 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeavy-Tailed and Long-Range Dependent Noise in Stochastic Approximation: A Finite-Time Analysis
Mar 20, 2026Stochastic approximation (SA) is a fundamental iterative framework with broad applications in reinforcement learning and optimization. Classical analyses typically rely on martingale difference or Markov noise with bounded second moments, but many practical settings, including finance and communications, frequently encounter heavy-tailed and long-range dependent (LRD) noise. In this work, we study SA for finding the root of a strongly monotone operator under these non-classical noise models. We establish the first finite-time moment bounds in both settings, providing explicit convergence rates that quantify the impact of heavy tails and temporal dependence. Our analysis employs a noise-averaging argument that regularizes the impact of noise without modifying the iteration. Finally, we apply our general framework to stochastic gradient descent (SGD) and gradient play, and corroborate our finite-time analysis through numerical experiments.
High-Probability Bounds for SGD under the Polyak-Lojasiewicz Condition with Markovian Noise
Mar 15, 2026We present the first uniform-in-time high-probability bound for SGD under the PL condition, where the gradient noise contains both Markovian and martingale difference components. This significantly broadens the scope of finite-time guarantees, as the PL condition arises in many machine learning and deep learning models while Markovian noise naturally arises in decentralized optimization and online system identification problems. We further allow the magnitude of noise to grow with the function value, enabling the analysis of many practical sampling strategies. In addition to the high-probability guarantee, we establish a matching $1/k$ decay rate for the expected suboptimality. Our proof technique relies on the Poisson equation to handle the Markovian noise and a probabilistic induction argument to address the lack of almost-sure bounds on the objective. Finally, we demonstrate the applicability of our framework by analyzing three practical optimization problems: token-based decentralized linear regression, supervised learning with subsampling for privacy amplification, and online system identification.
Regret and Sample Complexity of Online Q-Learning via Concentration of Stochastic Approximation with Time-Inhomogeneous Markov Chains
Feb 18, 2026We present the first high-probability regret bound for classical online Q-learning in infinite-horizon discounted Markov decision processes, without relying on optimism or bonus terms. We first analyze Boltzmann Q-learning with decaying temperature and show that its regret depends critically on the suboptimality gap of the MDP: for sufficiently large gaps, the regret is sublinear, while for small gaps it deteriorates and can approach linear growth. To address this limitation, we study a Smoothed $ε_n$-Greedy exploration scheme that combines $ε_n$-greedy and Boltzmann exploration, for which we prove a gap-robust regret bound of near-$\tilde{O}(N^{9/10})$. To analyze these algorithms, we develop a high-probability concentration bound for contractive Markovian stochastic approximation with iterate- and time-dependent transition dynamics. This bound may be of independent interest as the contraction factor in our bound is governed by the mixing time and is allowed to converge to one asymptotically.
Robust equilibria in continuous games: From strategic to dynamic robustness
Dec 09, 2025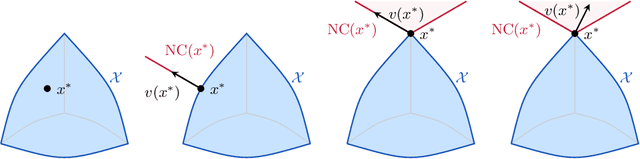
In this paper, we examine the robustness of Nash equilibria in continuous games, under both strategic and dynamic uncertainty. Starting with the former, we introduce the notion of a robust equilibrium as those equilibria that remain invariant to small -- but otherwise arbitrary -- perturbations to the game's payoff structure, and we provide a crisp geometric characterization thereof. Subsequently, we turn to the question of dynamic robustness, and we examine which equilibria may arise as stable limit points of the dynamics of "follow the regularized leader" (FTRL) in the presence of randomness and uncertainty. Despite their very distinct origins, we establish a structural correspondence between these two notions of robustness: strategic robustness implies dynamic robustness, and, conversely, the requirement of strategic robustness cannot be relaxed if dynamic robustness is to be maintained. Finally, we examine the rate of convergence to robust equilibria as a function of the underlying regularizer, and we show that entropically regularized learning converges at a geometric rate in games with affinely constrained action spaces.
