 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Hierarchical Text-Conditional Image Generation with CLIP Latents
Apr 13, 2022


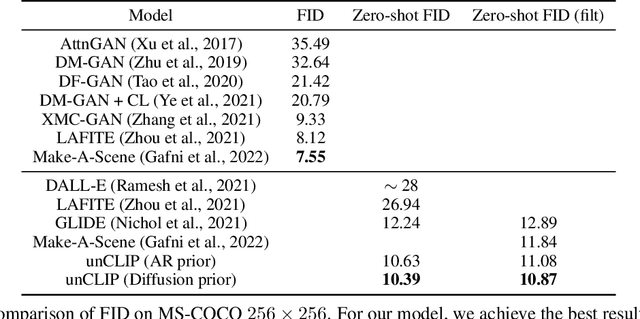
Contrastive models like CLIP have been shown to learn robust representations of images that capture both semantics and style. To leverage these representations for image generation, we propose a two-stage model: a prior that generates a CLIP image embedding given a text caption, and a decoder that generates an image conditioned on the image embedding. We show that explicitly generating image representations improves image diversity with minimal loss in photorealism and caption similarity. Our decoders conditioned on image representations can also produce variations of an image that preserve both its semantics and style, while varying the non-essential details absent from the image representation. Moreover, the joint embedding space of CLIP enables language-guided image manipulations in a zero-shot fashion. We use diffusion models for the decoder and experiment with both autoregressive and diffusion models for the prior, finding that the latter are computationally more efficient and produce higher-quality samples.
Asymmetric self-play for automatic goal discovery in robotic manipulation
Jan 13, 2021
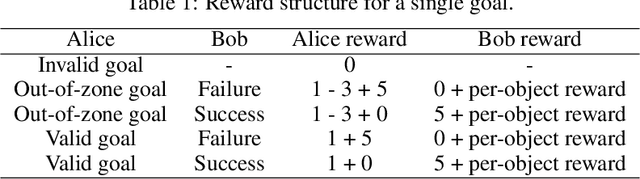
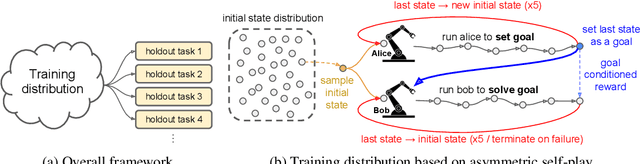
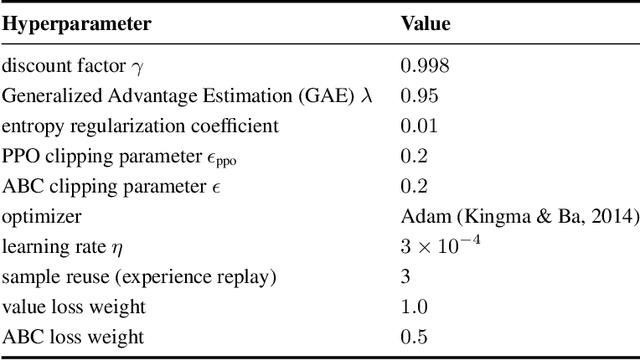
We train a single, goal-conditioned policy that can solve many robotic manipulation tasks, including tasks with previously unseen goals and objects. We rely on asymmetric self-play for goal discovery, where two agents, Alice and Bob, play a game. Alice is asked to propose challenging goals and Bob aims to solve them. We show that this method can discover highly diverse and complex goals without any human priors. Bob can be trained with only sparse rewards, because the interaction between Alice and Bob results in a natural curriculum and Bob can learn from Alice's trajectory when relabeled as a goal-conditioned demonstration. Finally, our method scales, resulting in a single policy that can generalize to many unseen tasks such as setting a table, stacking blocks, and solving simple puzzles. Videos of a learned policy is available at https://robotics-self-play.github.io.
The equivalence between Stein variational gradient descent and black-box variational inference
Apr 04, 2020
We formalize an equivalence between two popular methods for Bayesian inference: Stein variational gradient descent (SVGD) and black-box variational inference (BBVI). In particular, we show that BBVI corresponds precisely to SVGD when the kernel is the neural tangent kernel. Furthermore, we interpret SVGD and BBVI as kernel gradient flows; we do this by leveraging the recent perspective that views SVGD as a gradient flow in the space of probability distributions and showing that BBVI naturally motivates a Riemannian structure on that space. We observe that kernel gradient flow also describes dynamics found in the training of generative adversarial networks (GANs). This work thereby unifies several existing techniques in variational inference and generative modeling and identifies the kernel as a fundamental object governing the behavior of these algorithms, motivating deeper analysis of its properties.
Smoothness and Stability in GANs
Feb 11, 2020



Generative adversarial networks, or GANs, commonly display unstable behavior during training. In this work, we develop a principled theoretical framework for understanding the stability of various types of GANs. In particular, we derive conditions that guarantee eventual stationarity of the generator when it is trained with gradient descent, conditions that must be satisfied by the divergence that is minimized by the GAN and the generator's architecture. We find that existing GAN variants satisfy some, but not all, of these conditions. Using tools from convex analysis, optimal transport, and reproducing kernels, we construct a GAN that fulfills these conditions simultaneously. In the process, we explain and clarify the need for various existing GAN stabilization techniques, including Lipschitz constraints, gradient penalties, and smooth activation functions.
Probability Functional Descent: A Unifying Perspective on GANs, Variational Inference, and Reinforcement Learning
Jan 30, 2019

The goal of this paper is to provide a unifying view of a wide range of problems of interest in machine learning by framing them as the minimization of functionals defined on the space of probability measures. In particular, we show that generative adversarial networks, variational inference, and actor-critic methods in reinforcement learning can all be seen through the lens of our framework. We then discuss a generic optimization algorithm for our formulation, called probability functional descent (PFD), and show how this algorithm recovers existing methods developed independently in the settings mentioned earlier.
CycleGAN, a Master of Steganography
Dec 16, 2017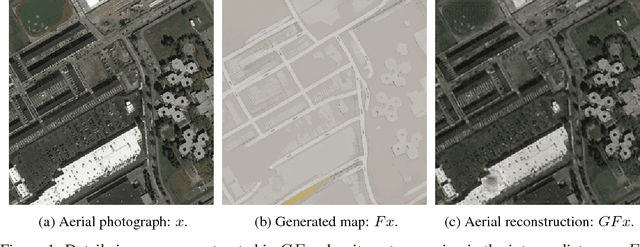

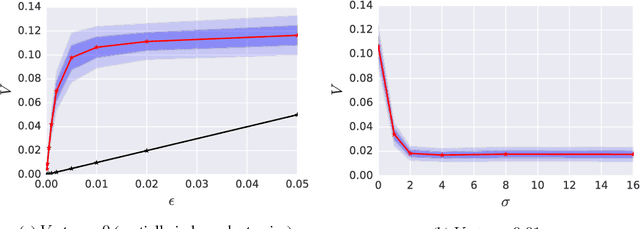

CycleGAN (Zhu et al. 2017) is one recent successful approach to learn a transformation between two image distributions. In a series of experiments, we demonstrate an intriguing property of the model: CycleGAN learns to "hide" information about a source image into the images it generates in a nearly imperceptible, high-frequency signal. This trick ensures that the generator can recover the original sample and thus satisfy the cyclic consistency requirement, while the generated image remains realistic. We connect this phenomenon with adversarial attacks by viewing CycleGAN's training procedure as training a generator of adversarial examples and demonstrate that the cyclic consistency loss causes CycleGAN to be especially vulnerable to adversarial attacks.