 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Opponent-Learning Awareness
Sep 19, 2018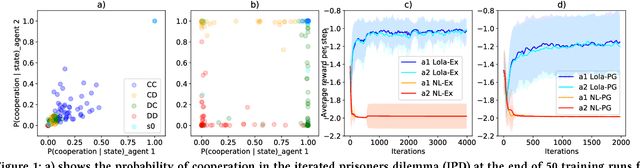
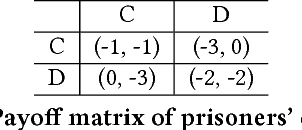
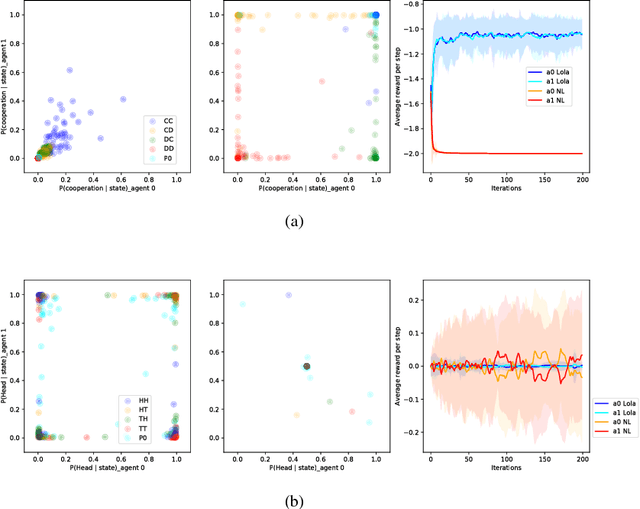
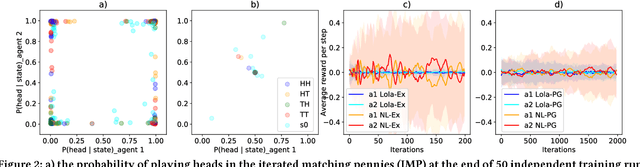
Multi-agent settings are quickly gathering importance in machine learning. This includes a plethora of recent work on deep multi-agent reinforcement learning, but also can be extended to hierarchical RL, generative adversarial networks and decentralised optimisation. In all these settings the presence of multiple learning agents renders the training problem non-stationary and often leads to unstable training or undesired final results. We present Learning with Opponent-Learning Awareness (LOLA), a method in which each agent shapes the anticipated learning of the other agents in the environment. The LOLA learning rule includes a term that accounts for the impact of one agent's policy on the anticipated parameter update of the other agents. Results show that the encounter of two LOLA agents leads to the emergence of tit-for-tat and therefore cooperation in the iterated prisoners' dilemma, while independent learning does not. In this domain, LOLA also receives higher payouts compared to a naive learner, and is robust against exploitation by higher order gradient-based methods. Applied to repeated matching pennies, LOLA agents converge to the Nash equilibrium. In a round robin tournament we show that LOLA agents successfully shape the learning of a range of multi-agent learning algorithms from literature, resulting in the highest average returns on the IPD. We also show that the LOLA update rule can be efficiently calculated using an extension of the policy gradient estimator, making the method suitable for model-free RL. The method thus scales to large parameter and input spaces and nonlinear function approximators. We apply LOLA to a grid world task with an embedded social dilemma using recurrent policies and opponent modelling. By explicitly considering the learning of the other agent, LOLA agents learn to cooperate out of self-interest. The code is at github.com/alshedivat/lola.
