 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Leaks Count, Some Count More: Interpretable Temporal Contamination Detection in LLM Backtesting
Feb 19, 2026To evaluate whether LLMs can accurately predict future events, we need the ability to \textit{backtest} them on events that have already resolved. This requires models to reason only with information available at a specified past date. Yet LLMs may inadvertently leak post-cutoff knowledge encoded during training, undermining the validity of retrospective evaluation. We introduce a claim-level framework for detecting and quantifying this \emph{temporal knowledge leakage}. Our approach decomposes model rationales into atomic claims and categorizes them by temporal verifiability, then applies \textit{Shapley values} to measure each claim's contribution to the prediction. This yields the \textbf{Shapley}-weighted \textbf{D}ecision-\textbf{C}ritical \textbf{L}eakage \textbf{R}ate (\textbf{Shapley-DCLR}), an interpretable metric that captures what fraction of decision-driving reasoning derives from leaked information. Building on this framework, we propose \textbf{Time}-\textbf{S}upervised \textbf{P}rediction with \textbf{E}xtracted \textbf{C}laims (\textbf{TimeSPEC}), which interleaves generation with claim verification and regeneration to proactively filter temporal contamination -- producing predictions where every supporting claim can be traced to sources available before the cutoff date. Experiments on 350 instances spanning U.S. Supreme Court case prediction, NBA salary estimation, and stock return ranking reveal substantial leakage in standard prompting baselines. TimeSPEC reduces Shapley-DCLR while preserving task performance, demonstrating that explicit, interpretable claim-level verification outperforms prompt-based temporal constraints for reliable backtesting.
Evolutionary System Prompt Learning can Facilitate Reinforcement Learning for LLMs
Feb 16, 2026Building agentic systems that can autonomously self-improve from experience is a longstanding goal of AI. Large language models (LLMs) today primarily self-improve via two mechanisms: self-reflection for context updates, and reinforcement learning (RL) for weight updates. In this work, we propose Evolutionary System Prompt Learning (E-SPL), a method for jointly improving model contexts and model weights. In each RL iteration, E-SPL selects multiple system prompts and runs rollouts with each in parallel. It applies RL updates to model weights conditioned on each system prompt, and evolutionary updates to the system prompt population via LLM-driven mutation and crossover. Each system prompt has a TrueSkill rating for evolutionary selection, updated from relative performance within each RL iteration batch. E-SPL encourages a natural division between declarative knowledge encoded in prompts and procedural knowledge encoded in weights, resulting in improved performance across reasoning and agentic tasks. For instance, in an easy-to-hard (AIME $\rightarrow$ BeyondAIME) generalization setting, E-SPL improves RL success rate from 38.8% $\rightarrow$ 45.1% while also outperforming reflective prompt evolution (40.0%). Overall, our results show that coupling reinforcement learning with system prompt evolution yields consistent gains in sample efficiency and generalization. Code: https://github.com/LunjunZhang/E-SPL
AIA Forecaster: Technical Report
Nov 10, 2025This technical report describes the AIA Forecaster, a Large Language Model (LLM)-based system for judgmental forecasting using unstructured data. The AIA Forecaster approach combines three core elements: agentic search over high-quality news sources, a supervisor agent that reconciles disparate forecasts for the same event, and a set of statistical calibration techniques to counter behavioral biases in large language models. On the ForecastBench benchmark (Karger et al., 2024), the AIA Forecaster achieves performance equal to human superforecasters, surpassing prior LLM baselines. In addition to reporting on ForecastBench, we also introduce a more challenging forecasting benchmark sourced from liquid prediction markets. While the AIA Forecaster underperforms market consensus on this benchmark, an ensemble combining AIA Forecaster with market consensus outperforms consensus alone, demonstrating that our forecaster provides additive information. Our work establishes a new state of the art in AI forecasting and provides practical, transferable recommendations for future research. To the best of our knowledge, this is the first work that verifiably achieves expert-level forecasting at scale.
Of Mice and Machines: A Comparison of Learning Between Real World Mice and RL Agents
May 18, 2025Recent advances in reinforcement learning (RL) have demonstrated impressive capabilities in complex decision-making tasks. This progress raises a natural question: how do these artificial systems compare to biological agents, which have been shaped by millions of years of evolution? To help answer this question, we undertake a comparative study of biological mice and RL agents in a predator-avoidance maze environment. Through this analysis, we identify a striking disparity: RL agents consistently demonstrate a lack of self-preservation instinct, readily risking ``death'' for marginal efficiency gains. These risk-taking strategies are in contrast to biological agents, which exhibit sophisticated risk-assessment and avoidance behaviors. Towards bridging this gap between the biological and artificial, we propose two novel mechanisms that encourage more naturalistic risk-avoidance behaviors in RL agents. Our approach leads to the emergence of naturalistic behaviors, including strategic environment assessment, cautious path planning, and predator avoidance patterns that closely mirror those observed in biological systems.
