 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAIRS-Former: Spatio-Temporal Attention with Interleaved Recursive Structure Transformer for Offline Multi-task Multi-agent Reinforcement Learning
Mar 12, 2026Offline multi-agent reinforcement learning (MARL) with multi-task datasets is challenging due to varying numbers of agents across tasks and the need to generalize to unseen scenarios. Prior works employ transformers with observation tokenization and hierarchical skill learning to address these issues. However, they underutilize the transformer attention mechanism for inter-agent coordination and rely on a single history token, which limits their ability to capture long-horizon temporal dependencies in partially observable MARL settings. In this paper, we propose STAIRS-Former, a transformer architecture augmented with spatial and temporal hierarchies that enables effective attention over critical tokens while capturing long interaction histories. We further introduce token dropout to enhance robustness and generalization across varying agent populations. Extensive experiments on diverse multi-agent benchmarks, including SMAC, SMAC-v2, MPE, and MaMuJoCo, with multi-task datasets demonstrate that STAIRS-Former consistently outperforms prior methods and achieves new state-of-the-art performance.
Align While Search: Belief-Guided Exploratory Inference for World-Grounded Embodied Agents
Dec 30, 2025In this paper, we propose a test-time adaptive agent that performs exploratory inference through posterior-guided belief refinement without relying on gradient-based updates or additional training for LLM agent operating under partial observability. Our agent maintains an external structured belief over the environment state, iteratively updates it via action-conditioned observations, and selects actions by maximizing predicted information gain over the belief space. We estimate information gain using a lightweight LLM-based surrogate and assess world alignment through a novel reward that quantifies the consistency between posterior belief and ground-truth environment configuration. Experiments show that our method outperforms inference-time scaling baselines such as prompt-augmented or retrieval-enhanced LLMs, in aligning with latent world states with significantly lower integration overhead.
ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State Reflection
May 21, 2025Recent advances in LLM agents have largely built on reasoning backbones like ReAct, which interleave thought and action in complex environments. However, ReAct often produces ungrounded or incoherent reasoning steps, leading to misalignment between the agent's actual state and goal. Our analysis finds that this stems from ReAct's inability to maintain consistent internal beliefs and goal alignment, causing compounding errors and hallucinations. To address this, we introduce ReflAct, a novel backbone that shifts reasoning from merely planning next actions to continuously reflecting on the agent's state relative to its goal. By explicitly grounding decisions in states and enforcing ongoing goal alignment, ReflAct dramatically improves strategic reliability. This design delivers substantial empirical gains: ReflAct surpasses ReAct by 27.7% on average, achieving a 93.3% success rate in ALFWorld. Notably, ReflAct even outperforms ReAct with added enhancement modules (e.g., Reflexion, WKM), showing that strengthening the core reasoning backbone is key to reliable agent performance.
Reward Dimension Reduction for Scalable Multi-Objective Reinforcement Learning
Feb 28, 2025In this paper, we introduce a simple yet effective reward dimension reduction method to tackle the scalability challenges of multi-objective reinforcement learning algorithms. While most existing approaches focus on optimizing two to four objectives, their abilities to scale to environments with more objectives remain uncertain. Our method uses a dimension reduction approach to enhance learning efficiency and policy performance in multi-objective settings. While most traditional dimension reduction methods are designed for static datasets, our approach is tailored for online learning and preserves Pareto-optimality after transformation. We propose a new training and evaluation framework for reward dimension reduction in multi-objective reinforcement learning and demonstrate the superiority of our method in environments including one with sixteen objectives, significantly outperforming existing online dimension reduction methods.
