 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating a digital poet
Feb 18, 2026Can a machine write good poetry? Any positive answer raises fundamental questions about the nature and value of art. We report a seven-month poetry workshop in which a large language model was shaped into a digital poet through iterative in-context expert feedback, without retraining. Across sessions, the model developed a distinctive style and a coherent corpus, supported by quantitative and qualitative analyses, and it produced a pen name and author image. In a blinded authorship test with 50 humanities students and graduates (three AI poems and three poems by well-known poets each), judgments were at chance: human poems were labeled human 54% of the time and AI poems 52%, with 95% confidence intervals including 50%. After the workshop, a commercial publisher released a poetry collection authored by the model. These results show that workshop-style prompting can support long-horizon creative shaping and renew debates on creativity and authorship.
The Max-Min Formulation of Multi-Objective Reinforcement Learning: From Theory to a Model-Free Algorithm
Jun 12, 2024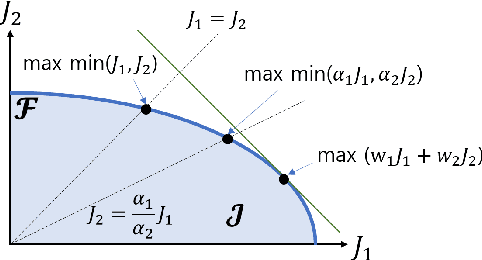
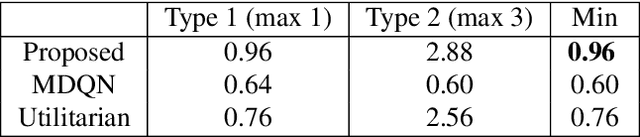
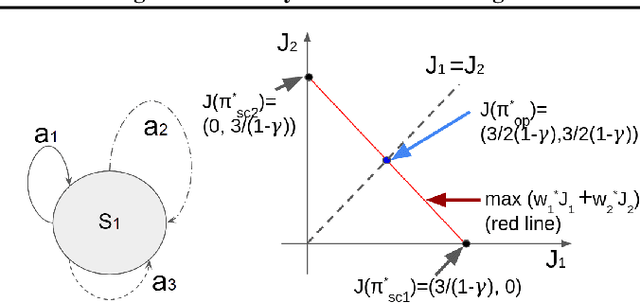
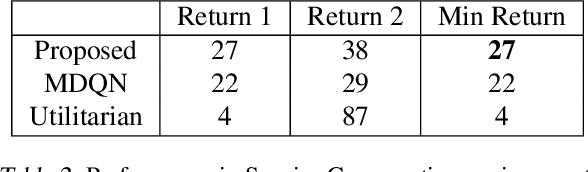
In this paper, we consider multi-objective reinforcement learning, which arises in many real-world problems with multiple optimization goals. We approach the problem with a max-min framework focusing on fairness among the multiple goals and develop a relevant theory and a practical model-free algorithm under the max-min framework. The developed theory provides a theoretical advance in multi-objective reinforcement learning, and the proposed algorithm demonstrates a notable performance improvement over existing baseline methods.