LAMP: Extracting Locally Linear Decision Surfaces from LLM World Models
May 17, 2025We introduce \textbf{LAMP} (\textbf{L}inear \textbf{A}ttribution \textbf{M}apping \textbf{P}robe), a method that shines light onto a black-box language model's decision surface and studies how reliably a model maps its stated reasons to its predictions through a locally linear model approximating the decision surface. LAMP treats the model's own self-reported explanations as a coordinate system and fits a locally linear surrogate that links those weights to the model's output. By doing so, it reveals which stated factors steer the model's decisions, and by how much. We apply LAMP to three tasks: \textit{sentiment analysis}, \textit{controversial-topic detection}, and \textit{safety-prompt auditing}. Across these tasks, LAMP reveals that many LLMs exhibit locally linear decision landscapes. In addition, these surfaces correlate with human judgments on explanation quality and, on a clinical case-file data set, aligns with expert assessments. Since LAMP operates without requiring access to model gradients, logits, or internal activations, it serves as a practical and lightweight framework for auditing proprietary language models, and enabling assessment of whether a model behaves consistently with the explanations it provides.
Cold Diffusion on the Replay Buffer: Learning to Plan from Known Good States
Oct 21, 2023



Learning from demonstrations (LfD) has successfully trained robots to exhibit remarkable generalization capabilities. However, many powerful imitation techniques do not prioritize the feasibility of the robot behaviors they generate. In this work, we explore the feasibility of plans produced by LfD. As in prior work, we employ a temporal diffusion model with fixed start and goal states to facilitate imitation through in-painting. Unlike previous studies, we apply cold diffusion to ensure the optimization process is directed through the agent's replay buffer of previously visited states. This routing approach increases the likelihood that the final trajectories will predominantly occupy the feasible region of the robot's state space. We test this method in simulated robotic environments with obstacles and observe a significant improvement in the agent's ability to avoid these obstacles during planning.
Understanding Hindsight Goal Relabeling Requires Rethinking Divergence Minimization
Sep 26, 2022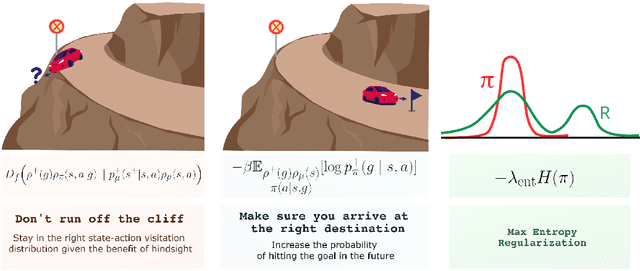
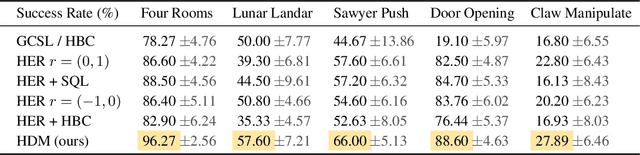
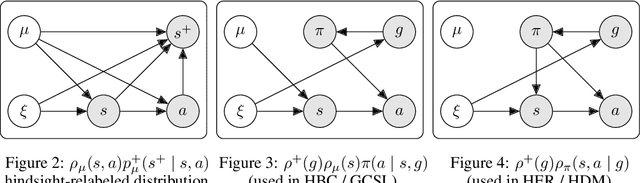
Hindsight goal relabeling has become a foundational technique for multi-goal reinforcement learning (RL). The idea is quite simple: any arbitrary trajectory can be seen as an expert demonstration for reaching the trajectory's end state. Intuitively, this procedure trains a goal-conditioned policy to imitate a sub-optimal expert. However, this connection between imitation and hindsight relabeling is not well understood. Modern imitation learning algorithms are described in the language of divergence minimization, and yet it remains an open problem how to recast hindsight goal relabeling into that framework. In this work, we develop a unified objective for goal-reaching that explains such a connection, from which we can derive goal-conditioned supervised learning (GCSL) and the reward function in hindsight experience replay (HER) from first principles. Experimentally, we find that despite recent advances in goal-conditioned behaviour cloning (BC), multi-goal Q-learning can still outperform BC-like methods; moreover, a vanilla combination of both actually hurts model performance. Under our framework, we study when BC is expected to help, and empirically validate our findings. Our work further bridges goal-reaching and generative modeling, illustrating the nuances and new pathways of extending the success of generative models to RL.
