 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference for Stochastic Gradient Descent Beyond Finite Variance
May 25, 2026Stochastic gradient descent (SGD) is a foundational algorithm for large-scale statistical learning and stochastic optimization. However, statistical inference based on SGD iterates remains challenging when stochastic gradients have infinite variance, as the relevant limiting distributions depend on unknown nuisance parameters. In this paper, we develop an efficient, model-agnostic methodology for constructing confidence regions from SGD trajectories that applies in both finite- and infinite-variance regimes. The procedure is based on a joint weak convergence result for the Polyak-Ruppert averaged estimator and an empirical second-moment normalizer constructed from stochastic gradients along the SGD trajectory. This joint limit yields a self-normalized statistic in which the leading tail-dependent scaling terms cancel. We then use a subsampling calibration scheme to estimate the relevant critical values, avoiding explicit estimation of tail indices, slowly varying functions, or stable-law parameters. The resulting confidence regions are straightforward to implement and are asymptotically valid under both the finite- and infinite-second-moment regimes. Simulation studies show reliable coverage in various settings, supporting the proposed method as a practical tool for uncertainty quantification in stochastic optimization.
Fast Convergence of Policy Regret in Learning Stochastic Optimal Control
May 25, 2026Policy learning in modern operations environments faces a fundamental tension between limited operational data and the large, often continuous, state and action spaces over which good decisions must be identified and deployed. We study value-based policy learning in stochastic optimal control: a greedy policy induced by an estimate of the optimal action-value function $Q^*$ is deployed, and its performance is measured by regret. The empirical success of this approach calls for statistical insight into the structures that enable fast regret convergence. We show that, in continuous action spaces, fast policy learning is induced by three geometric structures: a growth exponent $p$, which quantifies how quickly $Q^*$ separates suboptimal actions from its maximizers; a margin-mass exponent $m$, which controls how much deployment mass lies on states with weak growth; and an action-wise regularity exponent $q$, which measures the smoothness of the $Q^*$-estimation error across actions. Given a $n^{-1/2}$-accurate estimator of $Q^*$, we show that the minimax-optimal policy regret convergence rate is \[ \widetildeΘ\left( n^{-\min\left\{\frac{p}{2(p-q)},\frac{m+1}{2m}\right\}} \right), \] up to a logarithmic factor at the boundary between the two regimes. The exponent $q$ is crucial: $q>0$ yields faster-than-$n^{-1/2}$ regret. This regime is natural in operations applications. In particular, we verify $q>0$ under mild regularity conditions in dynamic inventory control and service allocation examples, while the mechanism underlying this fast rate regime extends beyond these settings.
A Single-Sample Polylogarithmic Regret Bound for Nonstationary Online Linear Programming
Mar 15, 2026We study nonstationary Online Linear Programming (OLP), where $n$ orders arrive sequentially with reward-resource consumption pairs that form a sequence of independent, but not necessarily identically distributed, random vectors. At the beginning of the planning horizon, the decision-maker is provided with a resource endowment that is sufficient to fulfill a significant portion of the requests. The decision-maker seeks to maximize the expected total reward by making immediate and irrevocable acceptance or rejection decisions for each order, subject to this resource endowment. We focus on the challenging single-sample setting, where only one sample from each of the $n$ distributions is available at the start of the planning horizon. We propose a novel re-solving algorithm that integrates a dynamic programming perspective with the dual-based frameworks traditionally employed in stationary environments. In the large-resource regime, where the resource endowment scales linearly with the number of orders, we prove that our algorithm achieves $O((\log n)^2)$ regret across a broad class of nonstationary distribution sequences. Our results demonstrate that polylogarithmic regret is attainable even under significant environmental shifts and minimal data availability, bridging the gap between stationary OLP and more volatile real-world resource allocation problems.
