 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Context Diffusion Language Models
Jan 30, 2026Diffusion Large Language Models (dLLMs) have emerged as a promising alternative to purely autoregressive language models because they can decode multiple tokens in parallel. However, state-of-the-art block-wise dLLMs rely on a "remasking" mechanism that decodes only the most confident tokens and discards the rest, effectively wasting computation. We demonstrate that recycling computation from the discarded tokens is beneficial, as these tokens retain contextual information useful for subsequent decoding iterations. In light of this, we propose Residual Context Diffusion (RCD), a module that converts these discarded token representations into contextual residuals and injects them back for the next denoising step. RCD uses a decoupled two-stage training pipeline to bypass the memory bottlenecks associated with backpropagation. We validate our method on both long CoT reasoning (SDAR) and short CoT instruction following (LLaDA) models. We demonstrate that a standard dLLM can be efficiently converted to the RCD paradigm with merely ~1 billion tokens. RCD consistently improves frontier dLLMs by 5-10 points in accuracy with minimal extra computation overhead across a wide range of benchmarks. Notably, on the most challenging AIME tasks, RCD nearly doubles baseline accuracy and attains up to 4-5x fewer denoising steps at equivalent accuracy levels.
XQuant: Breaking the Memory Wall for LLM Inference with KV Cache Rematerialization
Aug 14, 2025Although LLM inference has emerged as a critical workload for many downstream applications, efficiently inferring LLMs is challenging due to the substantial memory footprint and bandwidth requirements. In parallel, compute capabilities have steadily outpaced both memory capacity and bandwidth over the last few decades, a trend that remains evident in modern GPU hardware and exacerbates the challenge of LLM inference. As such, new algorithms are emerging that trade increased computation for reduced memory operations. To that end, we present XQuant, which takes advantage of this trend, enabling an order-of-magnitude reduction in memory consumption through low-bit quantization with substantial accuracy benefits relative to state-of-the-art KV cache quantization methods. We accomplish this by quantizing and caching the layer input activations X, instead of using standard KV caching, and then rematerializing the Keys and Values on-the-fly during inference. This results in an immediate 2$\times$ memory savings compared to KV caching. By applying XQuant, we achieve up to $\sim 7.7\times$ memory savings with $<0.1$ perplexity degradation compared to the FP16 baseline. Furthermore, our approach leverages the fact that X values are similar across layers. Building on this observation, we introduce XQuant-CL, which exploits the cross-layer similarity in the X embeddings for extreme compression. Across different models, XQuant-CL attains up to 10$\times$ memory savings relative to the FP16 baseline with only 0.01 perplexity degradation, and 12.5$\times$ memory savings with only $0.1$ perplexity degradation. XQuant exploits the rapidly increasing compute capabilities of hardware platforms to eliminate the memory bottleneck, while surpassing state-of-the-art KV cache quantization methods and achieving near-FP16 accuracy across a wide range of models.
Multipole Attention for Efficient Long Context Reasoning
Jun 16, 2025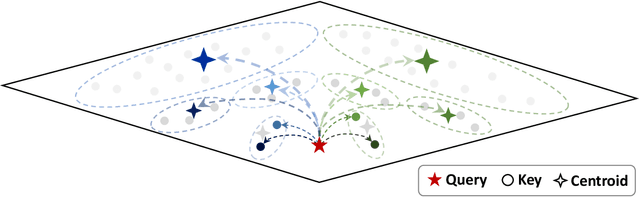

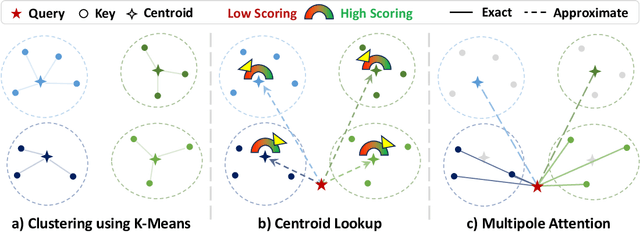
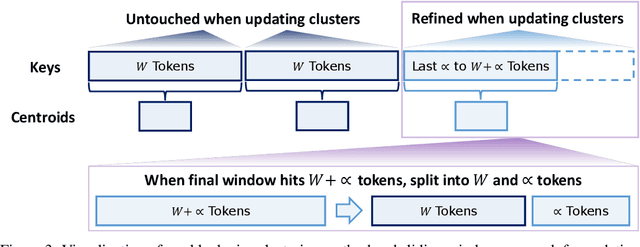
Large Reasoning Models (LRMs) have shown promising accuracy improvements on complex problem-solving tasks. While these models have attained high accuracy by leveraging additional computation at test time, they need to generate long chain-of-thought reasoning in order to think before answering, which requires generating thousands of tokens. While sparse attention methods can help reduce the KV cache pressure induced by this long autoregressive reasoning, these methods can introduce errors which disrupt the reasoning process. Additionally, prior methods often pre-process the input to make it easier to identify the important prompt tokens when computing attention during generation, and this pre-processing is challenging to perform online for newly generated reasoning tokens. Our work addresses these challenges by introducing Multipole Attention, which accelerates autoregressive reasoning by only computing exact attention for the most important tokens, while maintaining approximate representations for the remaining tokens. Our method first performs clustering to group together semantically similar key vectors, and then uses the cluster centroids both to identify important key vectors and to approximate the remaining key vectors in order to retain high accuracy. We design a fast cluster update process to quickly re-cluster the input and previously generated tokens, thereby allowing for accelerating attention to the previous output tokens. We evaluate our method using emerging LRMs such as Qwen-8B, demonstrating that our approach can maintain accuracy on complex reasoning tasks even with aggressive attention sparsity settings. We also provide kernel implementations to demonstrate the practical efficiency gains from our method, achieving up to 4.5$\times$ speedup for attention in long-context reasoning applications. Our code is available at https://github.com/SqueezeAILab/MultipoleAttention.
