 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric self-play for automatic goal discovery in robotic manipulation
Jan 13, 2021
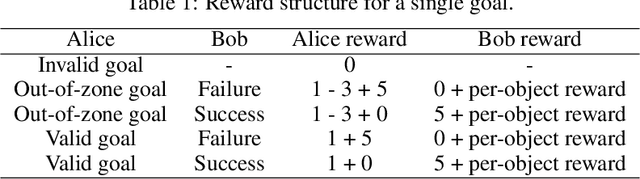
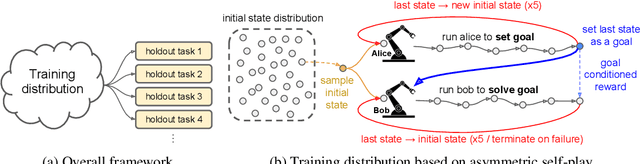
We train a single, goal-conditioned policy that can solve many robotic manipulation tasks, including tasks with previously unseen goals and objects. We rely on asymmetric self-play for goal discovery, where two agents, Alice and Bob, play a game. Alice is asked to propose challenging goals and Bob aims to solve them. We show that this method can discover highly diverse and complex goals without any human priors. Bob can be trained with only sparse rewards, because the interaction between Alice and Bob results in a natural curriculum and Bob can learn from Alice's trajectory when relabeled as a goal-conditioned demonstration. Finally, our method scales, resulting in a single policy that can generalize to many unseen tasks such as setting a table, stacking blocks, and solving simple puzzles. Videos of a learned policy is available at https://robotics-self-play.github.io.
Solving Rubik's Cube with a Robot Hand
Oct 16, 2019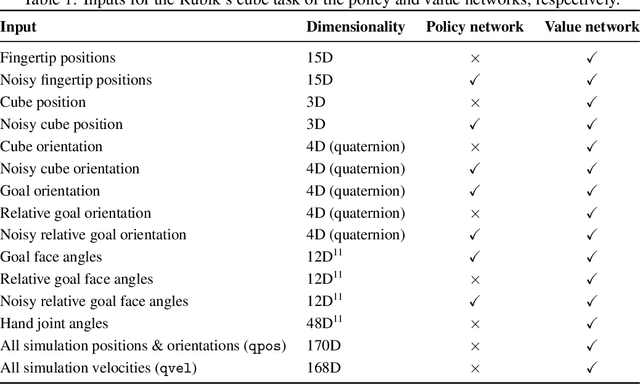
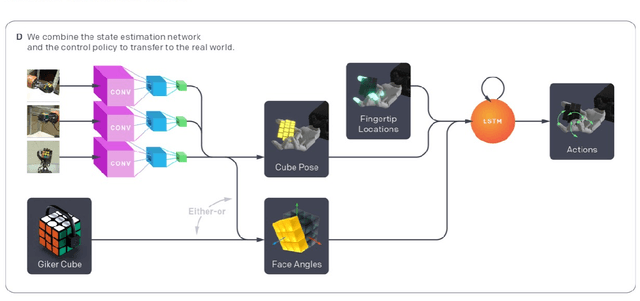
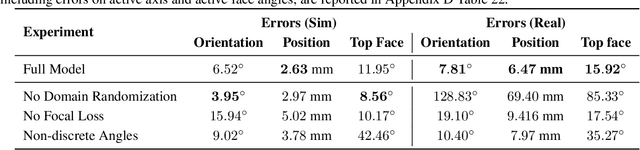

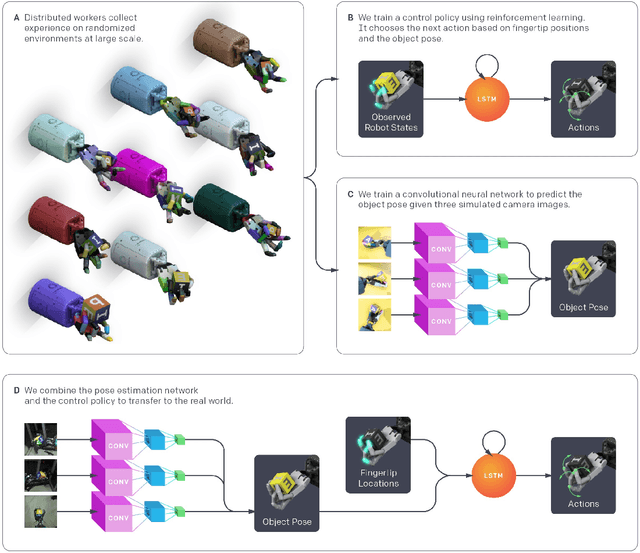
We demonstrate that models trained only in simulation can be used to solve a manipulation problem of unprecedented complexity on a real robot. This is made possible by two key components: a novel algorithm, which we call automatic domain randomization (ADR) and a robot platform built for machine learning. ADR automatically generates a distribution over randomized environments of ever-increasing difficulty. Control policies and vision state estimators trained with ADR exhibit vastly improved sim2real transfer. For control policies, memory-augmented models trained on an ADR-generated distribution of environments show clear signs of emergent meta-learning at test time. The combination of ADR with our custom robot platform allows us to solve a Rubik's cube with a humanoid robot hand, which involves both control and state estimation problems. Videos summarizing our results are available: https://openai.com/blog/solving-rubiks-cube/
Learning Dexterous In-Hand Manipulation
Jan 18, 2019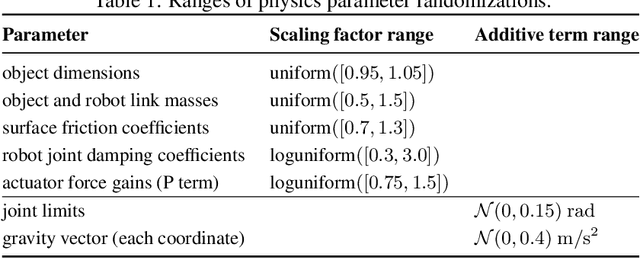
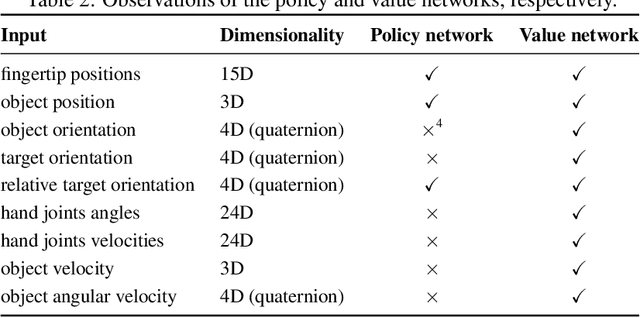

We use reinforcement learning (RL) to learn dexterous in-hand manipulation policies which can perform vision-based object reorientation on a physical Shadow Dexterous Hand. The training is performed in a simulated environment in which we randomize many of the physical properties of the system like friction coefficients and an object's appearance. Our policies transfer to the physical robot despite being trained entirely in simulation. Our method does not rely on any human demonstrations, but many behaviors found in human manipulation emerge naturally, including finger gaiting, multi-finger coordination, and the controlled use of gravity. Our results were obtained using the same distributed RL system that was used to train OpenAI Five. We also include a video of our results: https://youtu.be/jwSbzNHGflM