 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIA Forecaster: Technical Report
Nov 10, 2025This technical report describes the AIA Forecaster, a Large Language Model (LLM)-based system for judgmental forecasting using unstructured data. The AIA Forecaster approach combines three core elements: agentic search over high-quality news sources, a supervisor agent that reconciles disparate forecasts for the same event, and a set of statistical calibration techniques to counter behavioral biases in large language models. On the ForecastBench benchmark (Karger et al., 2024), the AIA Forecaster achieves performance equal to human superforecasters, surpassing prior LLM baselines. In addition to reporting on ForecastBench, we also introduce a more challenging forecasting benchmark sourced from liquid prediction markets. While the AIA Forecaster underperforms market consensus on this benchmark, an ensemble combining AIA Forecaster with market consensus outperforms consensus alone, demonstrating that our forecaster provides additive information. Our work establishes a new state of the art in AI forecasting and provides practical, transferable recommendations for future research. To the best of our knowledge, this is the first work that verifiably achieves expert-level forecasting at scale.
The Silent Majority: Demystifying Memorization Effect in the Presence of Spurious Correlations
Jan 01, 2025Machine learning models often rely on simple spurious features -- patterns in training data that correlate with targets but are not causally related to them, like image backgrounds in foreground classification. This reliance typically leads to imbalanced test performance across minority and majority groups. In this work, we take a closer look at the fundamental cause of such imbalanced performance through the lens of memorization, which refers to the ability to predict accurately on \textit{atypical} examples (minority groups) in the training set but failing in achieving the same accuracy in the testing set. This paper systematically shows the ubiquitous existence of spurious features in a small set of neurons within the network, providing the first-ever evidence that memorization may contribute to imbalanced group performance. Through three experimental sources of converging empirical evidence, we find the property of a small subset of neurons or channels in memorizing minority group information. Inspired by these findings, we articulate the hypothesis: the imbalanced group performance is a byproduct of ``noisy'' spurious memorization confined to a small set of neurons. To further substantiate this hypothesis, we show that eliminating these unnecessary spurious memorization patterns via a novel framework during training can significantly affect the model performance on minority groups. Our experimental results across various architectures and benchmarks offer new insights on how neural networks encode core and spurious knowledge, laying the groundwork for future research in demystifying robustness to spurious correlation.
Calibrating Multi-modal Representations: A Pursuit of Group Robustness without Annotations
Mar 12, 2024
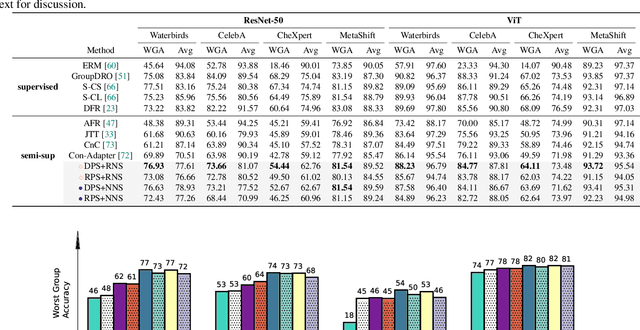

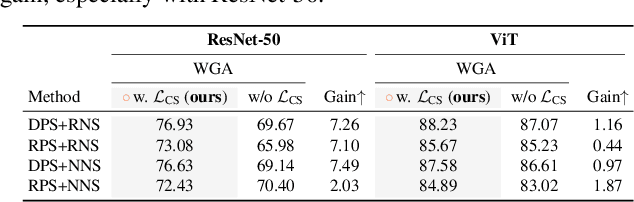
Fine-tuning pre-trained vision-language models, like CLIP, has yielded success on diverse downstream tasks. However, several pain points persist for this paradigm: (i) directly tuning entire pre-trained models becomes both time-intensive and computationally costly. Additionally, these tuned models tend to become highly specialized, limiting their practicality for real-world deployment; (ii) recent studies indicate that pre-trained vision-language classifiers may overly depend on spurious features -- patterns that correlate with the target in training data, but are not related to the true labeling function; and (iii) existing studies on mitigating the reliance on spurious features, largely based on the assumption that we can identify such features, does not provide definitive assurance for real-world applications. As a piloting study, this work focuses on exploring mitigating the reliance on spurious features for CLIP without using any group annotation. To this end, we systematically study the existence of spurious correlation on CLIP and CILP+ERM. We first, following recent work on Deep Feature Reweighting (DFR), verify that last-layer retraining can greatly improve group robustness on pretrained CLIP. In view of them, we advocate a lightweight representation calibration method for fine-tuning CLIP, by first generating a calibration set using the pretrained CLIP, and then calibrating representations of samples within this set through contrastive learning, all without the need for group labels. Extensive experiments and in-depth visualizations on several benchmarks validate the effectiveness of our proposals, largely reducing reliance and significantly boosting the model generalization.