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks
Mar 12, 2025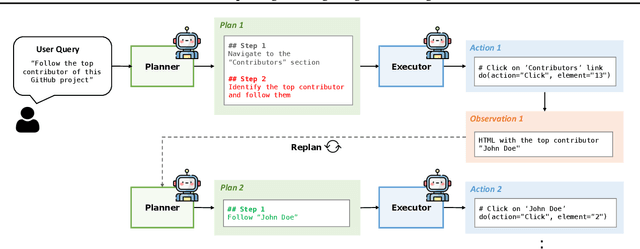
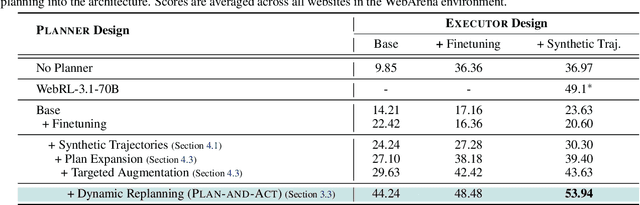
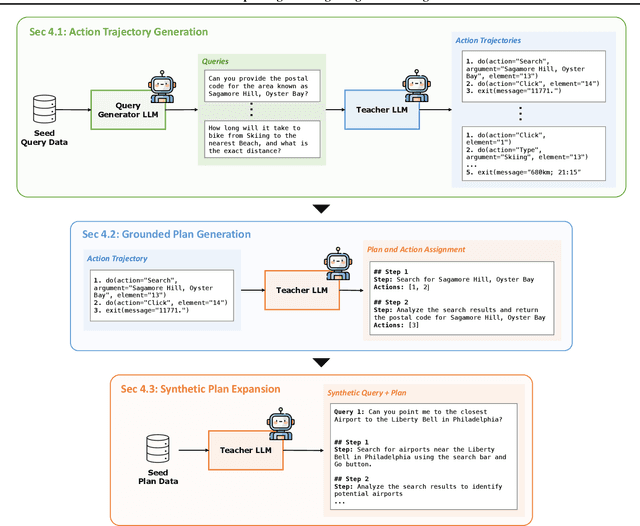
Large language models (LLMs) have shown remarkable advancements in enabling language agents to tackle simple tasks. However, applying them for complex, multi-step, long-horizon tasks remains a challenge. Recent work have found success by separating high-level planning from low-level execution, which enables the model to effectively balance high-level planning objectives and low-level execution details. However, generating accurate plans remains difficult since LLMs are not inherently trained for this task. To address this, we propose Plan-and-Act, a novel framework that incorporates explicit planning into LLM-based agents and introduces a scalable method to enhance plan generation through a novel synthetic data generation method. Plan-and-Act consists of a Planner model which generates structured, high-level plans to achieve user goals, and an Executor model that translates these plans into environment-specific actions. To train the Planner effectively, we introduce a synthetic data generation method that annotates ground-truth trajectories with feasible plans, augmented with diverse and extensive examples to enhance generalization. We evaluate Plan-and-Act using web navigation as a representative long-horizon planning environment, demonstrating a state-of the-art 54% success rate on the WebArena-Lite benchmark.