Deep Learning for Computing Convergence Rates of Markov Chains
May 30, 2024Convergence rate analysis for general state-space Markov chains is fundamentally important in areas such as Markov chain Monte Carlo and algorithmic analysis (for computing explicit convergence bounds). This problem, however, is notoriously difficult because traditional analytical methods often do not generate practically useful convergence bounds for realistic Markov chains. We propose the Deep Contractive Drift Calculator (DCDC), the first general-purpose sample-based algorithm for bounding the convergence of Markov chains to stationarity in Wasserstein distance. The DCDC has two components. First, inspired by the new convergence analysis framework in (Qu et.al, 2023), we introduce the Contractive Drift Equation (CDE), the solution of which leads to an explicit convergence bound. Second, we develop an efficient neural-network-based CDE solver. Equipped with these two components, DCDC solves the CDE and converts the solution into a convergence bound. We analyze the sample complexity of the algorithm and further demonstrate the effectiveness of the DCDC by generating convergence bounds for realistic Markov chains arising from stochastic processing networks as well as constant step-size stochastic optimization.
Optimal Sample Complexity for Average Reward Markov Decision Processes
Oct 13, 2023We settle the sample complexity of policy learning for the maximization of the long run average reward associated with a uniformly ergodic Markov decision process (MDP), assuming a generative model. In this context, the existing literature provides a sample complexity upper bound of $\widetilde O(|S||A|t_{\text{mix}}^2 \epsilon^{-2})$ and a lower bound of $\Omega(|S||A|t_{\text{mix}} \epsilon^{-2})$. In these expressions, $|S|$ and $|A|$ denote the cardinalities of the state and action spaces respectively, $t_{\text{mix}}$ serves as a uniform upper limit for the total variation mixing times, and $\epsilon$ signifies the error tolerance. Therefore, a notable gap of $t_{\text{mix}}$ still remains to be bridged. Our primary contribution is to establish an estimator for the optimal policy of average reward MDPs with a sample complexity of $\widetilde O(|S||A|t_{\text{mix}}\epsilon^{-2})$, effectively reaching the lower bound in the literature. This is achieved by combining algorithmic ideas in Jin and Sidford (2021) with those of Li et al. (2020).
Optimal Sample Complexity of Reinforcement Learning for Uniformly Ergodic Discounted Markov Decision Processes
Feb 16, 2023
We consider the optimal sample complexity theory of tabular reinforcement learning (RL) for controlling the infinite horizon discounted reward in a Markov decision process (MDP). Optimal min-max complexity results have been developed for tabular RL in this setting, leading to a sample complexity dependence on $\gamma$ and $\epsilon$ of the form $\tilde \Theta((1-\gamma)^{-3}\epsilon^{-2})$, where $\gamma$ is the discount factor and $\epsilon$ is the tolerance solution error. However, in many applications of interest, the optimal policy (or all policies) will induce mixing. We show that in these settings the optimal min-max complexity is $\tilde \Theta(t_{\text{minorize}}(1-\gamma)^{-2}\epsilon^{-2})$, where $t_{\text{minorize}}$ is a measure of mixing that is within an equivalent factor of the total variation mixing time. Our analysis is based on regeneration-type ideas, that, we believe are of independent interest since they can be used to study related problems for general state space MDPs.