Two-Stage Resource Allocation in Reconfigurable Intelligent Surface Assisted Hybrid Networks via Multi-Player Bandits
Jun 09, 2024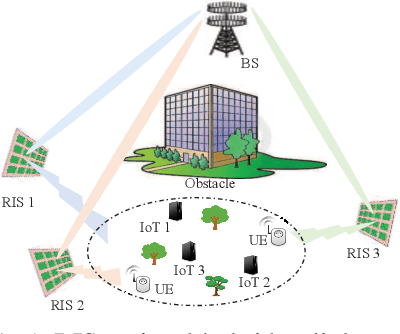
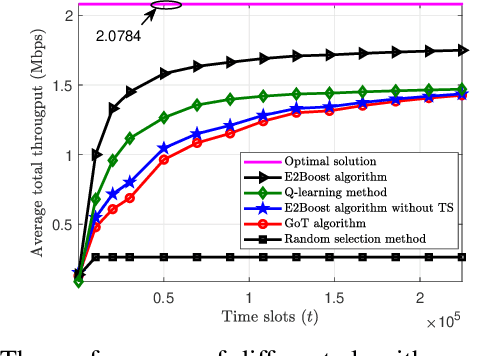
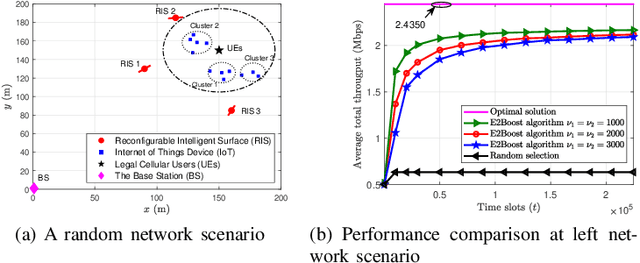
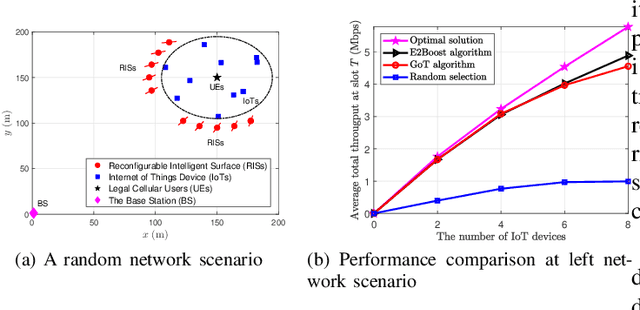
This paper considers a resource allocation problem where several Internet-of-Things (IoT) devices send data to a base station (BS) with or without the help of the reconfigurable intelligent surface (RIS) assisted cellular network. The objective is to maximize the sum rate of all IoT devices by finding the optimal RIS and spreading factor (SF) for each device. Since these IoT devices lack prior information on the RISs or the channel state information (CSI), a distributed resource allocation framework with low complexity and learning features is required to achieve this goal. Therefore, we model this problem as a two-stage multi-player multi-armed bandit (MPMAB) framework to learn the optimal RIS and SF sequentially. Then, we put forth an exploration and exploitation boosting (E2Boost) algorithm to solve this two-stage MPMAB problem by combining the $\epsilon$-greedy algorithm, Thompson sampling (TS) algorithm, and non-cooperation game method. We derive an upper regret bound for the proposed algorithm, i.e., $\mathcal{O}(\log^{1+\delta}_2 T)$, increasing logarithmically with the time horizon $T$. Numerical results show that the E2Boost algorithm has the best performance among the existing methods and exhibits a fast convergence rate. More importantly, the proposed algorithm is not sensitive to the number of combinations of the RISs and SFs thanks to the two-stage allocation mechanism, which can benefit high-density networks.