Algebraic and Statistical Properties of the Ordinary Least Squares Interpolator
Sep 27, 2023
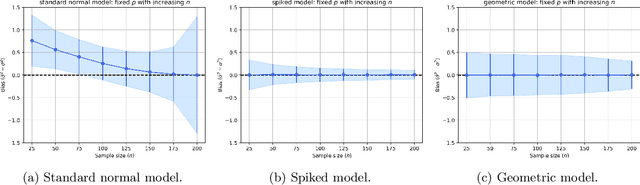

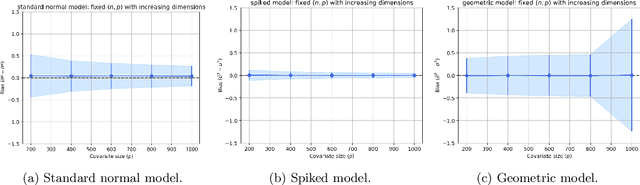
Deep learning research has uncovered the phenomenon of benign overfitting for over-parameterized statistical models, which has drawn significant theoretical interest in recent years. Given its simplicity and practicality, the ordinary least squares (OLS) interpolator has become essential to gain foundational insights into this phenomenon. While properties of OLS are well established in classical settings, its behavior in high-dimensional settings is less explored (unlike for ridge or lasso regression) though significant progress has been made of late. We contribute to this growing literature by providing fundamental algebraic and statistical results for the minimum $\ell_2$-norm OLS interpolator. In particular, we provide high-dimensional algebraic equivalents of (i) the leave-$k$-out residual formula, (ii) Cochran's formula, and (iii) the Frisch-Waugh-Lovell theorem. These results aid in understanding the OLS interpolator's ability to generalize and have substantive implications for causal inference. Additionally, under the Gauss-Markov model, we present statistical results such as a high-dimensional extension of the Gauss-Markov theorem and an analysis of variance estimation under homoskedastic errors. To substantiate our theoretical contributions, we conduct simulation studies that further explore the stochastic properties of the OLS interpolator.
ACTION++: Improving Semi-supervised Medical Image Segmentation with Adaptive Anatomical Contrast
Apr 07, 2023
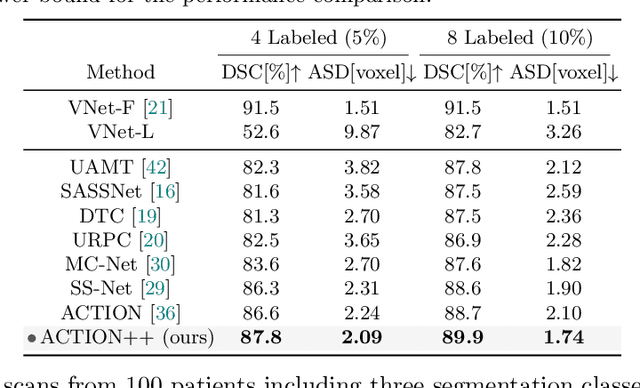
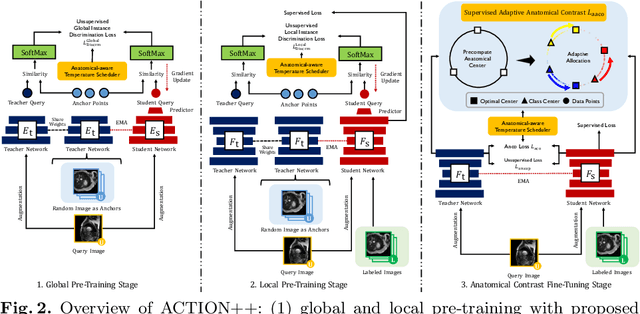
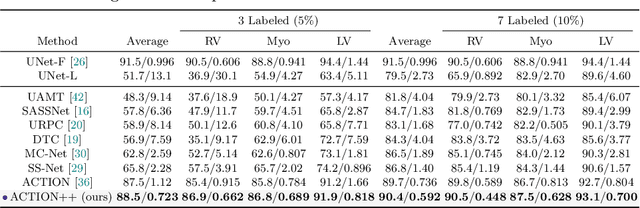
Medical data often exhibits long-tail distributions with heavy class imbalance, which naturally leads to difficulty in classifying the minority classes (i.e., boundary regions or rare objects). Recent work has significantly improved semi-supervised medical image segmentation in long-tailed scenarios by equipping them with unsupervised contrastive criteria. However, it remains unclear how well they will perform in the labeled portion of data where class distribution is also highly imbalanced. In this work, we present ACTION++, an improved contrastive learning framework with adaptive anatomical contrast for semi-supervised medical