 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Verifiers to Solve Math Word Problems
Nov 18, 2021
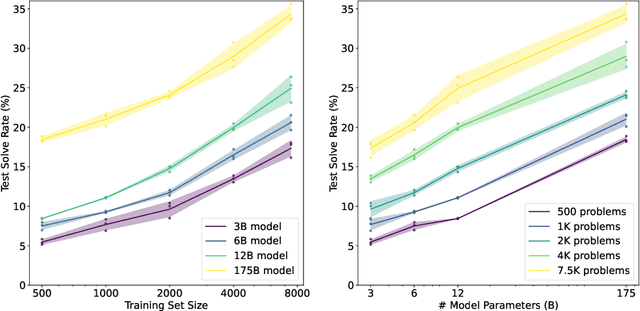
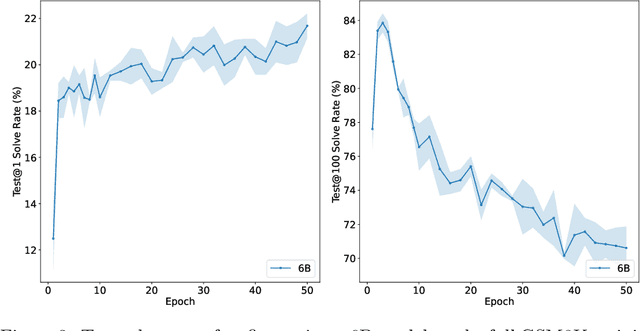
State-of-the-art language models can match human performance on many tasks, but they still struggle to robustly perform multi-step mathematical reasoning. To diagnose the failures of current models and support research, we introduce GSM8K, a dataset of 8.5K high quality linguistically diverse grade school math word problems. We find that even the largest transformer models fail to achieve high test performance, despite the conceptual simplicity of this problem distribution. To increase performance, we propose training verifiers to judge the correctness of model completions. At test time, we generate many candidate solutions and select the one ranked highest by the verifier. We demonstrate that verification significantly improves performance on GSM8K, and we provide strong empirical evidence that verification scales more effectively with increased data than a finetuning baseline.
Evaluating Large Language Models Trained on Code
Jul 14, 2021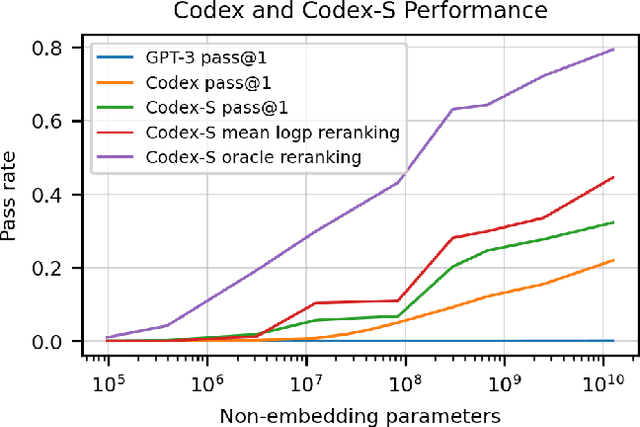
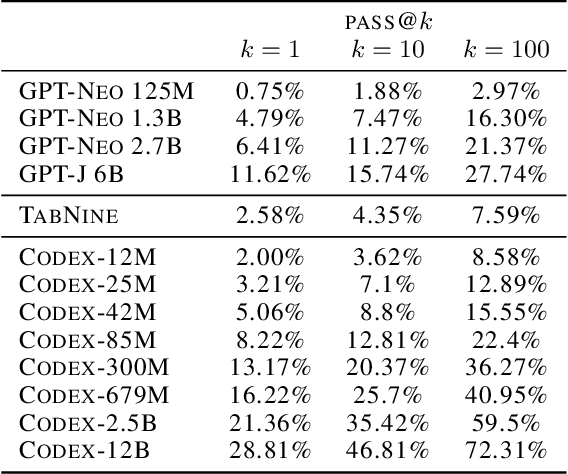