Mitigating Data Injection Attacks on Federated Learning
Dec 04, 2023
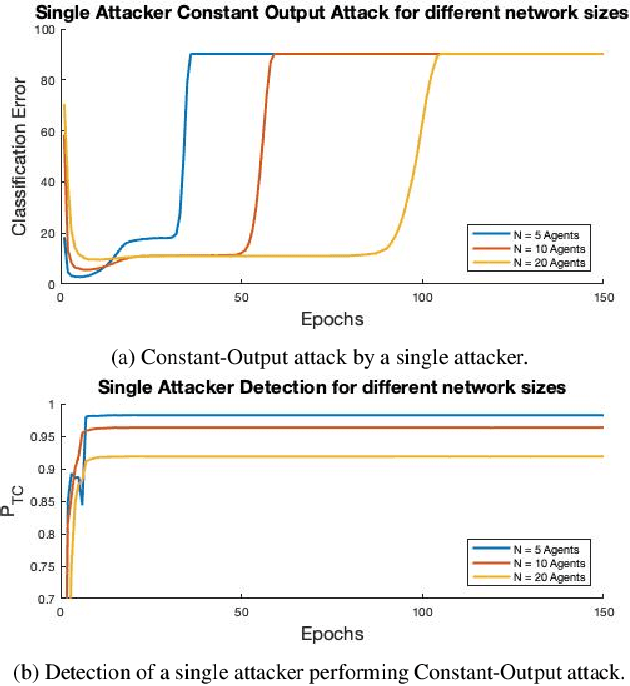
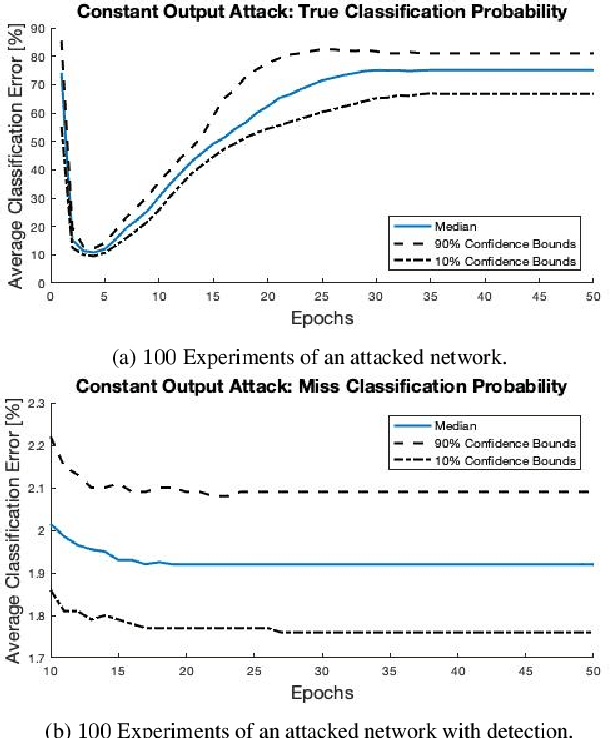
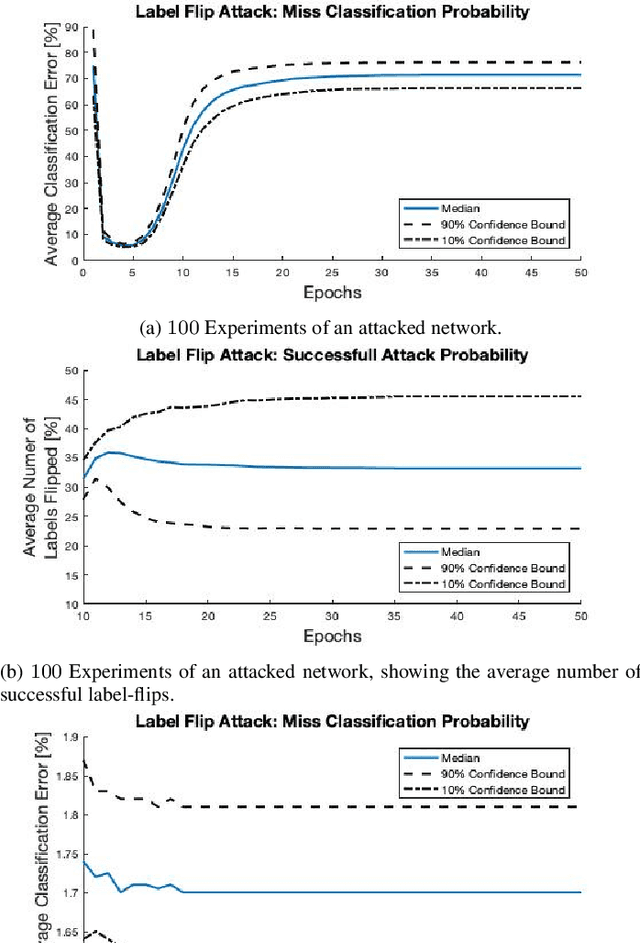
Federated learning is a technique that allows multiple entities to collaboratively train models using their data without compromising data privacy. However, despite its advantages, federated learning can be susceptible to false data injection attacks. In these scenarios, a malicious entity with control over specific agents in the network can manipulate the learning process, leading to a suboptimal model. Consequently, addressing these data injection attacks presents a significant research challenge in federated learning systems. In this paper, we propose a novel technique to detect and mitigate data injection attacks on federated learning systems. Our mitigation method is a local scheme, performed during a single instance of training by the coordinating node, allowing the mitigation during the convergence of the algorithm. Whenever an agent is suspected to be an attacker, its data will be ignored for a certain period, this decision will often be re-evaluated. We prove that with probability 1, after a finite time, all attackers will be ignored while the probability of ignoring a trustful agent becomes 0, provided that there is a majority of truthful agents. Simulations show that when the coordinating node detects and isolates all the attackers, the model recovers and converges to the truthful model.
