 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Forget the Critic: Value-Based Data Rehearsal for Multi-Cyclic Continual Reinforcement Learning
May 21, 2026Data rehearsal has emerged as a leading approach for mitigating catastrophic forgetting in Continual Reinforcement Learning (CRL). However, existing work remains confined to policy gradient frameworks, regularizing only actors due to the performance degradation incurred by critic regularization. This actor-centric approach overlooks the potential of data rehearsal for value function approximation. Moreover, existing evaluations in CRL rarely consider multi-cyclic environments where task sequences repeat, a critical real-world scenario that exacerbates forgetting and plasticity. We investigate data rehearsal for Deep Q-Networks using Q-value regularization in multi-cyclic settings and propose Qreg+NWLU which introduces two simple modifications: (1) continuous data rehearsal that dynamically collects and updates stored Q-values throughout training, and (2) "No-Wait" regularization that applies immediately rather than after the first task. Together, these modifications yield improvements in learning efficiency, forgetting mitigation, and knowledge transfer over Qreg and conventional CRL methods within value function approximation settings.
OPRO: Orthogonal Panel-Relative Operators for Panel-Aware In-Context Image Generation
Mar 29, 2026We introduce a parameter-efficient adaptation method for panel-aware in-context image generation with pre-trained diffusion transformers. The key idea is to compose learnable, panel-specific orthogonal operators onto the backbone's frozen positional encodings. This design provides two desirable properties: (1) isometry, which preserves the geometry of internal features, and (2) same-panel invariance, which maintains the model's pre-trained intra-panel synthesis behavior. Through controlled experiments, we demonstrate that the effectiveness of our adaptation method is not tied to a specific positional encoding design but generalizes across diverse positional encoding regimes. By enabling effective panel-relative conditioning, the proposed method consistently improves in-context image-based instructional editing pipelines, including state-of-the-art approaches.
SNAP: Speaker Nulling for Artifact Projection in Speech Deepfake Detection
Mar 21, 2026Recent advancements in text-to-speech technologies enable generating high-fidelity synthetic speech nearly indistinguishable from real human voices. While recent studies show the efficacy of self-supervised learning-based speech encoders for deepfake detection, these models struggle to generalize across unseen speakers. Our quantitative analysis suggests these encoder representations are substantially influenced by speaker information, causing detectors to exploit speaker-specific correlations rather than artifact-related cues. We call this phenomenon speaker entanglement. To mitigate this reliance, we introduce SNAP, a speaker-nulling framework. We estimate a speaker subspace and apply orthogonal projection to suppress speaker-dependent components, isolating synthesis artifacts within the residual features. By reducing speaker entanglement, SNAP encourages detectors to focus on artifact-related patterns, leading to state-of-the-art performance.
When Wording Steers the Evaluation: Framing Bias in LLM judges
Jan 20, 2026Large language models (LLMs) are known to produce varying responses depending on prompt phrasing, indicating that subtle guidance in phrasing can steer their answers. However, the impact of this framing bias on LLM-based evaluation, where models are expected to make stable and impartial judgments, remains largely underexplored. Drawing inspiration from the framing effect in psychology, we systematically investigate how deliberate prompt framing skews model judgments across four high-stakes evaluation tasks. We design symmetric prompts using predicate-positive and predicate-negative constructions and demonstrate that such framing induces significant discrepancies in model outputs. Across 14 LLM judges, we observe clear susceptibility to framing, with model families showing distinct tendencies toward agreement or rejection. These findings suggest that framing bias is a structural property of current LLM-based evaluation systems, underscoring the need for framing-aware protocols.