The Max-Min Formulation of Multi-Objective Reinforcement Learning: From Theory to a Model-Free Algorithm
Jun 12, 2024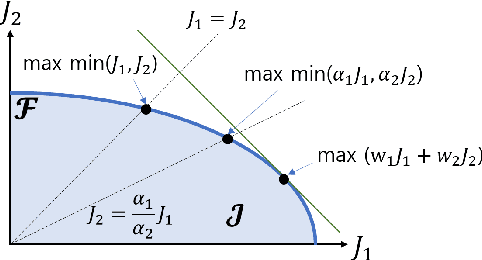
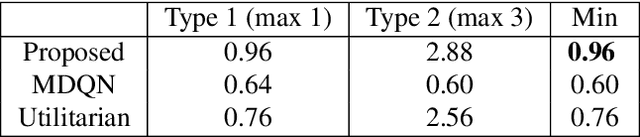
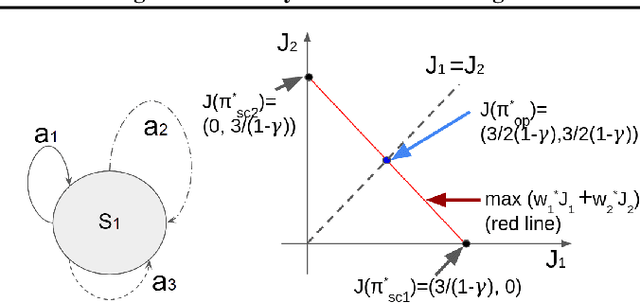
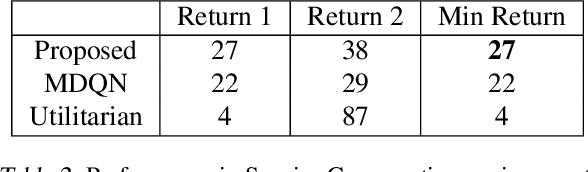
In this paper, we consider multi-objective reinforcement learning, which arises in many real-world problems with multiple optimization goals. We approach the problem with a max-min framework focusing on fairness among the multiple goals and develop a relevant theory and a practical model-free algorithm under the max-min framework. The developed theory provides a theoretical advance in multi-objective reinforcement learning, and the proposed algorithm demonstrates a notable performance improvement over existing baseline methods.
Value-Aided Conditional Supervised Learning for Offline RL
Feb 03, 2024Offline reinforcement learning (RL) has seen notable advancements through return-conditioned supervised learning (RCSL) and value-based methods, yet each approach comes with its own set of practical challenges. Addressing these, we propose Value-Aided Conditional Supervised Learning (VCS), a method that effectively synergizes the stability of RCSL with the stitching ability of value-based methods. Based on the Neural Tangent Kernel analysis to discern instances where value function may not lead to stable stitching, VCS injects the value aid into the RCSL's loss function dynamically according to the trajectory return. Our empirical studies reveal that VCS not only significantly outperforms both RCSL and value-based methods but also consistently achieves, or often surpasses, the highest trajectory returns across diverse offline RL benchmarks. This breakthrough in VCS paves new paths in offline RL, pushing the limits of what can be achieved and fostering further innovations.
Domain Adaptive Imitation Learning with Visual Observation
Dec 01, 2023In this paper, we consider domain-adaptive imitation learning with visual observation, where an agent in a target domain learns to perform a task by observing expert demonstrations in a source domain. Domain adaptive imitation learning arises in practical scenarios where a robot, receiving visual sensory data, needs to mimic movements by visually observing other robots from different angles or observing robots of different shapes. To overcome the domain shift in cross-domain imitation learning with visual observation, we propose a novel framework for extracting domain-independent behavioral features from input observations that can be used to train the learner, based on dual feature extraction and image reconstruction. Empirical results demonstrate that our approach outperforms previous algorithms for imitation learning from visual observation with domain shift.
Sample-Efficient and Safe Deep Reinforcement Learning via Reset Deep Ensemble Agents
Oct 31, 2023



Deep reinforcement learning (RL) has achieved remarkable success in solving complex tasks through its integration with deep neural networks (DNNs) as function approximators. However, the reliance on DNNs has introduced a new challenge called primacy bias, whereby these function approximators tend to prioritize early experiences, leading to overfitting. To mitigate this primacy bias, a reset method has been proposed, which performs periodic resets of a portion or the entirety of a deep RL agent while preserving the replay buffer. However, the use of the reset method can result in performance collapses after executing the reset, which can be detrimental from the perspective of safe RL and regret minimization. In this paper, we propose a new reset-based method that leverages deep ensemble learning to address the limitations of the vanilla reset method and enhance sample efficiency. The proposed method is evaluated through various experiments including those in the domain of safe RL. Numerical results show its effectiveness in high sample efficiency and safety considerations.