Random Access Protocols for Cell-Free Wireless Network Exploiting Statistical Behavior of THz Signal Propagation
Nov 10, 2023The current body of research on terahertz (THz) wireless communications predominantly focuses on its application for single-user backhaul/fronthaul connectivity at sub-THz frequencies. First, we develop a generalized statistical model for signal propagation at THz frequencies encompassing physical layer impairments, including random path-loss with Gamma distribution for the molecular absorption coefficient, short-term fading characterized by the $\alpha$-$\eta$-$\kappa$-$\mu$ distribution, antenna misalignment errors, and transceiver hardware impairments. Next, we propose random access protocols for a cell-free wireless network, ensuring successful transmission for multiple users with limited delay and energy loss, exploiting the combined effect of random atmospheric absorption, non-linearity of fading, hardware impairments, and antenna misalignment errors. We consider two schemes: a fixed transmission probability (FTP) scheme where the transmission probability (TP) of each user is updated at the beginning of the data transmission and an adaptive transmission probability (ATP) scheme where the TP is updated with each successful reception of the data. We analyze the performance of both protocols using delay, energy consumption, and outage probability with scaling laws for the transmission of a data frame consisting of a single packet from users at a predefined quality of service (QoS).
Optimal Fair Multi-Agent Bandits
Jun 07, 2023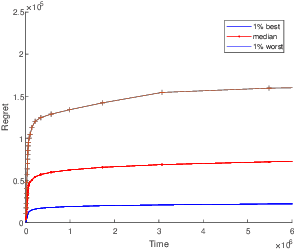
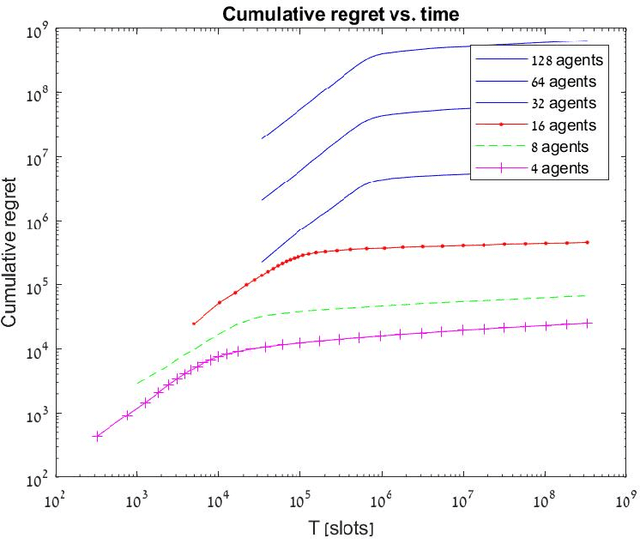
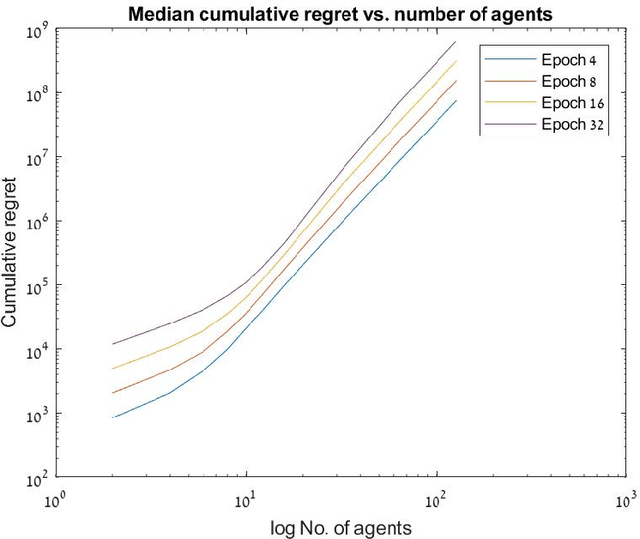
In this paper, we study the problem of fair multi-agent multi-arm bandit learning when agents do not communicate with each other, except collision information, provided to agents accessing the same arm simultaneously. We provide an algorithm with regret $O\left(N^3 \log N \log T \right)$ (assuming bounded rewards, with unknown bound). This significantly improves previous results which had regret of order $O(\log T \log\log T)$ and exponential dependence on the number of agents. The result is attained by using a distributed auction algorithm to learn the sample-optimal matching, a new type of exploitation phase whose length is derived from the observed samples, and a novel order-statistics-based regret analysis. Simulation results present the dependence of the regret on $\log T$.