Judging Against the Reference: Uncovering Knowledge-Driven Failures in LLM-Judges on QA Evaluation
Jan 12, 2026While large language models (LLMs) are increasingly used as automatic judges for question answering (QA) and other reference-conditioned evaluation tasks, little is known about their ability to adhere to a provided reference. We identify a critical failure mode of such reference-based LLM QA evaluation: when the provided reference conflicts with the judge model's parametric knowledge, the resulting scores become unreliable, substantially degrading evaluation fidelity. To study this phenomenon systematically, we introduce a controlled swapped-reference QA framework that induces reference-belief conflicts. Specifically, we replace the reference answer with an incorrect entity and construct diverse pairings of original and swapped references with correspondingly aligned candidate answers. Surprisingly, grading reliability drops sharply under swapped references across a broad set of judge models. We empirically show that this vulnerability is driven by judges' over-reliance on parametric knowledge, leading judges to disregard the given reference under conflict. Finally, we find that this failure persists under common prompt-based mitigation strategies, highlighting a fundamental limitation of LLM-as-a-judge evaluation and motivating reference-based protocols that enforce stronger adherence to the provided reference.
Synthetic Tabular Data Generation: A Comparative Survey for Modern Techniques
Jul 15, 2025



As privacy regulations become more stringent and access to real-world data becomes increasingly constrained, synthetic data generation has emerged as a vital solution, especially for tabular datasets, which are central to domains like finance, healthcare and the social sciences. This survey presents a comprehensive and focused review of recent advances in synthetic tabular data generation, emphasizing methods that preserve complex feature relationships, maintain statistical fidelity, and satisfy privacy requirements. A key contribution of this work is the introduction of a novel taxonomy based on practical generation objectives, including intended downstream applications, privacy guarantees, and data utility, directly informing methodological design and evaluation strategies. Therefore, this review prioritizes the actionable goals that drive synthetic data creation, including conditional generation and risk-sensitive modeling. Additionally, the survey proposes a benchmark framework to align technical innovation with real-world demands. By bridging theoretical foundations with practical deployment, this work serves as both a roadmap for future research and a guide for implementing synthetic tabular data in privacy-critical environments.
Fine-grained Gender Control in Machine Translation with Large Language Models
Jul 21, 2024
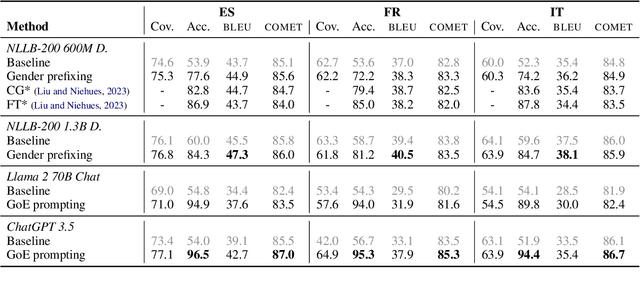
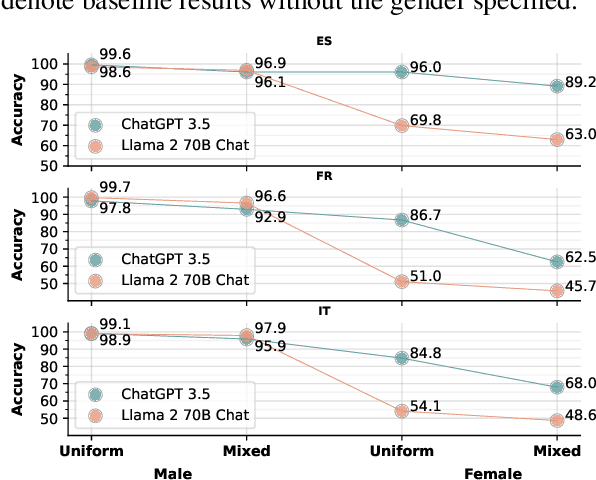
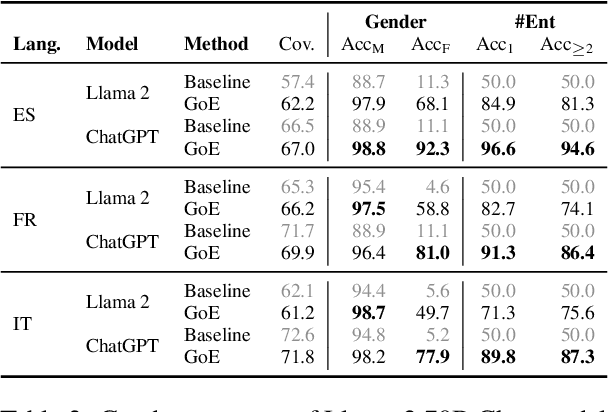
In machine translation, the problem of ambiguously gendered input has been pointed out, where the gender of an entity is not available in the source sentence. To address this ambiguity issue, the task of controlled translation that takes the gender of the ambiguous entity as additional input have been proposed. However, most existing works have only considered a simplified setup of one target gender for input. In this paper, we tackle controlled translation in a more realistic setting of inputs with multiple entities and propose Gender-of-Entity (GoE) prompting method for LLMs. Our proposed method instructs the model with fine-grained entity-level gender information to translate with correct gender inflections. By utilizing four evaluation benchmarks, we investigate the controlled translation capability of LLMs in multiple dimensions and find that LLMs reach state-of-the-art performance in controlled translation. Furthermore, we discover an emergence of gender interference phenomenon when controlling the gender of multiple entities. Finally, we address the limitations of existing gender accuracy evaluation metrics and propose leveraging LLMs as an evaluator for gender inflection in machine translation.