segmentation. Specifically, we propose an adaptive supervised contrastive loss, where we first compute the optimal locations of class centers uniformly distributed on the embedding space (i.e., off-line), and then perform online contrastive matching training by encouraging different class features to adaptively match these distinct and uniformly distributed class centers. Moreover, we argue that blindly adopting a constant temperature $\tau$ in the contrastive loss on long-tailed medical data is not optimal, and propose to use a dynamic $\tau$ via a simple cosine schedule to yield better separation between majority and minority classes. Empirically, we evaluate ACTION++ on ACDC and LA benchmarks and show that it achieves state-of-the-art across two semi-supervised settings. Theoretically, we analyze the performance of adaptive anatomical contrast and confirm its superiority in label efficiency.
Hybridized Threshold Clustering for Massive Data
Jul 05, 2019
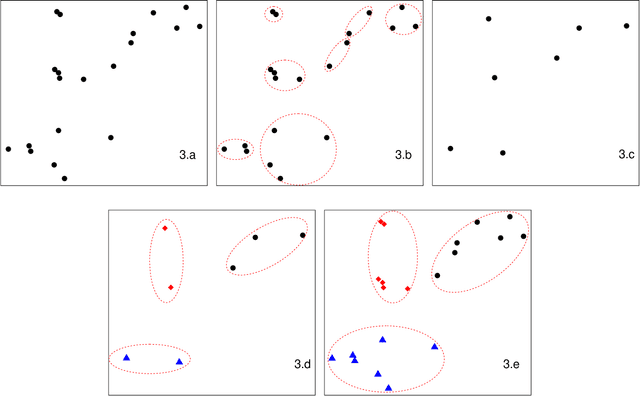
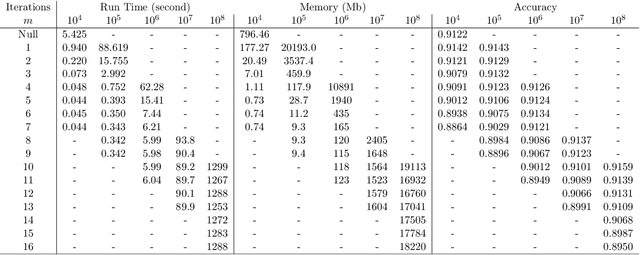
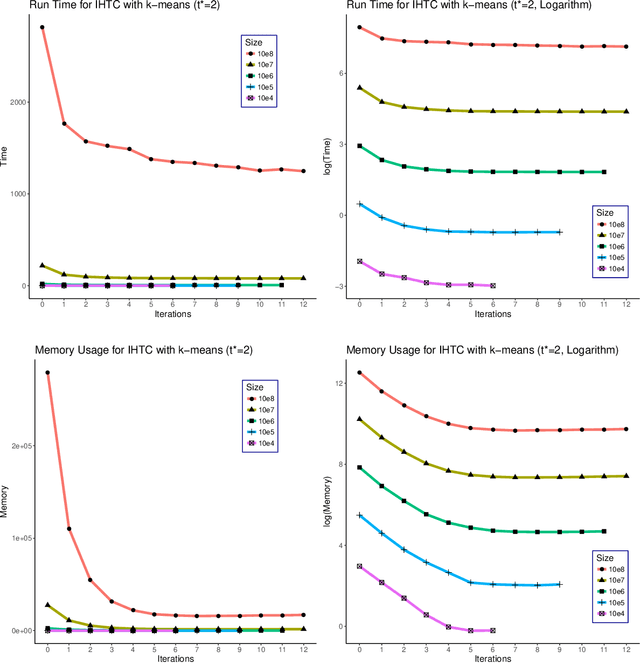
As the size $n$ of datasets become massive, many commonly-used clustering algorithms (for example, $k$-means or hierarchical agglomerative clustering (HAC) require prohibitive computational cost and memory. In this paper, we propose a solution to these clustering problems by extending threshold clustering (TC) to problems of instance selection. TC is a recently developed clustering algorithm designed to partition data into many small clusters in linearithmic time (on average). Our proposed clustering method is as follows. First, TC is performed and clusters are reduced into single "prototype" points. Then, TC is applied repeatedly on these prototype points until sufficient data reduction has been obtained. Finally, a more sophisticated clustering algorithm is applied to the reduced prototype points, thereby obtaining a clustering on all $n$ data points. This entire procedure for clustering is called iterative hybridized threshold clustering (IHTC). Through simulation results and by applying our methodology on several real datasets, we show that IHTC combined with $k$-means or HAC substantially reduces the run time and memory usage of the original clustering algorithms while still preserving their performance. Additionally, IHTC helps prevent singular data points from being overfit by clustering algorithms.