Communication Efficient Distributed Learning over Wireless Channels
Sep 04, 2022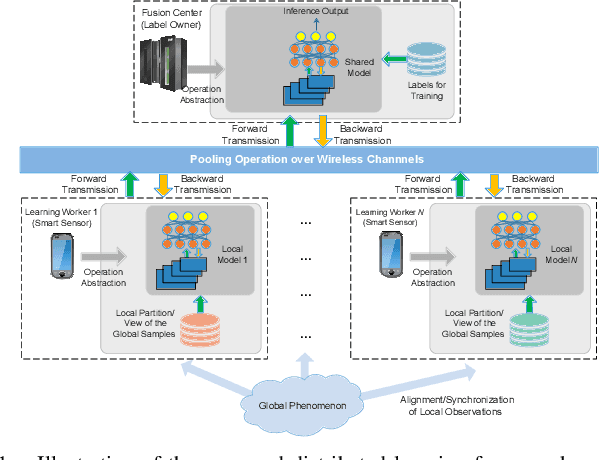
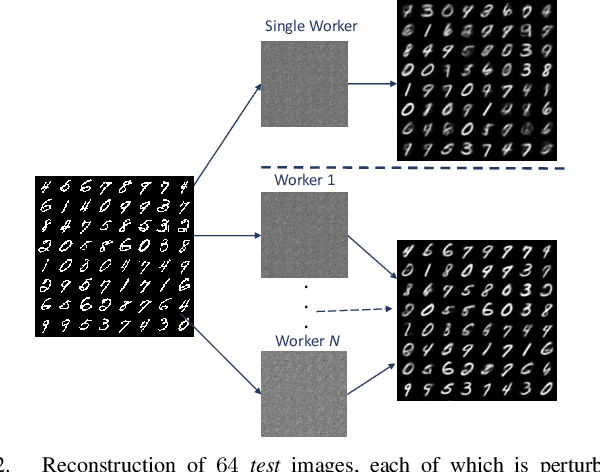
Vertical distributed learning exploits the local features collected by multiple learning workers to form a better global model. However, the exchange of data between the workers and the model aggregator for parameter training incurs a heavy communication burden, especially when the learning system is built upon capacity-constrained wireless networks. In this paper, we propose a novel hierarchical distributed learning framework, where each worker separately learns a low-dimensional embedding of their local observed data. Then, they perform communication efficient distributed max-pooling for efficiently transmitting the synthesized input to the aggregator. For data exchange over a shared wireless channel, we propose an opportunistic carrier sensing-based protocol to implement the max-pooling operation for the output data from all the learning workers. Our simulation experiments show that the proposed learning framework is able to achieve almost the same model accuracy as the learning model using the concatenation of all the raw outputs from the learning workers, while requiring a communication load that is independent of the number of workers.
Medium Access Control protocol for Collaborative Spectrum Learning in Wireless Networks
Oct 25, 2021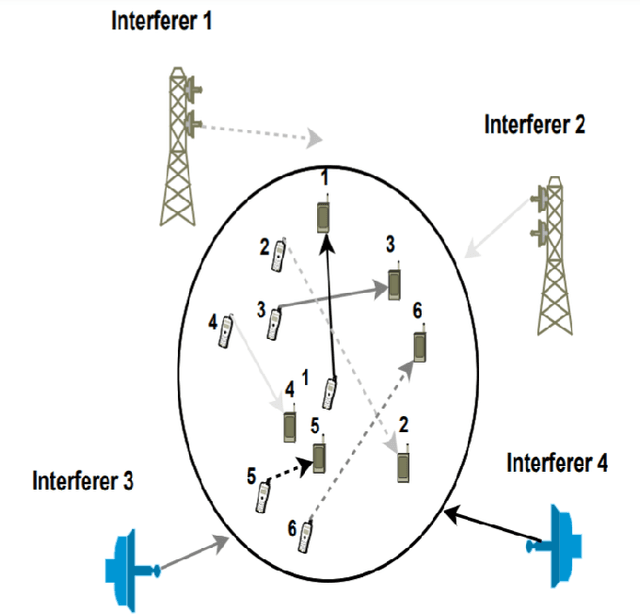
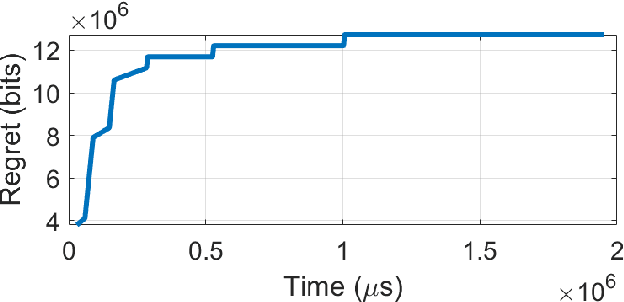
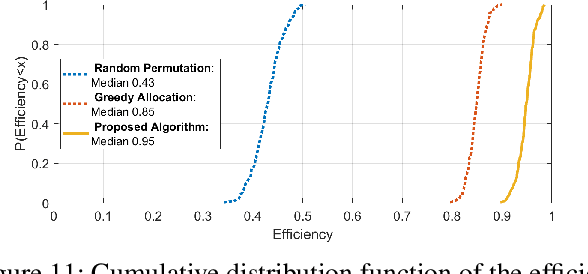
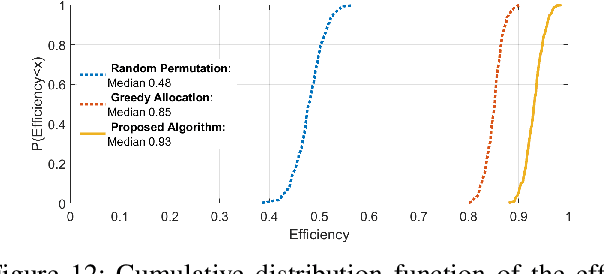