World Model as a Graph: Learning Latent Landmarks for Planning
Nov 25, 2020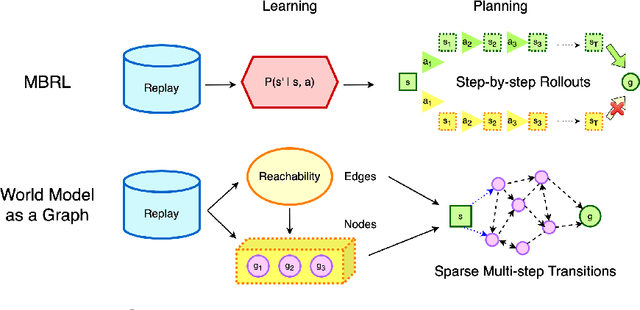
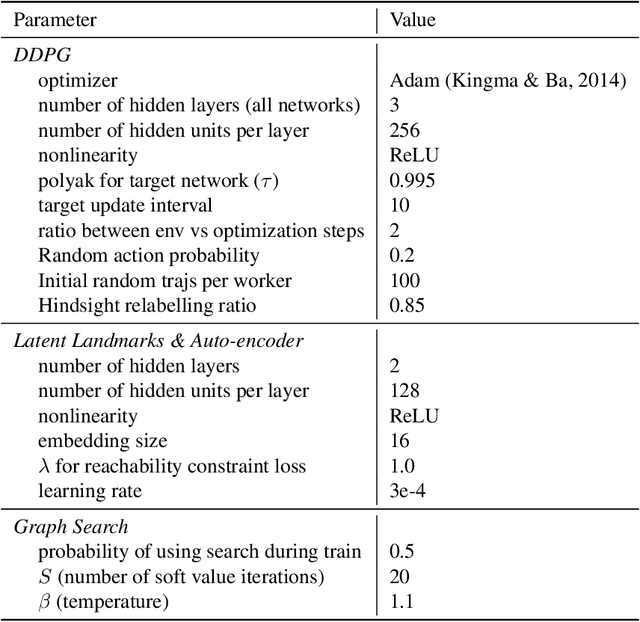
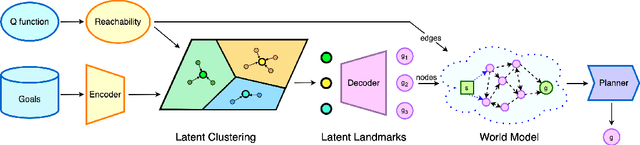

Planning - the ability to analyze the structure of a problem in the large and decompose it into interrelated subproblems - is a hallmark of human intelligence. While deep reinforcement learning (RL) has shown great promise for solving relatively straightforward control tasks, it remains an open problem how to best incorporate planning into existing deep RL paradigms to handle increasingly complex environments. One prominent framework, Model-Based RL, learns a world model and plans using step-by-step virtual rollouts. This type of world model quickly diverges from reality when the planning horizon increases, thus struggling at long-horizon planning. How can we learn world models that endow agents with the ability to do temporally extended reasoning? In this work, we propose to learn graph-structured world models composed of sparse, multi-step transitions. We devise a novel algorithm to learn latent landmarks that are scattered (in terms of reachability) across the goal space as the nodes on the graph. In this same graph, the edges are the reachability estimates distilled from Q-functions. On a variety of high-dimensional continuous control tasks ranging from robotic manipulation to navigation, we demonstrate that our method, named L3P, significantly outperforms prior work, and is oftentimes the only method capable of leveraging both the robustness of model-free RL and generalization of graph-search algorithms. We believe our work is an important step towards scalable planning in reinforcement learning.