Evolved Policy Gradients
Apr 29, 2018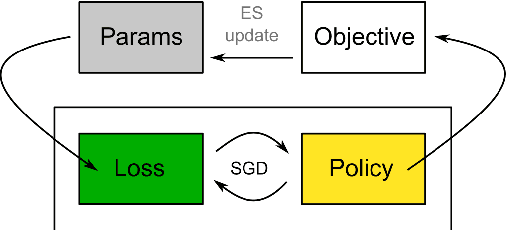

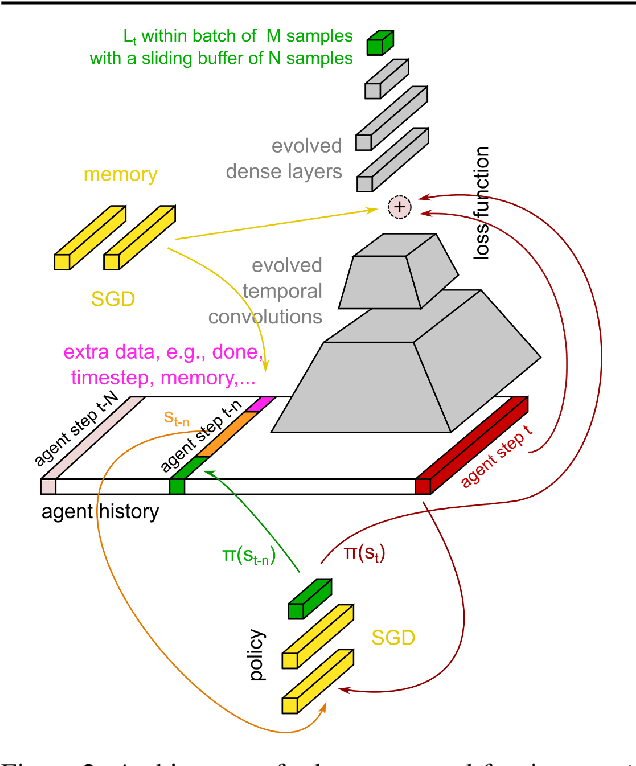

We propose a metalearning approach for learning gradient-based reinforcement learning (RL) algorithms. The idea is to evolve a differentiable loss function, such that an agent, which optimizes its policy to minimize this loss, will achieve high rewards. The loss is parametrized via temporal convolutions over the agent's experience. Because this loss is highly flexible in its ability to take into account the agent's history, it enables fast task learning. Empirical results show that our evolved policy gradient algorithm (EPG) achieves faster learning on several randomized environments compared to an off-the-shelf policy gradient method. We also demonstrate that EPG's learned loss can generalize to out-of-distribution test time tasks, and exhibits qualitatively different behavior from other popular metalearning algorithms.
Parameter Space Noise for Exploration
Jan 31, 2018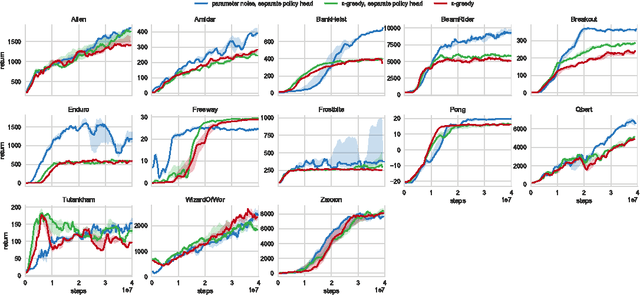
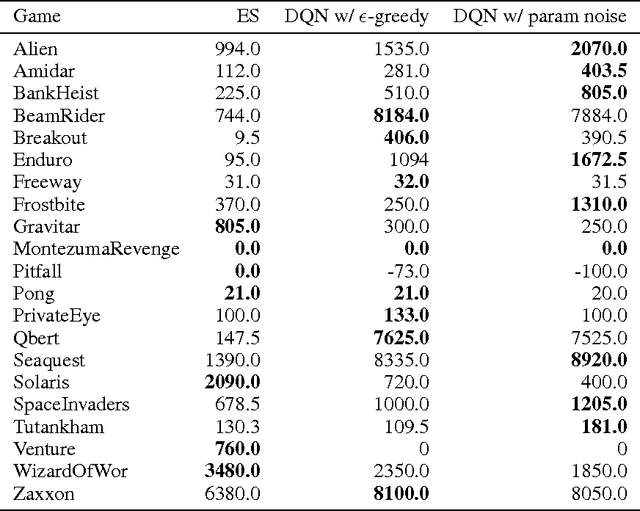
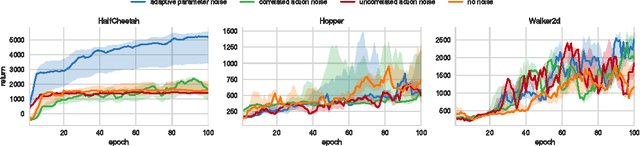
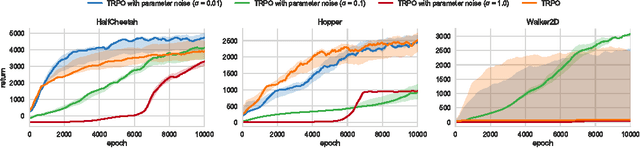
Deep reinforcement learning (RL) methods generally engage in exploratory behavior through noise injection in the action space. An alternative is to add noise directly to the agent's parameters, which can lead to more consistent exploration and a richer set of behaviors. Methods such as evolutionary strategies use parameter perturbations, but discard all temporal structure in the process and require significantly more samples. Combining parameter noise with traditional RL methods allows to combine the best of both worlds. We demonstrate that both off- and on-policy methods benefit from this approach through experimental comparison of DQN, DDPG, and TRPO on high-dimensional discrete action environments as well as continuous control tasks. Our results show that RL with parameter noise learns more efficiently than traditional RL with action space noise and evolutionary strategies individually.
