 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Mar 25, 2026Self-distillation has emerged as an effective post-training paradigm for LLMs, often improving performance while shortening reasoning traces. However, in mathematical reasoning, we find that it can reduce response length while degrading performance. We trace this degradation to the suppression of epistemic verbalization - the model's expression of uncertainty during reasoning. Through controlled experiments varying conditioning context richness and task coverage, we show that conditioning the teacher on rich information suppresses uncertainty expression, enabling rapid in-domain optimization with limited task coverage but harming OOD performance, where unseen problems benefit from expressing uncertainty and adjusting accordingly. Across Qwen3-8B, DeepSeek-Distill-Qwen-7B, and Olmo3-7B-Instruct, we observe performance drops of up to 40%. Our findings highlight that exposing appropriate levels of uncertainty is crucial for robust reasoning and underscore the importance of optimizing reasoning behavior beyond merely reinforcing correct answer traces.
SPOC: Safety-Aware Planning Under Partial Observability And Physical Constraints
Feb 25, 2026Embodied Task Planning with large language models faces safety challenges in real-world environments, where partial observability and physical constraints must be respected. Existing benchmarks often overlook these critical factors, limiting their ability to evaluate both feasibility and safety. We introduce SPOC, a benchmark for safety-aware embodied task planning, which integrates strict partial observability, physical constraints, step-by-step planning, and goal-condition-based evaluation. Covering diverse household hazards such as fire, fluid, injury, object damage, and pollution, SPOC enables rigorous assessment through both state and constraint-based online metrics. Experiments with state-of-the-art LLMs reveal that current models struggle to ensure safety-aware planning, particularly under implicit constraints. Code and dataset are available at https://github.com/khm159/SPOC
Beyond Normalization: Rethinking the Partition Function as a Difficulty Scheduler for RLVR
Feb 13, 2026Reward-maximizing RL methods enhance the reasoning performance of LLMs, but often reduce the diversity among outputs. Recent works address this issue by adopting GFlowNets, training LLMs to match a target distribution while jointly learning its partition function. In contrast to prior works that treat this partition function solely as a normalizer, we reinterpret it as a per-prompt expected-reward (i.e., online accuracy) signal, leveraging this unused information to improve sample efficiency. Specifically, we first establish a theoretical relationship between the partition function and per-prompt accuracy estimates. Building on this key insight, we propose Partition Function-Guided RL (PACED-RL), a post-training framework that leverages accuracy estimates to prioritize informative question prompts during training, and further improves sample efficiency through an accuracy estimate error-prioritized replay. Crucially, both components reuse information already produced during GFlowNet training, effectively amortizing the compute overhead into the existing optimization process. Extensive experiments across diverse benchmarks demonstrate strong performance improvements over GRPO and prior GFlowNet approaches, highlighting PACED-RL as a promising direction for a more sample efficient distribution-matching training for LLMs.
Confidence-Guided Stepwise Model Routing for Cost-Efficient Reasoning
Nov 09, 2025Recent advances in Large Language Models (LLMs) - particularly model scaling and test-time techniques - have greatly enhanced the reasoning capabilities of language models at the expense of higher inference costs. To lower inference costs, prior works train router models or deferral mechanisms that allocate easy queries to a small, efficient model, while forwarding harder queries to larger, more expensive models. However, these trained router models often lack robustness under domain shifts and require expensive data synthesis techniques such as Monte Carlo rollouts to obtain sufficient ground-truth routing labels for training. In this work, we propose Confidence-Guided Stepwise Model Routing for Cost-Efficient Reasoning (STEER), a domain-agnostic framework that performs fine-grained, step-level routing between smaller and larger LLMs without utilizing external models. STEER leverages confidence scores from the smaller model's logits prior to generating a reasoning step, so that the large model is invoked only when necessary. Extensive evaluations using different LLMs on a diverse set of challenging benchmarks across multiple domains such as Mathematical Reasoning, Multi-Hop QA, and Planning tasks indicate that STEER achieves competitive or enhanced accuracy while reducing inference costs (up to +20% accuracy with 48% less FLOPs compared to solely using the larger model on AIME), outperforming baselines that rely on trained external modules. Our results establish model-internal confidence as a robust, domain-agnostic signal for model routing, offering a scalable pathway for efficient LLM deployment.
ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State Reflection
May 21, 2025Recent advances in LLM agents have largely built on reasoning backbones like ReAct, which interleave thought and action in complex environments. However, ReAct often produces ungrounded or incoherent reasoning steps, leading to misalignment between the agent's actual state and goal. Our analysis finds that this stems from ReAct's inability to maintain consistent internal beliefs and goal alignment, causing compounding errors and hallucinations. To address this, we introduce ReflAct, a novel backbone that shifts reasoning from merely planning next actions to continuously reflecting on the agent's state relative to its goal. By explicitly grounding decisions in states and enforcing ongoing goal alignment, ReflAct dramatically improves strategic reliability. This design delivers substantial empirical gains: ReflAct surpasses ReAct by 27.7% on average, achieving a 93.3% success rate in ALFWorld. Notably, ReflAct even outperforms ReAct with added enhancement modules (e.g., Reflexion, WKM), showing that strengthening the core reasoning backbone is key to reliable agent performance.
Subnet-Aware Dynamic Supernet Training for Neural Architecture Search
Mar 13, 2025N-shot neural architecture search (NAS) exploits a supernet containing all candidate subnets for a given search space. The subnets are typically trained with a static training strategy (e.g., using the same learning rate (LR) scheduler and optimizer for all subnets). This, however, does not consider that individual subnets have distinct characteristics, leading to two problems: (1) The supernet training is biased towards the low-complexity subnets (unfairness); (2) the momentum update in the supernet is noisy (noisy momentum). We present a dynamic supernet training technique to address these problems by adjusting the training strategy adaptive to the subnets. Specifically, we introduce a complexity-aware LR scheduler (CaLR) that controls the decay ratio of LR adaptive to the complexities of subnets, which alleviates the unfairness problem. We also present a momentum separation technique (MS). It groups the subnets with similar structural characteristics and uses a separate momentum for each group, avoiding the noisy momentum problem. Our approach can be applicable to various N-shot NAS methods with marginal cost, while improving the search performance drastically. We validate the effectiveness of our approach on various search spaces (e.g., NAS-Bench-201, Mobilenet spaces) and datasets (e.g., CIFAR-10/100, ImageNet).
PLM-Based Discrete Diffusion Language Models with Entropy-Adaptive Gibbs Sampling
Nov 10, 2024


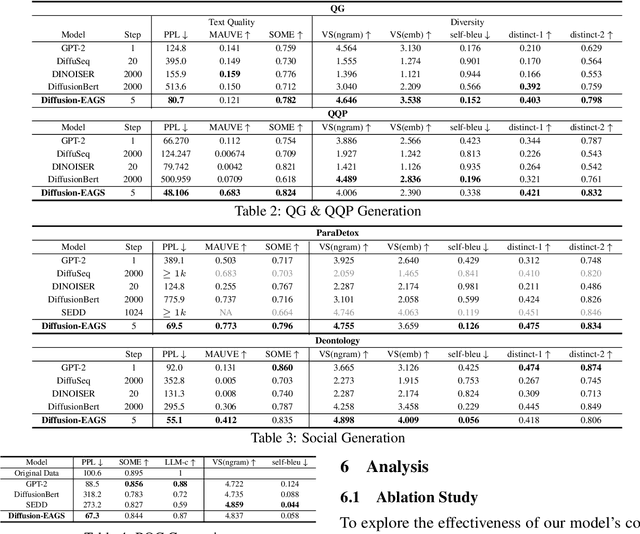
Recently, discrete diffusion language models have demonstrated promising results in NLP. However, there has been limited research on integrating Pretrained Language Models (PLMs) into discrete diffusion models, resulting in underwhelming performance in downstream NLP generation tasks. This integration is particularly challenging because of the discrepancy between step-wise denoising strategy of diffusion models and single-step mask prediction approach of MLM-based PLMs. In this paper, we introduce Diffusion-EAGS, a novel approach that effectively integrates PLMs with the diffusion models. Furthermore, as it is challenging for PLMs to determine where to apply denoising during the diffusion process, we integrate an entropy tracking module to assist them. Finally, we propose entropy-based noise scheduling in the forward process to improve the effectiveness of entropy-adaptive sampling throughout the generation phase. Experimental results show that Diffusion-EAGS outperforms existing diffusion baselines in downstream generation tasks, achieving high text quality and diversity with precise token-level control. We also show that our model is capable of adapting to bilingual and low-resource settings, which are common in real-world applications.
