 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Computational Inefficiency of Large Batch Sizes for Stochastic Gradient Descent
Nov 30, 2018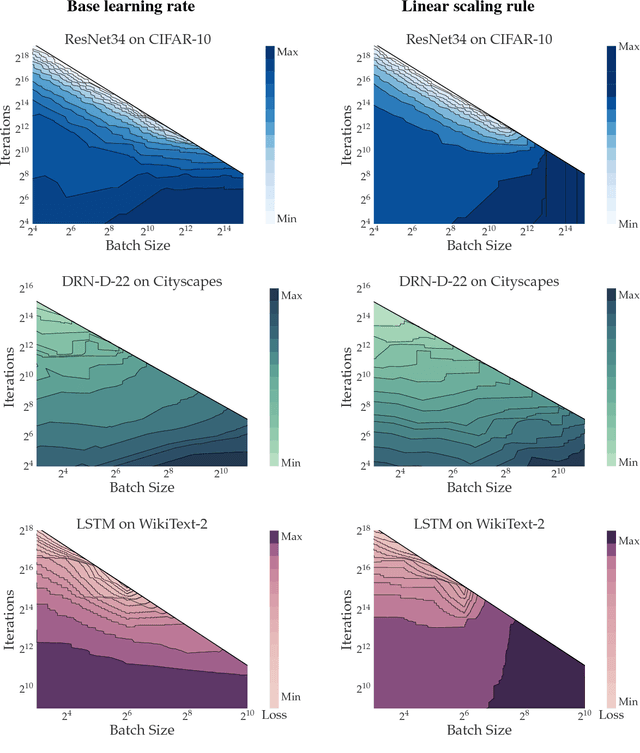
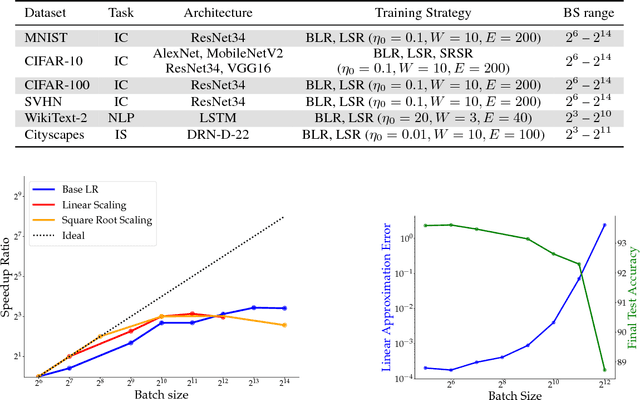
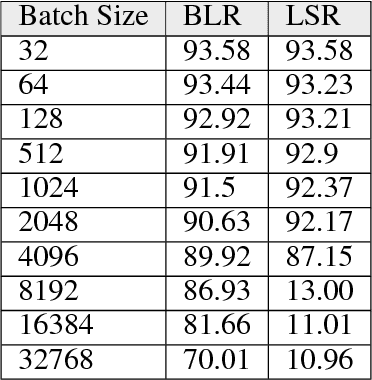

Increasing the mini-batch size for stochastic gradient descent offers significant opportunities to reduce wall-clock training time, but there are a variety of theoretical and systems challenges that impede the widespread success of this technique. We investigate these issues, with an emphasis on time to convergence and total computational cost, through an extensive empirical analysis of network training across several architectures and problem domains, including image classification, image segmentation, and language modeling. Although it is common practice to increase the batch size in order to fully exploit available computational resources, we find a substantially more nuanced picture. Our main finding is that across a wide range of network architectures and problem domains, increasing the batch size beyond a certain point yields no decrease in wall-clock time to convergence for \emph{either} train or test loss. This batch size is usually substantially below the capacity of current systems. We show that popular training strategies for large batch size optimization begin to fail before we can populate all available compute resources, and we show that the point at which these methods break down depends more on attributes like model architecture and data complexity than it does directly on the size of the dataset.