Return of EM: Entity-driven Answer Set Expansion for QA Evaluation
Apr 24, 2024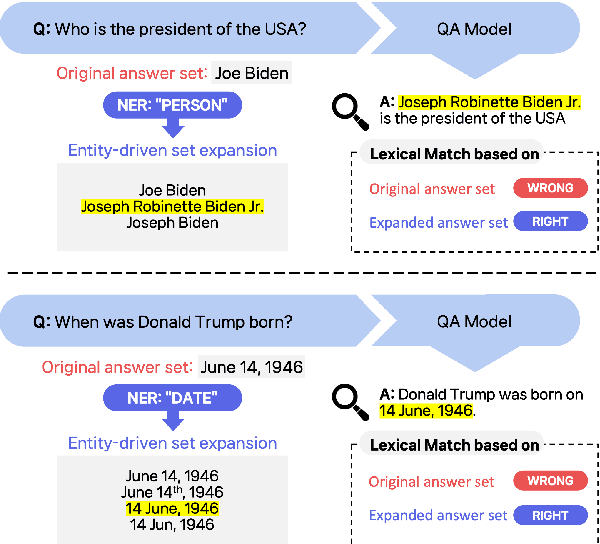
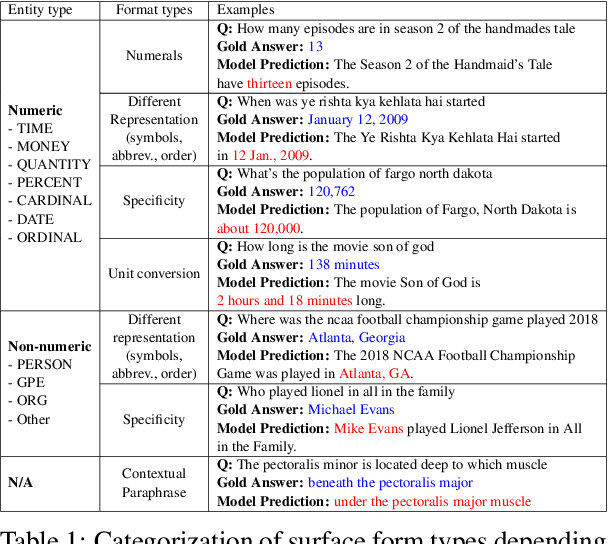
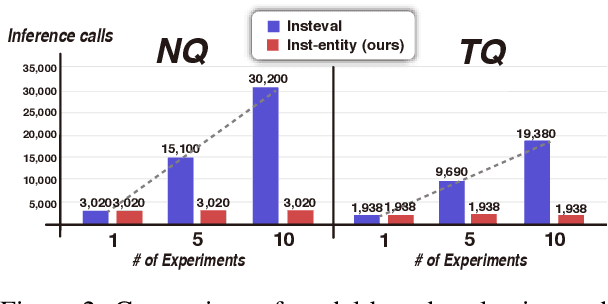
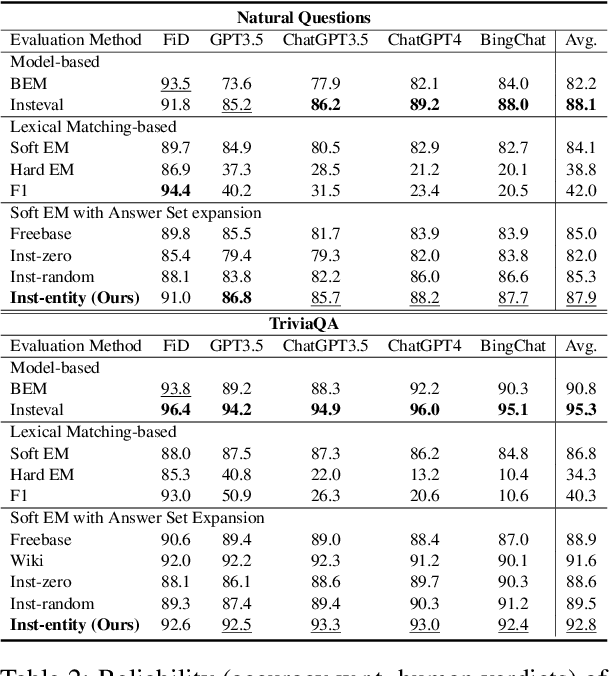
Recently, directly using large language models (LLMs) has been shown to be the most reliable method to evaluate QA models. However, it suffers from limited interpretability, high cost, and environmental harm. To address these, we propose to use soft EM with entity-driven answer set expansion. Our approach expands the gold answer set to include diverse surface forms, based on the observation that the surface forms often follow particular patterns depending on the entity type. The experimental results show that our method outperforms traditional evaluation methods by a large margin. Moreover, the reliability of our evaluation method is comparable to that of LLM-based ones, while offering the benefits of high interpretability and reduced environmental harm.
BAMM: Bidirectional Autoregressive Motion Model
Apr 01, 2024



Generating human motion from text has been dominated by denoising motion models either through diffusion or generative masking process. However, these models face great limitations in usability by requiring prior knowledge of the motion length. Conversely, autoregressive motion models address this limitation by adaptively predicting motion endpoints, at the cost of degraded generation quality and editing capabilities. To address these challenges, we propose Bidirectional Autoregressive Motion Model (BAMM), a novel text-to-motion generation framework. BAMM consists of two key components: (1) a motion tokenizer that transforms 3D human motion into discrete tokens in latent space, and (2) a masked self-attention transformer that autoregressively predicts randomly