The Design and Implementation of a Broadly Applicable Algorithm for Optimizing Intra-Day Surgical Scheduling
Mar 14, 2022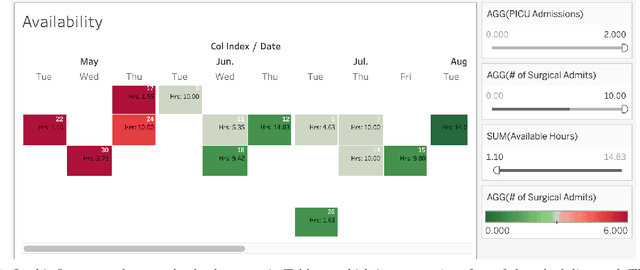


Surgical scheduling optimization is an active area of research. However, few algorithms to optimize surgical scheduling are implemented and see sustained use. An algorithm is more likely to be implemented, if it allows for surgeon autonomy, i.e., requires only limited scheduling centralization, and functions in the limited technical infrastructure of widely used electronic medical records (EMRs). In order for an algorithm to see sustained use, it must be compatible with changes to hospital capacity, patient volumes, and scheduling practices. To meet these objectives, we developed the BEDS (better elective day of surgery) algorithm, a greedy heuristic for smoothing unit-specific surgical admissions across days. We implemented BEDS in the EMR of a large pediatric academic medical center. The use of BEDS was associated with a reduction in the variability in the number of admissions. BEDS is freely available as a dashboard in Tableau, a commercial software used by numerous hospitals. BEDS is readily implementable with the limited tools available to most hospitals, does not require reductions to surgeon autonomy or centralized scheduling, and is compatible with changes to hospital capacity or patient volumes. We present a general algorithmic framework from which BEDS is derived based on a particular choice of objectives and constraints. We argue that algorithms generated by this framework retain many of the desirable characteristics of BEDS while being compatible with a wide range of objectives and constraints.
Surgical Scheduling via Optimization and Machine Learning with Long-Tailed Data
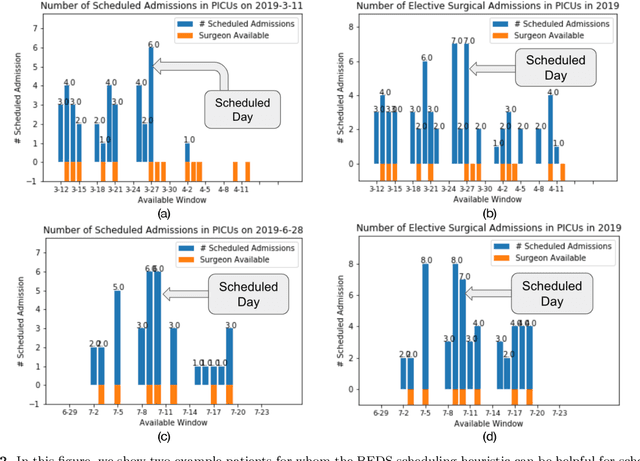
Feb 13, 2022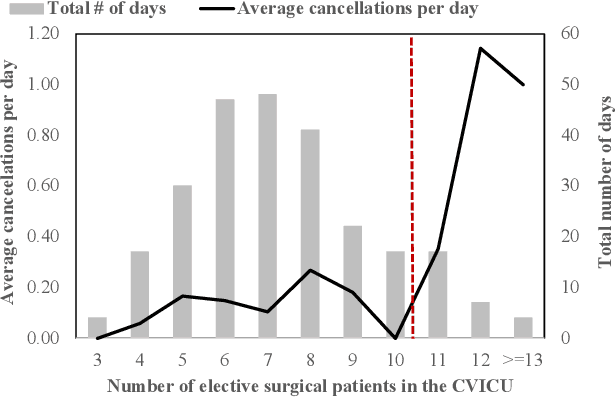
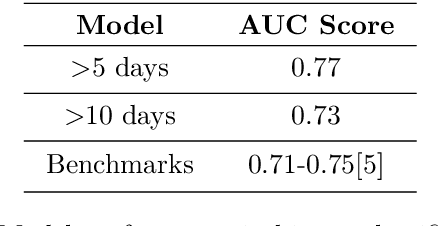
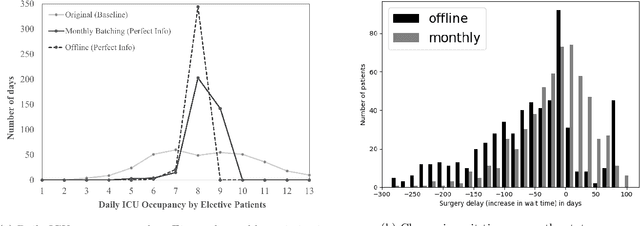
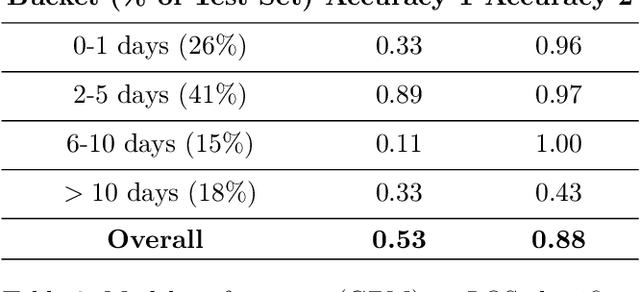
Using data from cardiovascular surgery patients with long and highly variable post-surgical lengths of stay (LOS), we develop a model to reduce recovery unit congestion. We estimate LOS using a variety of machine learning models, schedule procedures with a variety of online optimization models, and estimate performance with simulation. The machine learning models achieved only modest LOS prediction accuracy, despite access to a very rich set of patient characteristics. Compared to the current paper-based system used in the hospital, most optimization models failed to reduce congestion without increasing wait times for surgery. A conservative stochastic optimization with sufficient sampling to capture the long tail of the LOS distribution outperformed the current manual process. These results highlight the perils of using oversimplified distributional models of patient length of stay for scheduling procedures and the importance of using stochastic optimization well-suited to dealing with long-tailed behavior.