In recent years there is a growing effort to provide learning algorithms for spectrum collaboration. In this paper we present a medium access control protocol which allows spectrum collaboration with minimal regret and high spectral efficiency in highly loaded networks. We present a fully-distributed algorithm for spectrum collaboration in congested ad-hoc networks. The algorithm jointly solves both the channel allocation and access scheduling problems. We prove that the algorithm has an optimal logarithmic regret. Based on the algorithm we provide a medium access control protocol which allows distributed implementation of the algorithm in ad-hoc networks. The protocol utilizes single-channel opportunistic carrier sensing to carry out a low-complexity distributed auction in time and frequency. We also discuss practical implementation issues such as bounded frame size and speed of convergence. Computer simulations comparing the algorithm to state-of-the-art distributed medium access control protocols show the significant advantage of the proposed scheme.
Distributed Deep Reinforcement Learning for Collaborative Spectrum Sharing
Apr 06, 2021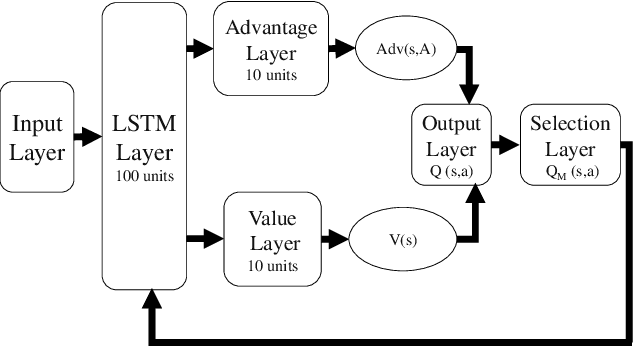
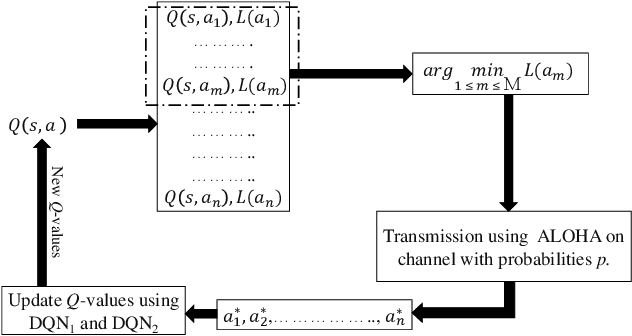
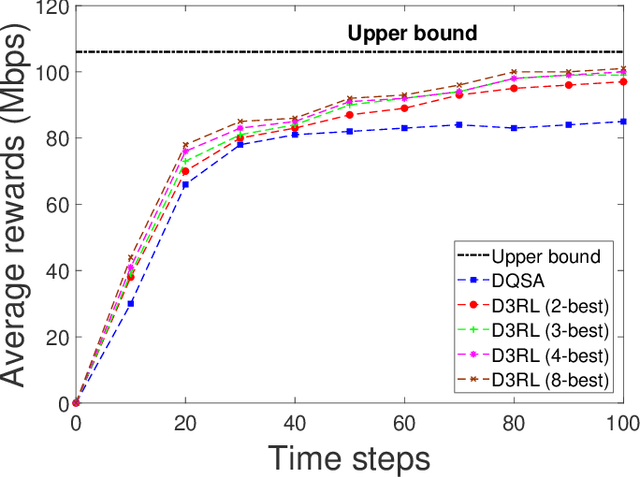
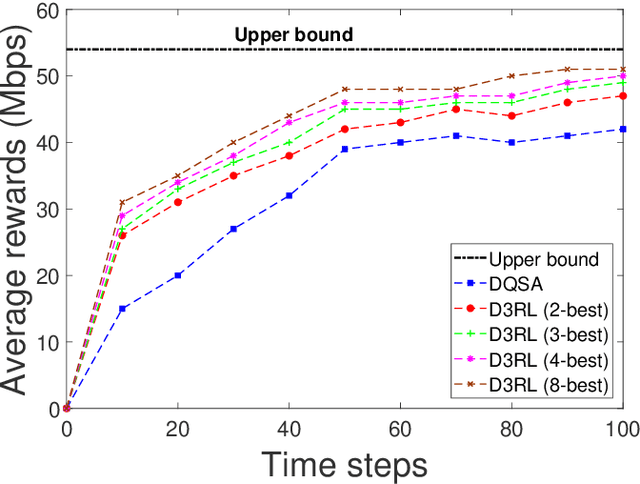
Spectrum sharing among users is a fundamental problem in the management of any wireless network. In this paper, we discuss the problem of distributed spectrum collaboration without central management under general unknown channels. Since the cost of communication, coordination and control is rapidly increasing with the number of devices and the expanding bandwidth used there is an obvious need to develop distributed techniques for spectrum collaboration where no explicit signaling is used. In this paper, we combine game-theoretic insights with deep Q-learning to provide a novel asymptotically optimal solution to the spectrum collaboration