UCB Exploration via Q-Ensembles
Nov 07, 2017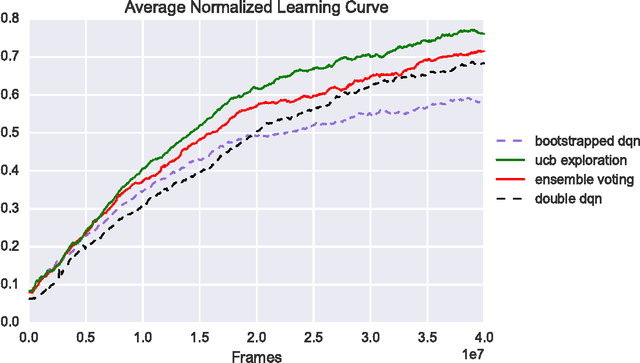

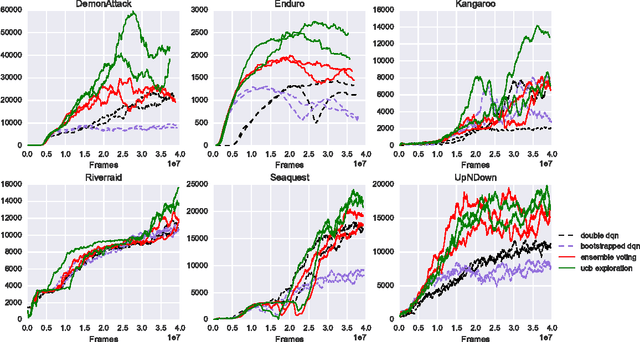
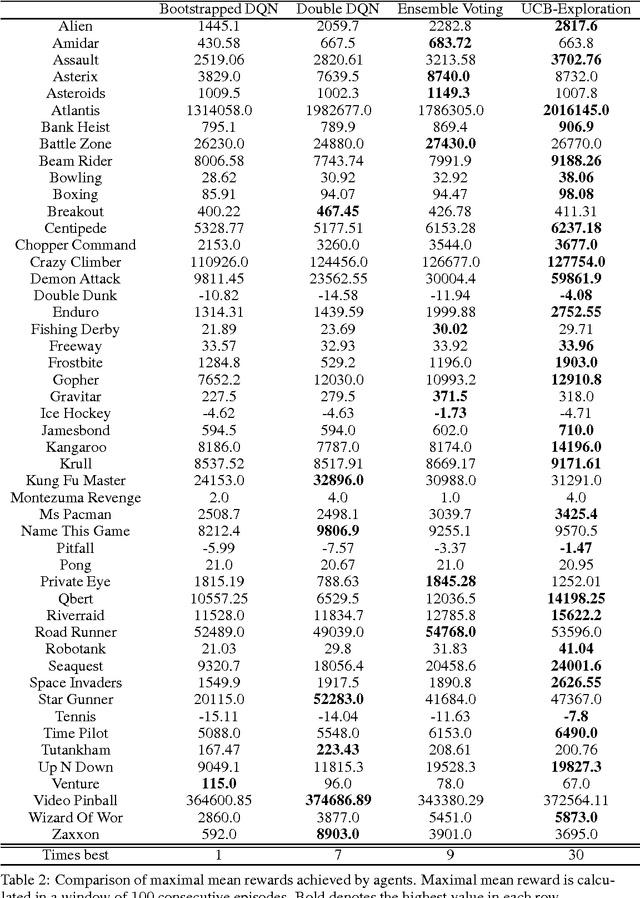
We show how an ensemble of $Q^*$-functions can be leveraged for more effective exploration in deep reinforcement learning. We build on well established algorithms from the bandit setting, and adapt them to the $Q$-learning setting. We propose an exploration strategy based on upper-confidence bounds (UCB). Our experiments show significant gains on the Atari benchmark.
Convolutional neural networks that teach microscopes how to image
Sep 21, 2017


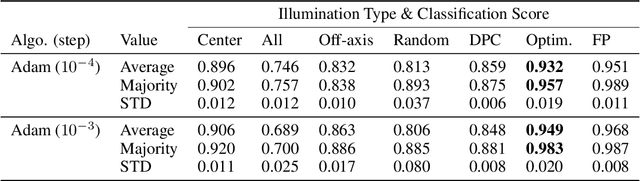
Deep learning algorithms offer a powerful means to automatically analyze the content of medical images. However, many biological samples of interest are primarily transparent to visible light and contain features that are difficult to resolve with a standard optical microscope. Here, we use a convolutional neural network (CNN) not only to classify images, but also to optimize the physical layout of the imaging device itself. We increase the classification accuracy of a microscope's recorded images by merging an optical model of image formation into the pipeline of a CNN. The resulting network simultaneously determines an ideal illumination arrangement to highlight important sample features during image acquisition, along with a set of convolutional weights to classify the detected images post-capture. We demonstrate our joint optimization technique with an experimental microscope configuration that automatically identifies malaria-infected cells with 5-10% higher accuracy than standard and alternative microscope lighting designs.