Optimal best arm selection for general distributions
Aug 24, 2019Given a finite set of unknown distributions $\textit{or arms}$ that can be sampled from, we consider the problem of identifying the one with the largest mean using a delta-correct algorithm (an adaptive, sequential algorithm that restricts the probability of error to a specified delta) that has minimum sample complexity. Lower bounds for delta-correct algorithms are well known. Further, delta-correct algorithms that match the lower bound asymptotically as delta reduces to zero have also been developed in literature when the arm distributions are restricted to a single parameter exponential family. In this paper, we first observe a negative result that some restrictions are essential as otherwise under a delta-correct algorithm, distributions with unbounded support would require an infinite number of samples in expectation. We then propose a delta-correct algorithm that matches the lower bound as delta reduces to zero under a mild restriction that a known bound on the expectation of a non-negative, increasing convex function (for example, the squared moment) of underlying random variables, exists. We also propose batch processing and identify optimal batch sizes to substantially speed up the proposed algorithm. This best arm selection problem is a well studied classic problem in the simulation community. It has many learning applications including in recommendation systems and in product selection.
Optimal Transport Relaxations with Application to Wasserstein GANs
Jun 07, 2019

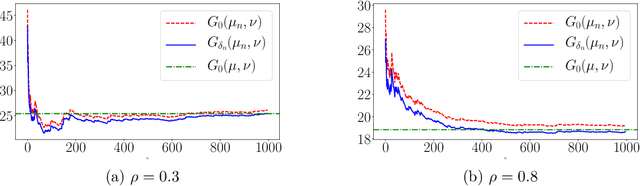

We propose a family of relaxations of the optimal transport problem which regularize the problem by introducing an additional minimization step over a small region around one of the underlying transporting measures. The type of regularization that we obtain is related to smoothing techniques studied in the optimization literature. When using our approach to estimate optimal transport costs based on empirical measures, we obtain statistical learning bounds which are useful to guide the amount of regularization, while maintaining good generalization properties. To illustrate the computational advantages of our regularization approach, we apply our method to training Wasserstein GANs. We obtain running time improvements, relative to current benchmarks, with no deterioration in testing performance (via FID). The running time improvement occurs because our new optimality-based threshold criterion reduces the number of expensive iterates of the generating networks, while increasing the number of actor-critic iterations.