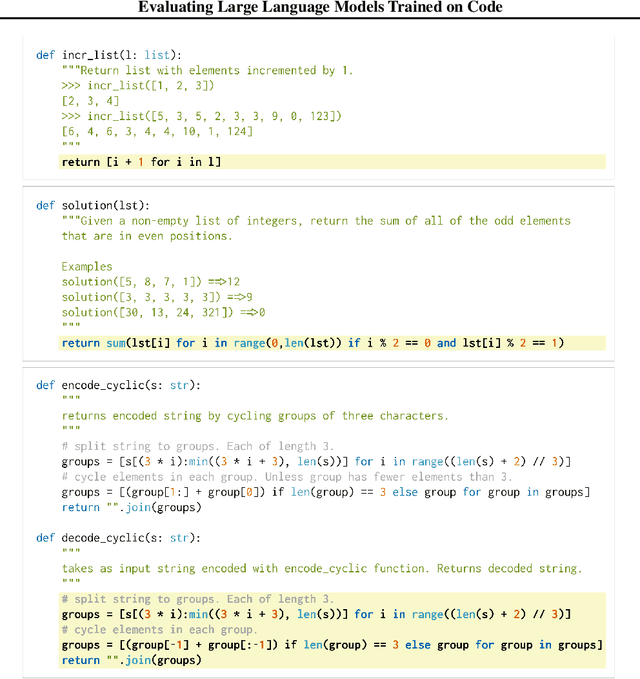
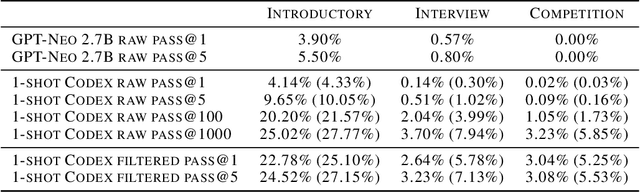
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
Asymmetric self-play for automatic goal discovery in robotic manipulation
Jan 13, 2021
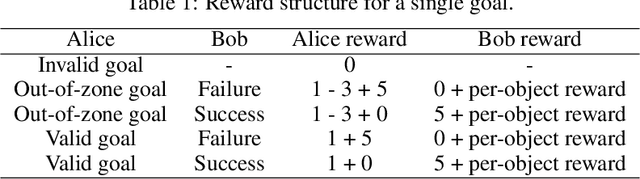
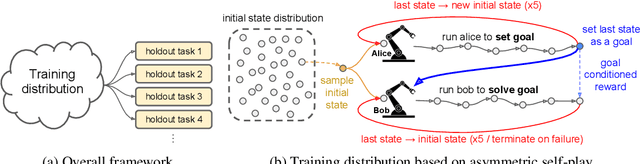
We train a single, goal-conditioned policy that can solve many robotic manipulation tasks, including tasks with previously unseen goals and objects. We rely on asymmetric self-play for goal discovery, where two agents, Alice and Bob, play a game. Alice is asked to propose challenging goals and Bob aims to solve them. We show that this method can discover highly diverse and complex goals without any human priors. Bob can be trained with only sparse rewards, because the interaction between Alice and Bob results in a natural curriculum and Bob can learn from Alice's trajectory when relabeled as a goal-conditioned demonstration. Finally, our method scales, resulting in a single policy that can generalize to many unseen tasks such as setting a table, stacking blocks, and solving simple puzzles. Videos of a learned policy is available at https://robotics-self-play.github.io.