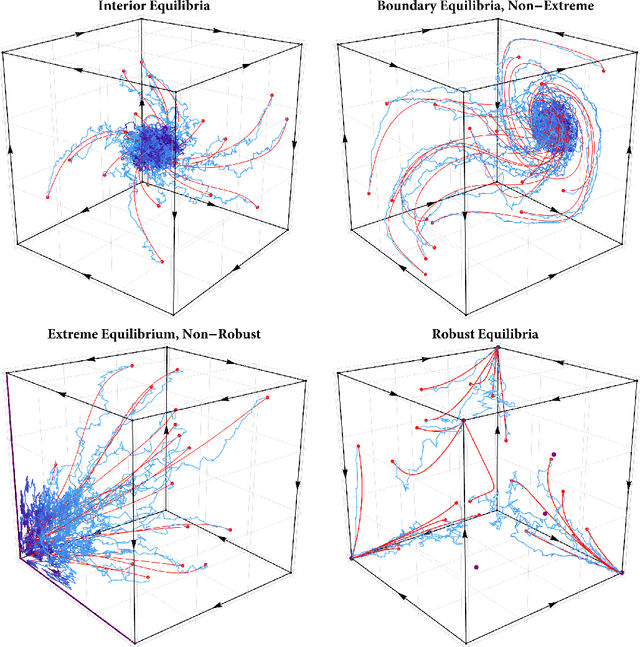
Multi-agent learning under uncertainty: Recurrence vs. concentration
Dec 09, 2025In this paper, we examine the convergence landscape of multi-agent learning under uncertainty. Specifically, we analyze two stochastic models of regularized learning in continuous games -- one in continuous and one in discrete time with the aim of characterizing the long-run behavior of the induced sequence of play. In stark contrast to deterministic, full-information models of learning (or models with a vanishing learning rate), we show that the resulting dynamics do not converge in general. In lieu of this, we ask instead which actions are played more often in the long run, and by how much. We show that, in strongly monotone games, the dynamics of regularized learning may wander away from equilibrium infinitely often, but they always return to its vicinity in finite time (which we estimate), and their long-run distribution is sharply concentrated around a neighborhood thereof. We quantify the degree of this concentration, and we show that these favorable properties may all break down if the underlying game is not strongly monotone -- underscoring in this way the limits of regularized learning in the presence of persistent randomness and uncertainty.
Accelerated regularized learning in finite N-person games
Dec 29, 2024Motivated by the success of Nesterov's accelerated gradient algorithm for convex minimization problems, we examine whether it is possible to achieve similar performance gains in the context of online learning in games. To that end, we introduce a family of accelerated learning methods, which we call "follow the accelerated leader" (FTXL), and which incorporates the use of momentum within the general framework of regularized learning - and, in particular, the exponential/multiplicative weights algorithm and its variants. Drawing inspiration and techniques from the continuous-time analysis of Nesterov's algorithm, we show that FTXL converges locally to strict Nash equilibria at a superlinear rate, achieving in this way an exponential speed-up over vanilla regularized learning methods (which, by comparison, converge to strict equilibria at a geometric, linear rate). Importantly, FTXL maintains its superlinear convergence rate in a broad range of feedback structures, from deterministic, full information models to stochastic, realization-based ones, and even when run with bandit, payoff-based information, where players are only able to observe their individual realized payoffs.