Transfer Learning for Estimating Causal Effects using Neural Networks
Aug 23, 2018
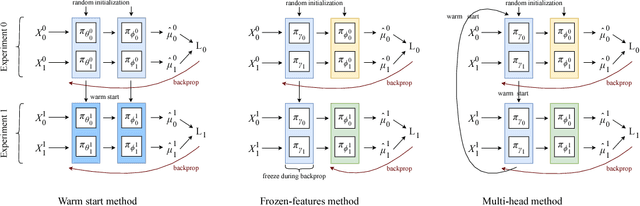
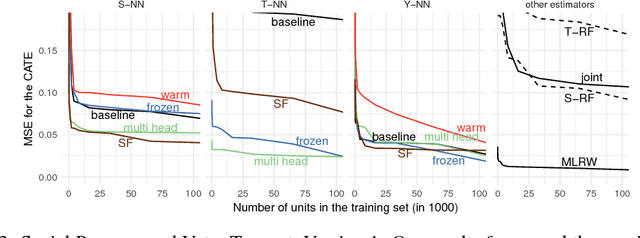
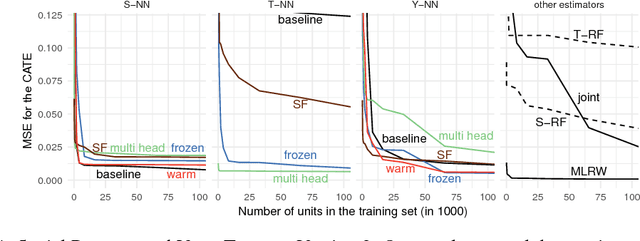
We develop new algorithms for estimating heterogeneous treatment effects, combining recent developments in transfer learning for neural networks with insights from the causal inference literature. By taking advantage of transfer learning, we are able to efficiently use different data sources that are related to the same underlying causal mechanisms. We compare our algorithms with those in the extant literature using extensive simulation studies based on large-scale voter persuasion experiments and the MNIST database. Our methods can perform an order of magnitude better than existing benchmarks while using a fraction of the data.
Evolved Policy Gradients
Apr 29, 2018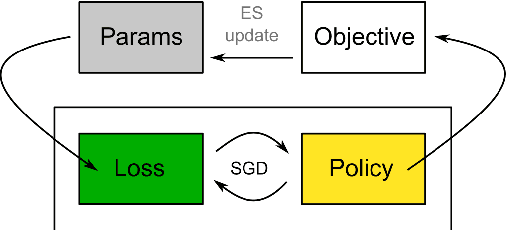

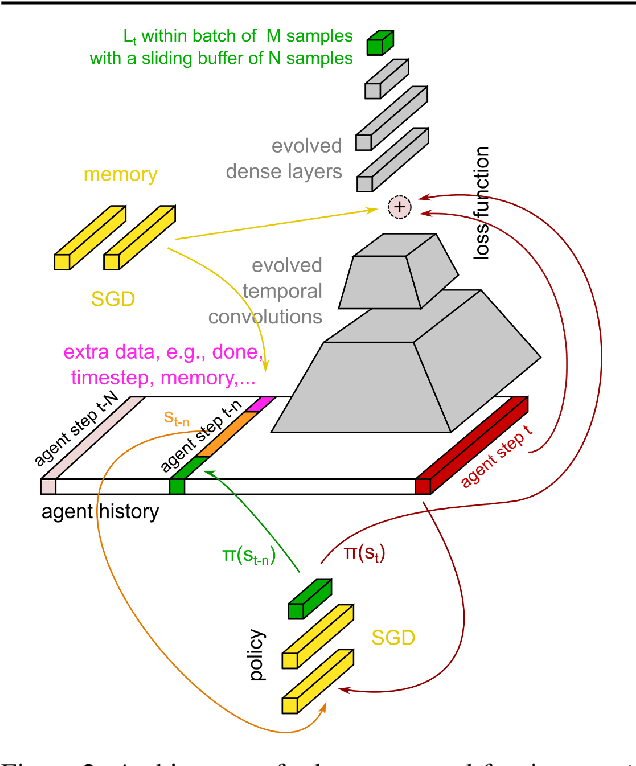

We propose a metalearning approach for learning gradient-based reinforcement learning (RL) algorithms. The idea is to evolve a differentiable loss function, such that an agent, which optimizes its policy to minimize this loss, will achieve high rewards. The loss is parametrized via temporal convolutions over the agent's experience. Because this loss is highly flexible in its ability to take into account the agent's history, it enables fast task learning. Empirical results show that our evolved policy gradient algorithm (EPG) achieves faster learning on several randomized environments compared to an off-the-shelf policy gradient method. We also demonstrate that EPG's learned loss can generalize to out-of-distribution test time tasks, and exhibits qualitatively different behavior from other popular metalearning algorithms.