Predicting Sim-to-Real Transfer with Probabilistic Dynamics Models
Sep 27, 2020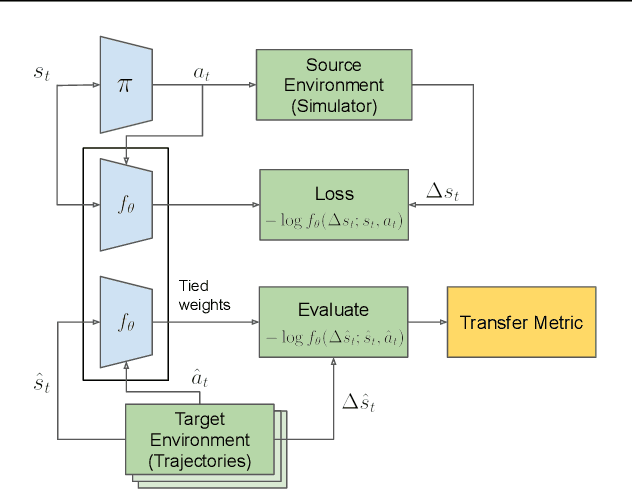
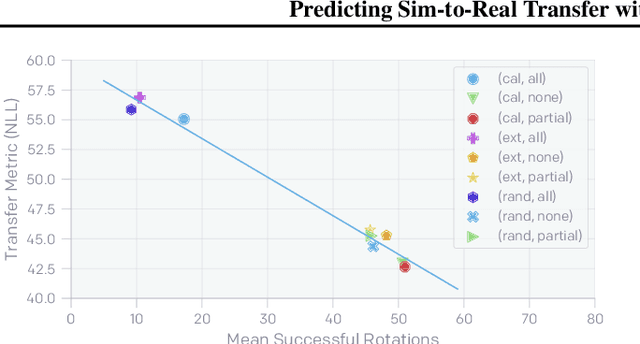
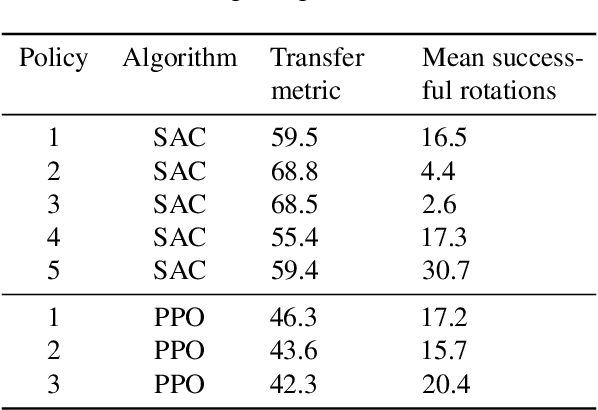
We propose a method to predict the sim-to-real transfer performance of RL policies. Our transfer metric simplifies the selection of training setups (such as algorithm, hyperparameters, randomizations) and policies in simulation, without the need for extensive and time-consuming real-world rollouts. A probabilistic dynamics model is trained alongside the policy and evaluated on a fixed set of real-world trajectories to obtain the transfer metric. Experiments show that the transfer metric is highly correlated with policy performance in both simulated and real-world robotic environments for complex manipulation tasks. We further show that the transfer metric can predict the effect of training setups on policy transfer performance.
Solving Rubik's Cube with a Robot Hand
Oct 16, 2019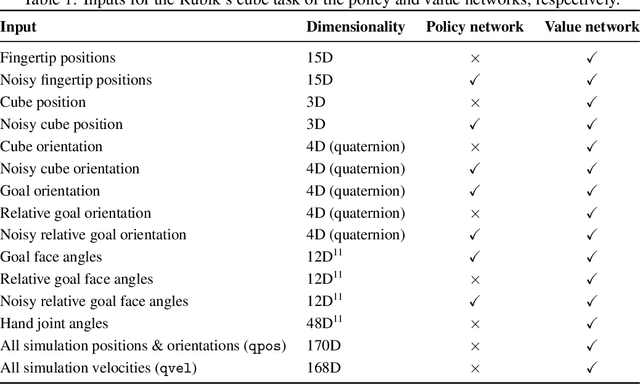
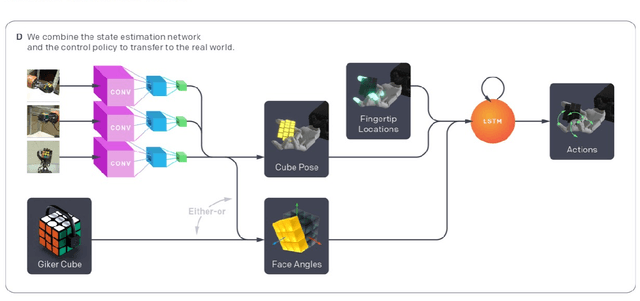
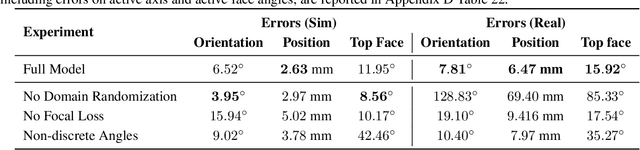

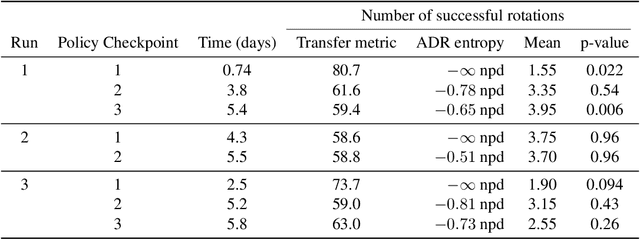
We demonstrate that models trained only in simulation can be used to solve a manipulation problem of unprecedented complexity on a real robot. This is made possible by two key components: a novel algorithm, which we call automatic domain randomization (ADR) and a robot platform built for machine learning. ADR automatically generates a distribution over randomized environments of ever-increasing difficulty. Control policies and vision state estimators trained with ADR exhibit vastly improved sim2real transfer. For control policies, memory-augmented models trained on an ADR-generated distribution of environments show clear signs of emergent meta-learning at test time. The combination of ADR with our custom robot platform allows us to solve a Rubik's cube with a humanoid robot hand, which involves both control and state estimation problems. Videos summarizing our results are available: https://openai.com/blog/solving-rubiks-cube/