Learning to Control Unknown Strongly Monotone Games
Jun 30, 2024


Consider $N$ players each with a $d$-dimensional action set. Each of the players' utility functions includes their reward function and a linear term for each dimension, with coefficients that are controlled by the manager. We assume that the game is strongly monotone, so if each player runs gradient descent, the dynamics converge to a unique Nash equilibrium (NE). The NE is typically inefficient in terms of global performance. The resulting global performance of the system can be improved by imposing $K$-dimensional linear constraints on the NE. We therefore want the manager to pick the controlled coefficients that impose the desired constraint on the NE. However, this requires knowing the players' reward functions and their action sets. Obtaining this game structure information is infeasible in a large-scale network and violates the users' privacy. To overcome this, we propose a simple algorithm that learns to shift the NE of the game to meet the linear constraints by adjusting the controlled coefficients online. Our algorithm only requires the linear constraints violation as feedback and does not need to know the reward functions or the action sets. We prove that our algorithm, which is based on two time-scale stochastic approximation, guarantees convergence with probability 1 to the set of NE that meet target linear constraints. We then provide a mean square convergence rate of $O(t^{-1/4})$ for our algorithm. This is the first such bound for two time-scale stochastic approximation where the slower time-scale is a fixed point iteration with a non-expansive mapping. We demonstrate how our scheme can be applied to optimizing a global quadratic cost at NE and load balancing in resource allocation games. We provide simulations of our algorithm for these scenarios.
Payoff-based learning with matrix multiplicative weights in quantum games
Nov 04, 2023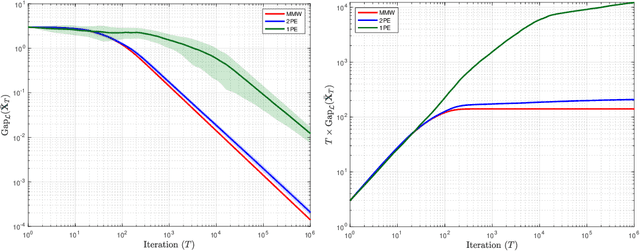
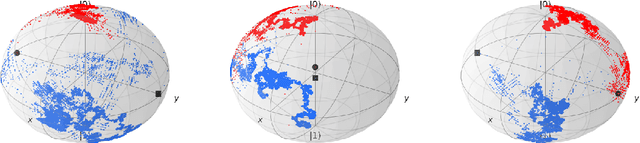
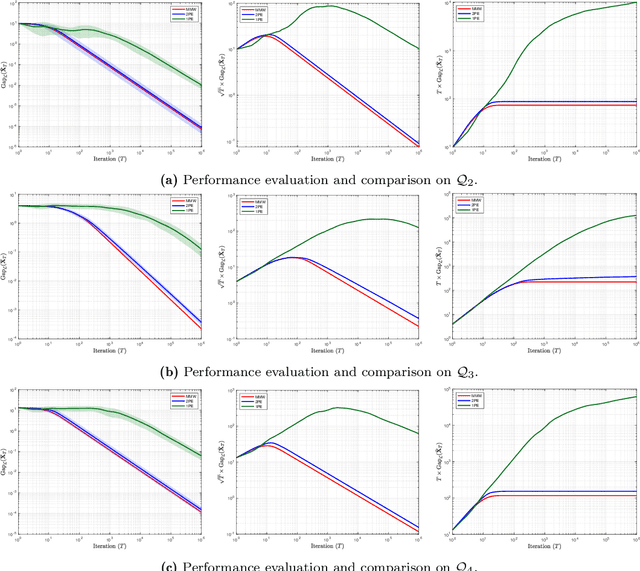
In this paper, we study the problem of learning in quantum games - and other classes of semidefinite games - with scalar, payoff-based feedback. For concreteness, we focus on the widely used matrix multiplicative weights (MMW) algorithm and, instead of requiring players to have full knowledge of the game (and/or each other's chosen states), we introduce a suite of minimal-information matrix multiplicative weights (3MW) methods tailored to different information frameworks. The main difficulty to attaining convergence in this setting is that, in contrast to classical finite games, quantum games have an infinite continuum of pure states (the quantum equivalent of pure strategies), so standard importance-weighting techniques for estimating payoff vectors cannot be employed. Instead, we borrow ideas from bandit convex optimization and we design a zeroth-order gradient sampler adapted to the semidefinite geometry of the problem at hand. As a first result, we show that the 3MW method with deterministic payoff feedback retains the $\mathcal{O}(1/\sqrt{T})$ convergence rate of the vanilla, full information MMW algorithm in quantum min-max games, even though the players only observe a single scalar. Subsequently, we relax the algorithm's information requirements even further and we provide a 3MW method that only requires players to observe a random realization of their payoff observable, and converges to equilibrium at an $\mathcal{O}(T^{-1/4})$ rate. Finally, going beyond zero-sum games, we show that a regularized variant of the proposed 3MW method guarantees local convergence with high probability to all equilibria that satisfy a certain first-order stability condition.
