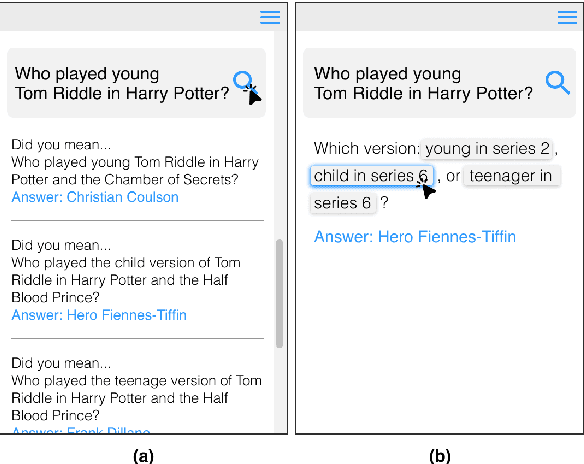
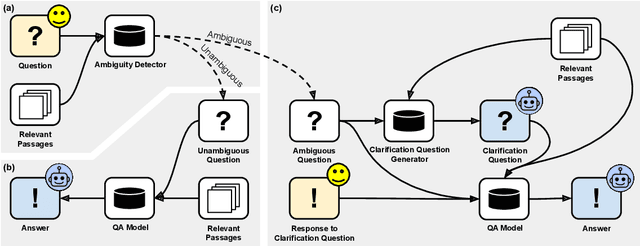

Ambiguous questions persist in open-domain question answering, because formulating a precise question with a unique answer is often challenging. Previously, Min et al. (2020) have tackled this issue by generating disambiguated questions for all possible interpretations of the ambiguous question. This can be effective, but not ideal for providing an answer to the user. Instead, we propose to ask a clarification question, where the user's response will help identify the interpretation that best aligns with the user's intention. We first present CAMBIGNQ, a dataset consisting of 5,654 ambiguous questions, each with relevant passages, possible answers, and a clarification question. The clarification questions were efficiently created by generating them using InstructGPT and manually revising them as necessary. We then define a pipeline of tasks and design appropriate evaluation metrics. Lastly, we achieve 61.3 F1 on ambiguity detection and 40.5 F1 on clarification-based QA, providing strong baselines for future work.
Prompt-Augmented Linear Probing: Scaling Beyond The Limit of Few-shot In-Context Learners
Dec 28, 2022Through in-context learning (ICL), large-scale language models are effective few-shot learners without additional model fine-tuning. However, the ICL performance does not scale well with the number of available training samples as it is limited by the inherent input length constraint of the underlying language model. Meanwhile, many studies have revealed that language models are also powerful feature extractors, allowing them to be utilized in a black-box manner and enabling the linear probing paradigm, where lightweight discriminators are trained on top of the pre-extracted input representations. This paper proposes prompt-augmented linear probing (PALP), a hybrid of linear probing and ICL, which leverages the best of both worlds. PALP inherits the scalability of linear probing and the capability of enforcing language models to derive more meaningful representations via tailoring input into a more conceivable form. Throughout in-depth investigations on various datasets, we verified that PALP significantly enhances the input representations closing the gap between ICL in the data-hungry scenario and fine-tuning in the data-abundant scenario with little training overhead, potentially making PALP a strong alternative in a black-box scenario.
Can Current Task-oriented Dialogue Models Automate Real-world Scenarios in the Wild?
Dec 20, 2022Task-oriented dialogue (TOD) systems are mainly based on the slot-filling-based TOD (SF-TOD) framework, in which dialogues are broken down into smaller, controllable units (i.e., slots) to fulfill a specific task. A series of approaches based on this framework achieved remarkable success on various TOD benchmarks. However, we argue that the current TOD benchmarks are limited to surrogate real-world scenarios and that the current TOD models are still a long way from unraveling the scenarios. In this position paper, we first identify current status and limitations of SF-TOD systems. After that, we explore the WebTOD framework, the alternative direction for building a scalable TOD system when a web/mobile interface is available. In WebTOD, the dialogue system learns how to understand the web/mobile interface that the human agent interacts with, powered by a large-scale language model.
Pivotal Role of Language Modeling in Recommender Systems: Enriching Task-specific and Task-agnostic Representation Learning
Dec 13, 2022



Recent studies have proposed unified user modeling frameworks that leverage user behavior data from various applications. Many of them benefit from utilizing users' behavior sequences as plain texts, representing rich information in any domain or system without losing generality. Hence, a question arises: Can language modeling for user history corpus help improve recommender systems? While its versatile usability has been widely investigated in many domains, its applications to recommender systems still remain underexplored. We show that language modeling applied directly to task-specific user histories achieves excellent results on diverse recommendation tasks. Also, leveraging additional task-agnostic user histories delivers significant performance benefits. We further demonstrate that our approach can provide promising transfer learning capabilities for a broad spectrum of real-world recommender systems, even on unseen domains and services.