Transfer Learning for Estimating Causal Effects using Neural Networks
Aug 23, 2018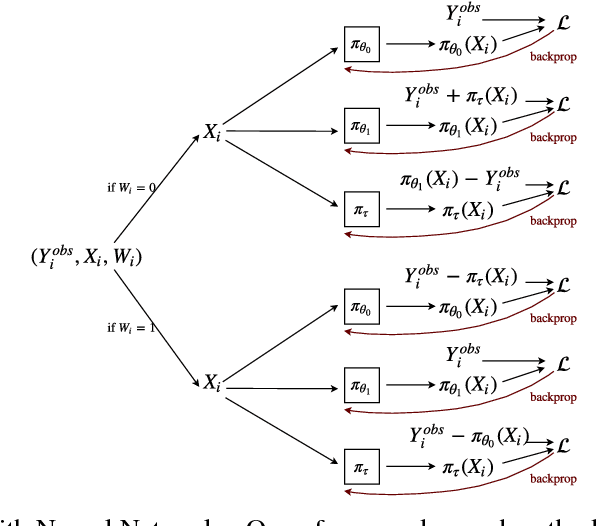
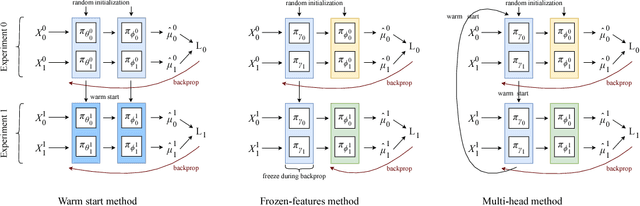
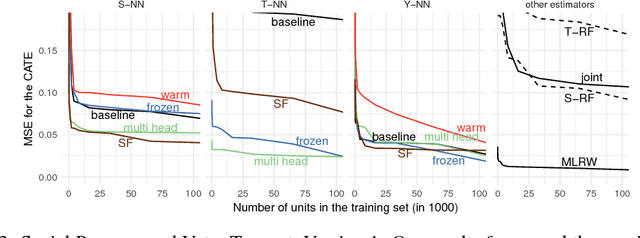
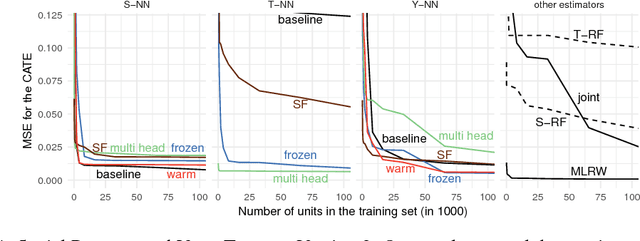
We develop new algorithms for estimating heterogeneous treatment effects, combining recent developments in transfer learning for neural networks with insights from the causal inference literature. By taking advantage of transfer learning, we are able to efficiently use different data sources that are related to the same underlying causal mechanisms. We compare our algorithms with those in the extant literature using extensive simulation studies based on large-scale voter persuasion experiments and the MNIST database. Our methods can perform an order of magnitude better than existing benchmarks while using a fraction of the data.