Learning Dexterous In-Hand Manipulation
Jan 18, 2019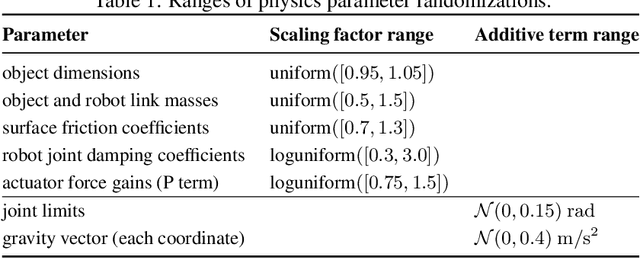
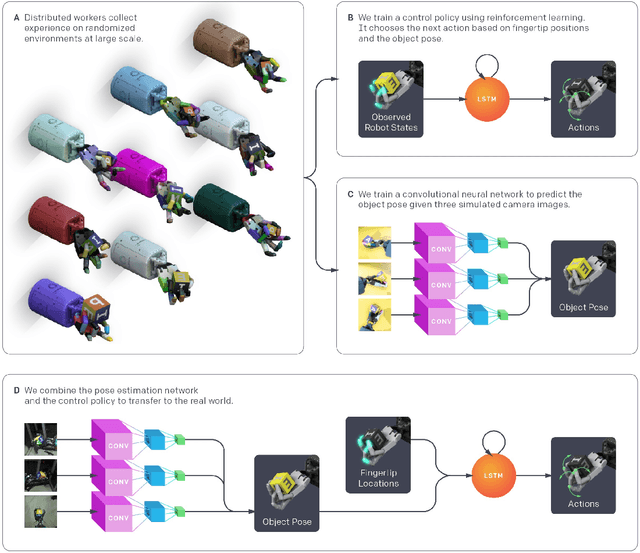
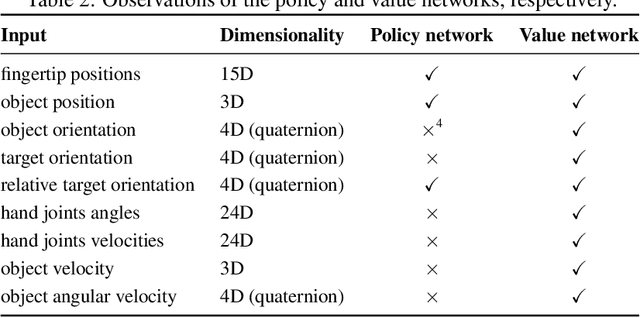

We use reinforcement learning (RL) to learn dexterous in-hand manipulation policies which can perform vision-based object reorientation on a physical Shadow Dexterous Hand. The training is performed in a simulated environment in which we randomize many of the physical properties of the system like friction coefficients and an object's appearance. Our policies transfer to the physical robot despite being trained entirely in simulation. Our method does not rely on any human demonstrations, but many behaviors found in human manipulation emerge naturally, including finger gaiting, multi-finger coordination, and the controlled use of gravity. Our results were obtained using the same distributed RL system that was used to train OpenAI Five. We also include a video of our results: https://youtu.be/jwSbzNHGflM
The KIT Motion-Language Dataset
Aug 09, 2018
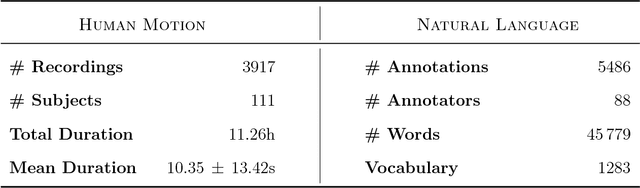
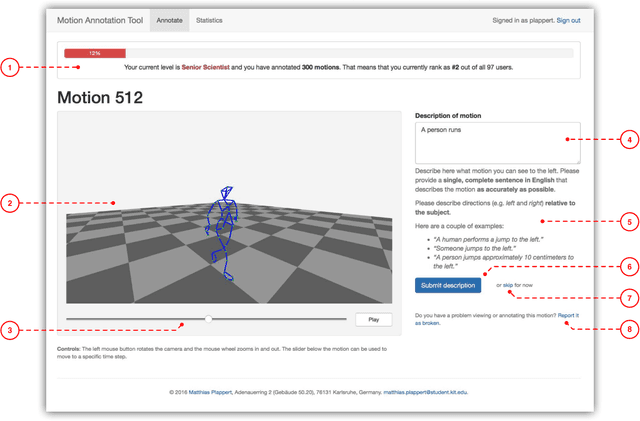
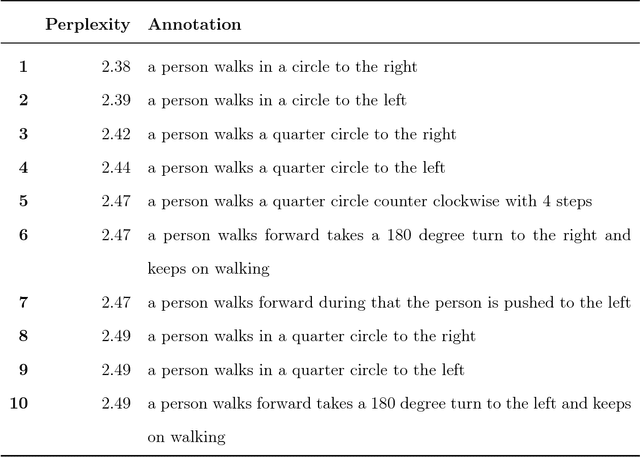
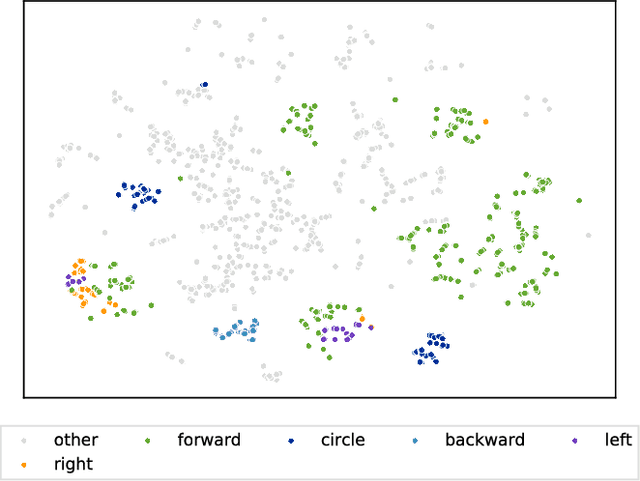
Linking human motion and natural language is of great interest for the generation of semantic representations of human activities as well as for the generation of robot activities based on natural language input. However, while there have been years of research in this area, no standardized and openly available dataset exists to support the development and evaluation of such systems. We therefore propose the KIT Motion-Language Dataset, which is large, open, and extensible. We aggregate data from multiple