problem. We propose a deterministic distributed deep reinforcement learning(D3RL) mechanism using a deep Q-network (DQN). It chooses the channels using the Q-values and the channel loads while limiting the options available to the user to a few channels with the highest Q-values and among those, it selects the least loaded channel. Using insights from both game theory and combinatorial optimization we show that this technique is asymptotically optimal for large overloaded networks. The selected channel and the outcome of the successful transmission are fed back into the learning of the deep Q-network to incorporate it into the learning of the Q-values. We also analyzed performance to understand the behavior of D3RL in differ
My Fair Bandit: Distributed Learning of Max-Min Fairness with Multi-player Bandits
Aug 21, 2020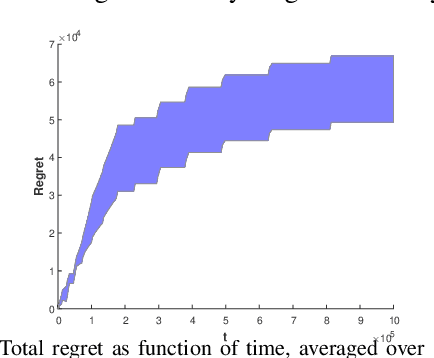
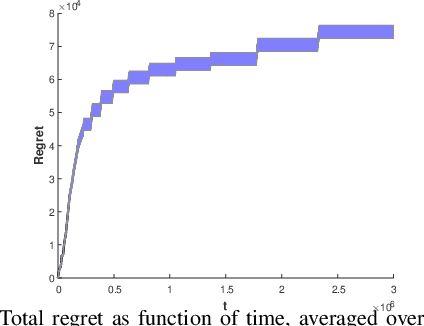
Consider N cooperative but non-communicating players where each plays one out of M arms for T turns. Players have different utilities for each arm, representable as an NxM matrix. These utilities are unknown to the players. In each turn players select an arm and receive a noisy observation of their utility for it. However, if any other players selected the same arm that turn, all colliding players will all receive zero utility due to the conflict. No other communication or coordination between the players is possible. Our goal is to design a distributed algorithm that learns the matching between players and arms that achieves max-min fairness while minimizing the regret. We present an algorithm and prove that it is regret optimal up to a $\log\log T$ factor. This is the first max-min fairness multi-player bandit algorithm with (near) order optimal regret.