Equilibrium Bandits: Learning Optimal Equilibria of Unknown Dynamics
Feb 27, 2023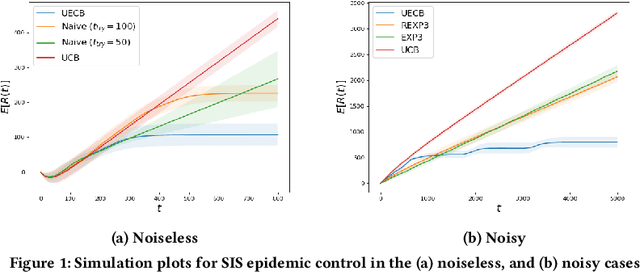
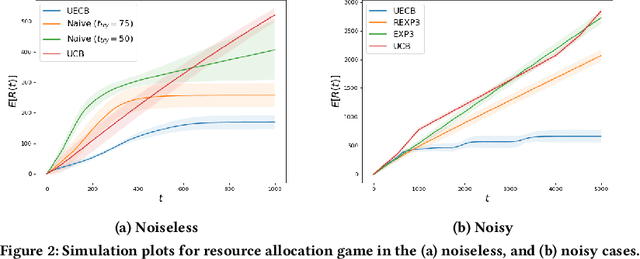
Consider a decision-maker that can pick one out of $K$ actions to control an unknown system, for $T$ turns. The actions are interpreted as different configurations or policies. Holding the same action fixed, the system asymptotically converges to a unique equilibrium, as a function of this action. The dynamics of the system are unknown to the decision-maker, which can only observe a noisy reward at the end of every turn. The decision-maker wants to maximize its accumulated reward over the $T$ turns. Learning what equilibria are better results in higher rewards, but waiting for the system to converge to equilibrium costs valuable time. Existing bandit algorithms, either stochastic or adversarial, achieve linear (trivial) regret for this problem. We present a novel algorithm, termed Upper Equilibrium Concentration Bound (UECB), that knows to switch an action quickly if it is not worth it to wait until the equilibrium is reached. This is enabled by employing convergence bounds to determine how far the system is from equilibrium. We prove that UECB achieves a regret of $\mathcal{O}(\log(T)+\tau_c\log(\tau_c)+\tau_c\log\log(T))$ for this equilibrium bandit problem where $\tau_c$ is the worst case approximate convergence time to equilibrium. We then show that both epidemic control and game control are special cases of equilibrium bandits, where $\tau_c\log \tau_c$ typically dominates the regret. We then test UECB numerically for both of these applications.
Learning in quantum games
Feb 05, 2023In this paper, we introduce a class of learning dynamics for general quantum games, that we call "follow the quantum regularized leader" (FTQL), in reference to the classical "follow the regularized leader" (FTRL) template for learning in finite games. We show that the induced quantum state dynamics decompose into (i) a classical, commutative component which governs the dynamics of the system's eigenvalues in a way analogous to the evolution of mixed strategies under FTRL; and (ii) a non-commutative component for the system's eigenvectors which has no classical counterpart. Despite the complications that this non-classical component entails, we find that the FTQL dynamics incur no more than constant regret in all quantum games. Moreover, adjusting classical notions of stability to account for the nonlinear geometry of the state space of quantum games, we show that only pure quantum equilibria can be stable and attracting under FTQL while, as a partial converse, pure equilibria that satisfy a certain "variational stability" condition are always attracting. Finally, we show that the FTQL dynamics are Poincar\'e recurrent in quantum min-max games, extending in this way a very recent result for the quantum replicator dynamics.