Toward INT4 Fixed-Point Training via Exploring Quantization Error for Gradients
Jul 17, 2024Network quantization generally converts full-precision weights and/or activations into low-bit fixed-point values in order to accelerate an inference process. Recent approaches to network quantization further discretize the gradients into low-bit fixed-point values, enabling an efficient training. They typically set a quantization interval using a min-max range of the gradients or adjust the interval such that the quantization error for entire gradients is minimized. In this paper, we analyze the quantization error of gradients for the low-bit fixed-point training, and show that lowering the error for large-magnitude gradients boosts the quantization performance significantly. Based on this, we derive an upper bound of quantization error for the large gradients in terms of the quantization interval, and obtain an optimal condition for the interval minimizing the quantization error for large gradients. We also introduce an interval update algorithm that adjusts the quantization interval adaptively to maintain a small quantization error for large gradients. Experimental results demonstrate the effectiveness of our quantization method for various combinations of network architectures and bit-widths on various tasks, including image classification, object detection, and super-resolution.
Transition Rate Scheduling for Quantization-Aware Training
Apr 30, 2024Quantization-aware training (QAT) simulates a quantization process during training to lower bit-precision of weights/activations. It learns quantized weights indirectly by updating latent weights, i.e., full-precision inputs to a quantizer, using gradient-based optimizers. We claim that coupling a user-defined learning rate (LR) with these optimizers is sub-optimal for QAT. Quantized weights transit discrete levels of a quantizer, only if corresponding latent weights pass transition points, where the quantizer changes discrete states. This suggests that the changes of quantized weights are affected by both the LR for latent weights and their distributions. It is thus difficult to control the degree of changes for quantized weights by scheduling the LR manually. We conjecture that the degree of parameter changes in QAT is related to the number of quantized weights transiting discrete levels. Based on this, we introduce a transition rate (TR) scheduling technique that controls the number of transitions of quantized weights explicitly. Instead of scheduling a LR for latent weights, we schedule a target TR of quantized weights, and update the latent weights with a novel transition-adaptive LR (TALR), enabling considering the degree of changes for the quantized weights during QAT. Experimental results demonstrate the effectiveness of our approach on standard benchmarks.
Instance-Aware Group Quantization for Vision Transformers
Apr 01, 2024Post-training quantization (PTQ) is an efficient model compression technique that quantizes a pretrained full-precision model using only a small calibration set of unlabeled samples without retraining. PTQ methods for convolutional neural networks (CNNs) provide quantization results comparable to full-precision counterparts. Directly applying them to vision transformers (ViTs), however, incurs severe performance degradation, mainly due to the differences in architectures between CNNs and ViTs. In particular, the distribution of activations for each channel vary drastically according to input instances, making PTQ methods for CNNs inappropriate for ViTs. To address this, we introduce instance-aware group quantization for ViTs (IGQ-ViT). To this end, we propose to split the channels of activation maps into multiple groups dynamically for each input instance, such that activations within each group share similar statistical properties. We also extend our scheme to quantize softmax attentions across tokens. In addition, the number of groups for each layer is adjusted to minimize the discrepancies between predictions from quantized and full-precision models, under a bit-operation (BOP) constraint. We show extensive experimental results on image classification, object detection, and instance segmentation, with various transformer architectures, demonstrating the effectiveness of our approach.