masked tokens via a hybrid attention masking strategy. By unifying generative masked modeling and autoregressive modeling, BAMM captures rich and bidirectional dependencies among motion tokens, while learning the probabilistic mapping from textual inputs to motion outputs with dynamically-adjusted motion sequence length. This feature enables BAMM to simultaneously achieving high-quality motion generation with enhanced usability and built-in motion editability. Extensive experiments on HumanML3D and KIT-ML datasets demonstrate that BAMM surpasses current state-of-the-art methods in both qualitative and quantitative measures. Our project page is available at https://exitudio.github.io/BAMM-page
Can LLMs Recognize Toxicity? Structured Toxicity Investigation Framework and Semantic-Based Metric
Feb 16, 2024In the pursuit of developing Large Language Models (LLMs) that adhere to societal standards, it is imperative to discern the existence of toxicity in the generated text. The majority of existing toxicity metrics rely on encoder models trained on specific toxicity datasets. However, these encoders are susceptible to out-of-distribution (OOD) problems and depend on the definition of toxicity assumed in a dataset. In this paper, we introduce an automatic robust metric grounded on LLMs to distinguish whether model responses are toxic. We start by analyzing the toxicity factors, followed by examining the intrinsic toxic attributes of LLMs to ascertain their suitability as evaluators. Subsequently, we evaluate our metric, LLMs As ToxiciTy Evaluators (LATTE), on evaluation datasets.The empirical results indicate outstanding performance in measuring toxicity, improving upon state-of-the-art metrics by 12 points in F1 score without training procedure. We also show that upstream toxicity has an influence on downstream metrics.