motion capture databases and include them in our dataset using a unified representation that is independent of the capture system or marker set, making it easy to work with the data regardless of its origin. To obtain motion annotations in natural language, we apply a crowd-sourcing approach and a web-based tool that was specifically build for this purpose, the Motion Annotation Tool. We thoroughly document the annotation process itself and discuss gamification methods that we used to keep annotators motivated. We further propose a novel method, perplexity-based selection, which systematically selects motions for further annotation that are either under-represented in our dataset or that have erroneous annotations. We show that our method mitigates the two aforementioned problems and ensures a systematic annotation process. We provide an in-depth analysis of the structure and contents of our resulting dataset, which, as of October 10, 2016, contains 3911 motions with a total duration of 11.23 hours and 6278 annotations in natural language that contain 52,903 words. We believe this makes our dataset an excellent choice that enables more transparent and comparable research in this important area.
Learning a bidirectional mapping between human whole-body motion and natural language using deep recurrent neural networks
Aug 02, 2018

Linking human whole-body motion and natural language is of great interest for the generation of semantic representations of observed human behaviors as well as for the generation of robot behaviors based on natural language input. While there has been a large body of research in this area, most approaches that exist today require a symbolic representation of motions (e.g. in the form of motion primitives), which have to be defined a-priori or require complex segmentation algorithms. In contrast, recent advances in the field of neural networks