Keep Me Updated! Memory Management in Long-term Conversations
Oct 17, 2022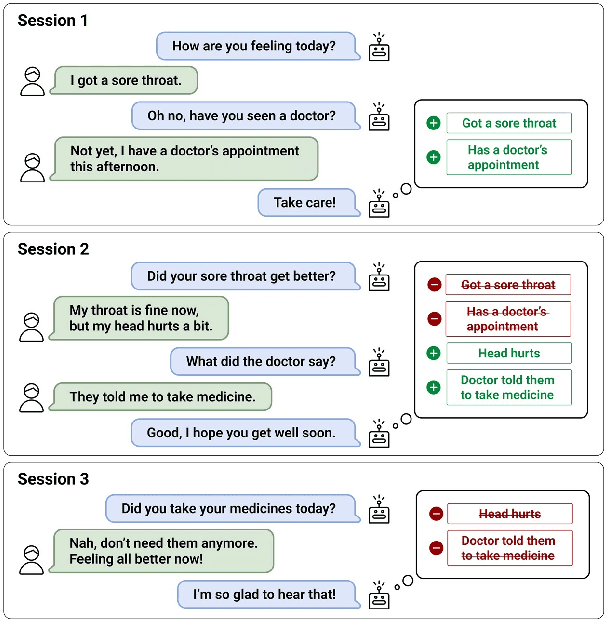
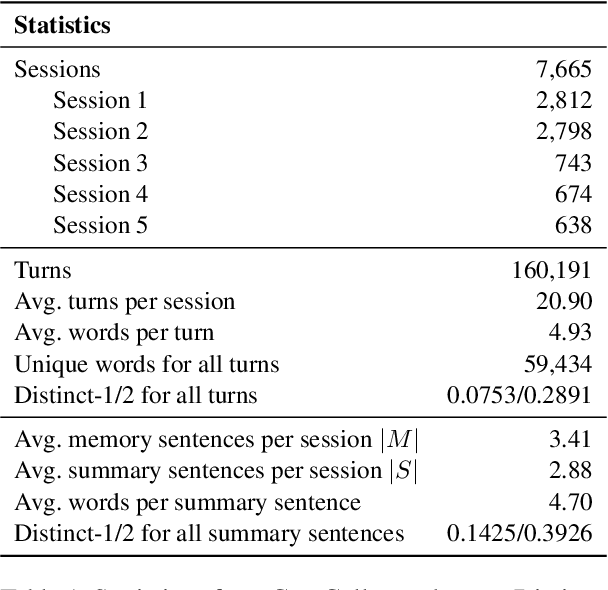
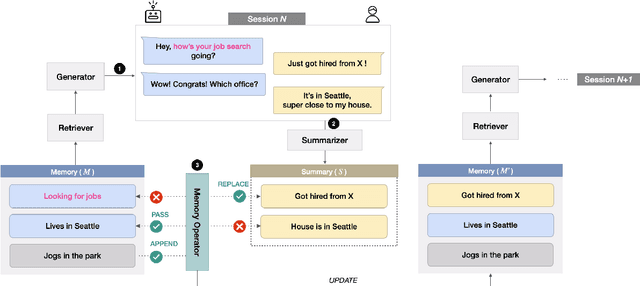
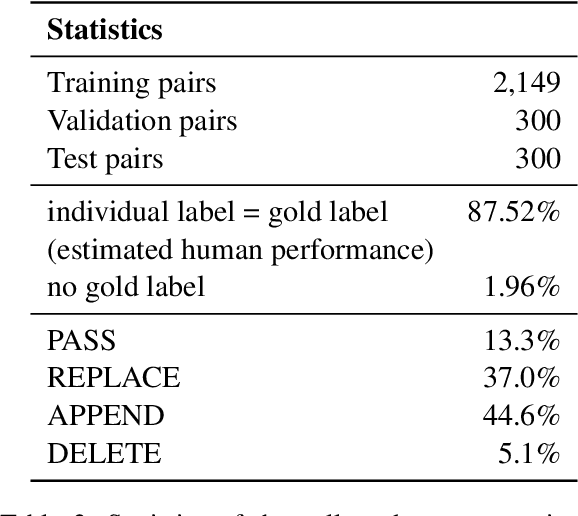
Remembering important information from the past and continuing to talk about it in the present are crucial in long-term conversations. However, previous literature does not deal with cases where the memorized information is outdated, which may cause confusion in later conversations. To address this issue, we present a novel task and a corresponding dataset of memory management in long-term conversations, in which bots keep track of and bring up the latest information about users while conversing through multiple sessions. In order to support more precise and interpretable memory, we represent memory as unstructured text descriptions of key information and propose a new mechanism of memory management that selectively eliminates invalidated or redundant information. Experimental results show that our approach outperforms the baselines that leave the stored memory unchanged in terms of engagingness and humanness, with larger performance gap especially in the later sessions.