Transfer Learning for Estimating Causal Effects using Neural Networks
Aug 23, 2018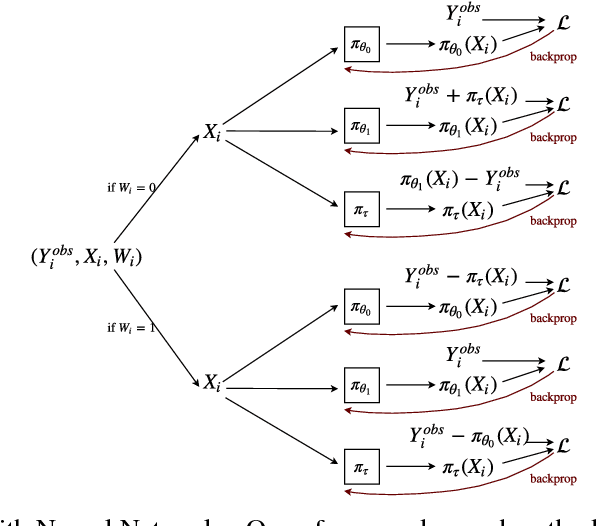
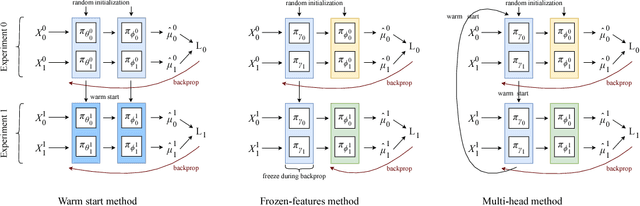
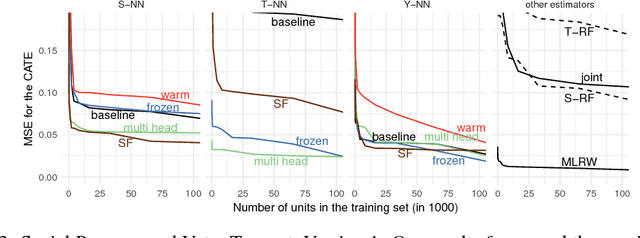
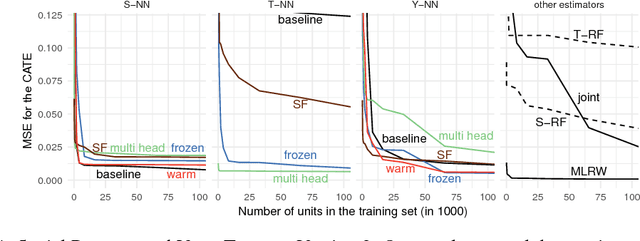
We develop new algorithms for estimating heterogeneous treatment effects, combining recent developments in transfer learning for neural networks with insights from the causal inference literature. By taking advantage of transfer learning, we are able to efficiently use different data sources that are related to the same underlying causal mechanisms. We compare our algorithms with those in the extant literature using extensive simulation studies based on large-scale voter persuasion experiments and the MNIST database. Our methods can perform an order of magnitude better than existing benchmarks while using a fraction of the data.
Targeted Adversarial Examples for Black Box Audio Systems
May 20, 2018
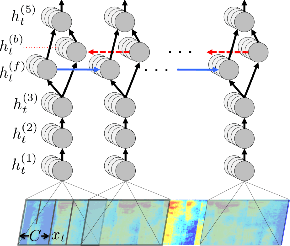
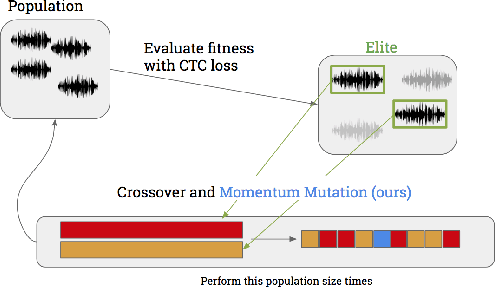

The application of deep recurrent networks to audio transcription has led to impressive gains in automatic speech recognition (ASR) systems. Many have demonstrated that small adversarial perturbations can fool deep neural networks into incorrectly predicting a specified target with high confidence. Current work on fooling ASR systems have focused on white-box attacks, in which the model architecture and parameters are known. In this paper, we adopt a black-box approach to adversarial generation, combining the approaches of both genetic algorithms and gradient estimation to solve the task. We achieve a 89.25% targeted attack similarity after 3000 generations while maintaining 94.6% audio file similarity.