and especially deep learning have demonstrated that sub-symbolic representations that can be learned end-to-end usually outperform more traditional approaches, for applications such as machine translation. In this paper we propose a generative model that learns a bidirectional mapping between human whole-body motion and natural language using deep recurrent neural networks (RNNs) and sequence-to-sequence learning. Our approach does not require any segmentation or manual feature engineering and learns a distributed representation, which is shared for all motions and descriptions. We evaluate our approach on 2,846 human whole-body motions and 6,187 natural language descriptions thereof from the KIT Motion-Language Dataset. Our results clearly demonstrate the effectiveness of the proposed model: We show that our model generates a wide variety of realistic motions only from descriptions thereof in form of a single sentence. Conversely, our model is also capable of generating correct and detailed natural language descriptions from human motions.
Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research
Mar 10, 2018

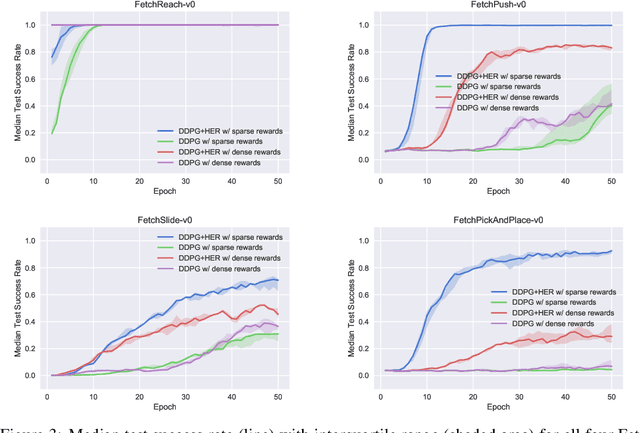
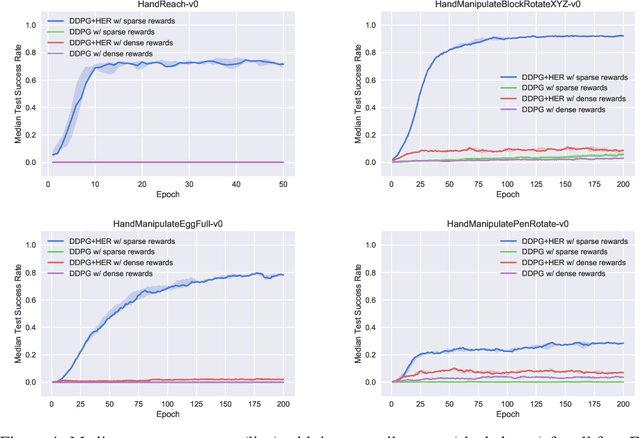
The purpose of this technical report is two-fold. First of all, it introduces a suite of challenging continuous control tasks (integrated with OpenAI Gym) based on currently existing robotics hardware. The tasks include pushing, sliding and pick & place with a Fetch robotic arm as well as in-hand object manipulation with a Shadow Dexterous Hand. All tasks have sparse binary rewards and follow a Multi-Goal Reinforcement Learning (RL) framework in which an agent is told what to do using an additional input. The second part of the paper presents a set of concrete research ideas for improving RL algorithms, most of which are related to Multi-Goal RL and Hindsight Experience Replay.