Decision ConvFormer: Local Filtering in MetaFormer is Sufficient for Decision Making
Oct 06, 2023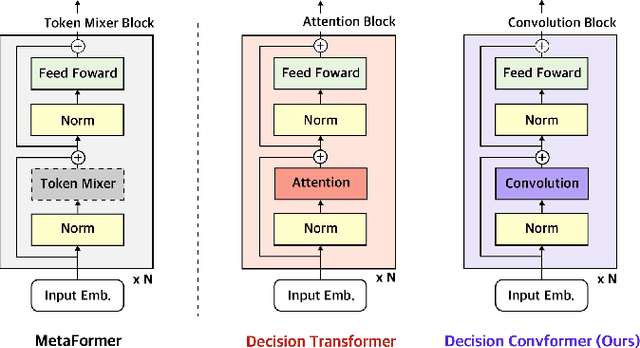
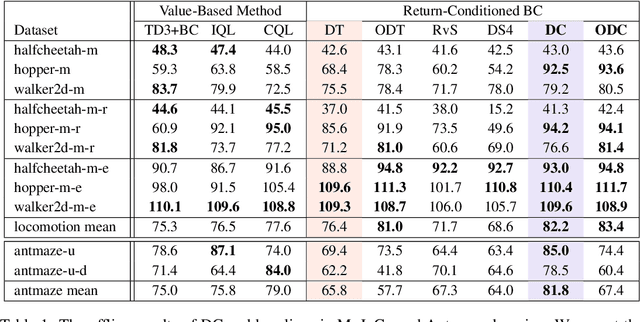
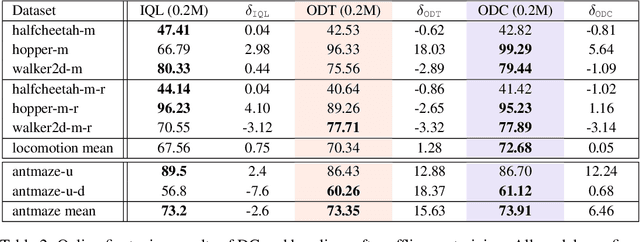
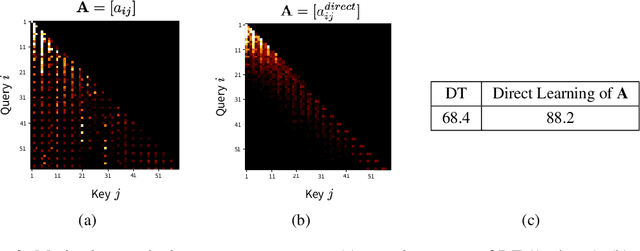
The recent success of Transformer in natural language processing has sparked its use in various domains. In offline reinforcement learning (RL), Decision Transformer (DT) is emerging as a promising model based on Transformer. However, we discovered that the attention module of DT is not appropriate to capture the inherent local dependence pattern in trajectories of RL modeled as a Markov decision process. To overcome the limitations of DT, we propose a novel action sequence predictor, named Decision ConvFormer (DC), based on the architecture of MetaFormer, which is a general structure to process multiple entities in parallel and understand the interrelationship among the multiple entities. DC employs local convolution filtering as the token mixer and can effectively capture the inherent local associations of the RL dataset. In extensive experiments, DC achieved state-of-the-art performance across various standard RL benchmarks while requiring fewer resources. Furthermore, we show that DC better understands the underlying meaning in data and exhibits enhanced generalization capability.
LESSON: Learning to Integrate Exploration Strategies for Reinforcement Learning via an Option Framework
Oct 05, 2023In this paper, a unified framework for exploration in reinforcement learning (RL) is proposed based on an option-critic model. The proposed framework learns to integrate a set of diverse exploration strategies so that the agent can adaptively select the most effective exploration strategy over time to realize a relevant exploration-exploitation trade-off for each given task. The effectiveness of the proposed exploration framework is demonstrated by various experiments in the MiniGrid and Atari environments.