Parameter Space Noise for Exploration
Jan 31, 2018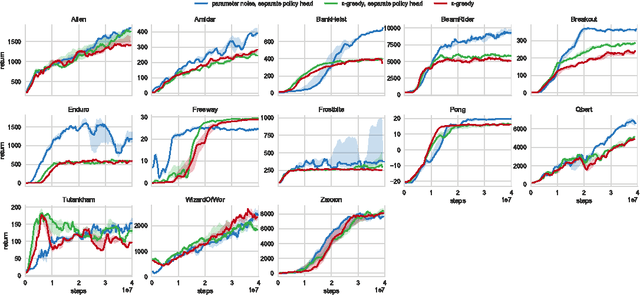
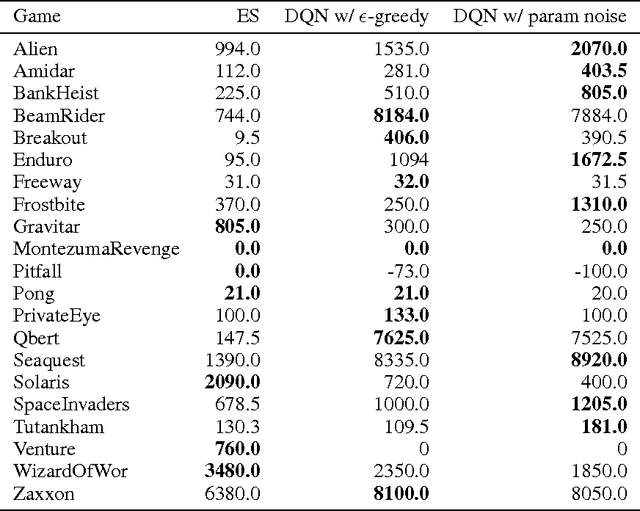
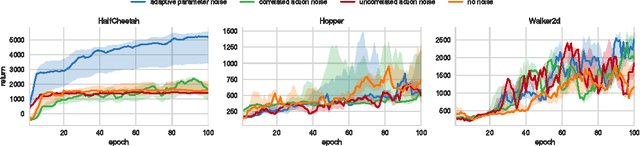
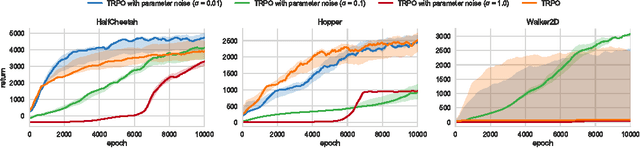
Deep reinforcement learning (RL) methods generally engage in exploratory behavior through noise injection in the action space. An alternative is to add noise directly to the agent's parameters, which can lead to more consistent exploration and a richer set of behaviors. Methods such as evolutionary strategies use parameter perturbations, but discard all temporal structure in the process and require significantly more samples. Combining parameter noise with traditional RL methods allows to combine the best of both worlds. We demonstrate that both off- and on-policy methods benefit from this approach through experimental comparison of DQN, DDPG, and TRPO on high-dimensional discrete action environments as well as continuous control tasks. Our results show that RL with parameter noise learns more efficiently than traditional RL with action space noise and evolutionary strategies individually.