ETS: Efficient Tree Search for Inference-Time Scaling
Feb 19, 2025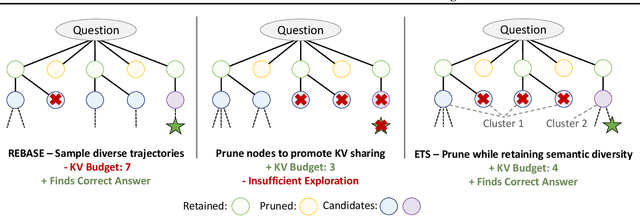
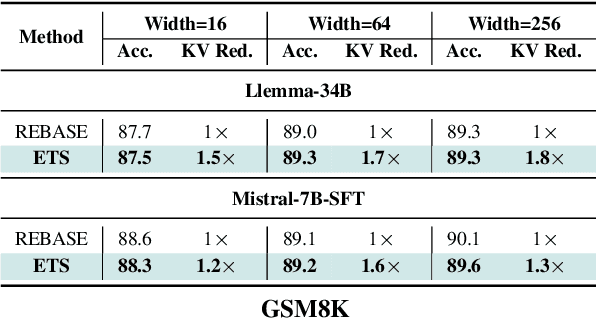
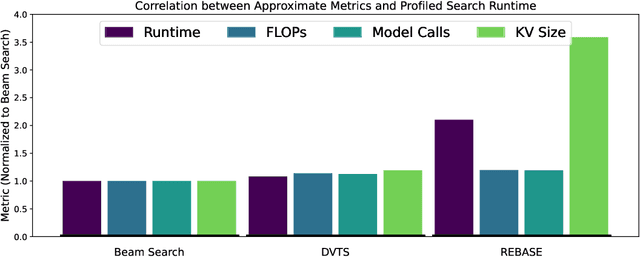
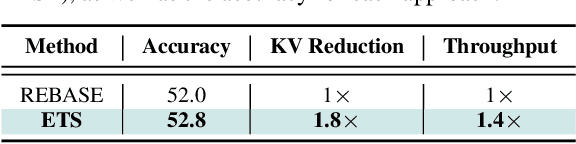
Test-time compute scaling has emerged as a new axis along which to improve model accuracy, where additional computation is used at inference time to allow the model to think longer for more challenging problems. One promising approach for test-time compute scaling is search against a process reward model, where a model generates multiple potential candidates at each step of the search, and these partial trajectories are then scored by a separate reward model in order to guide the search process. The diversity of trajectories in the tree search process affects the accuracy of the search, since increasing diversity promotes more exploration. However, this diversity comes at a cost, as divergent trajectories have less KV sharing, which means they consume more memory and slow down the search process. Previous search methods either do not perform sufficient exploration, or else explore diverse trajectories but have high latency. We address this challenge by proposing Efficient Tree Search (ETS), which promotes KV sharing by pruning redundant trajectories while maintaining necessary diverse trajectories. ETS incorporates a linear programming cost model to promote KV cache sharing by penalizing the number of nodes retained, while incorporating a semantic coverage term into the cost model to ensure that we retain trajectories which are semantically different. We demonstrate how ETS can achieve 1.8$\times$ reduction in average KV cache size during the search process, leading to 1.4$\times$ increased throughput relative to prior state-of-the-art methods, with minimal accuracy degradation and without requiring any custom kernel implementation. Code is available at: https://github.com/SqueezeAILab/ETS.
Squeezed Attention: Accelerating Long Context Length LLM Inference
Nov 14, 2024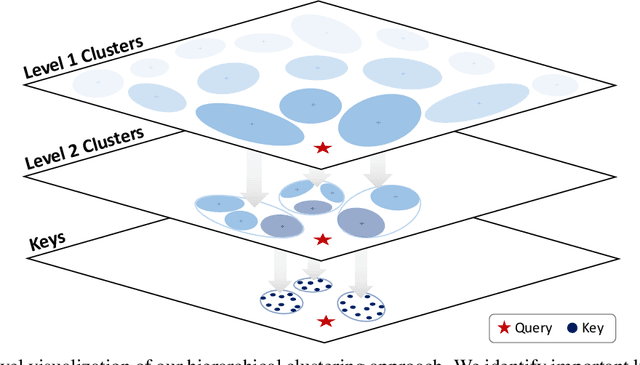
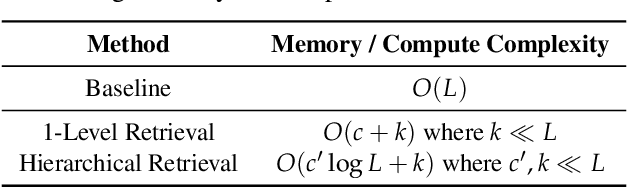
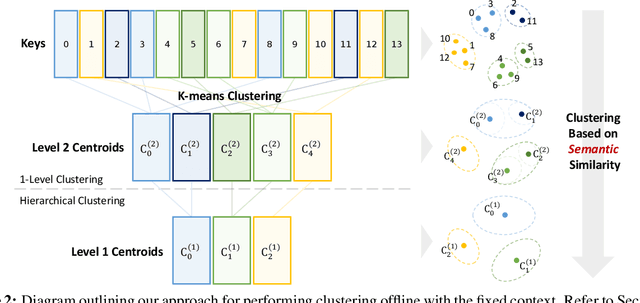
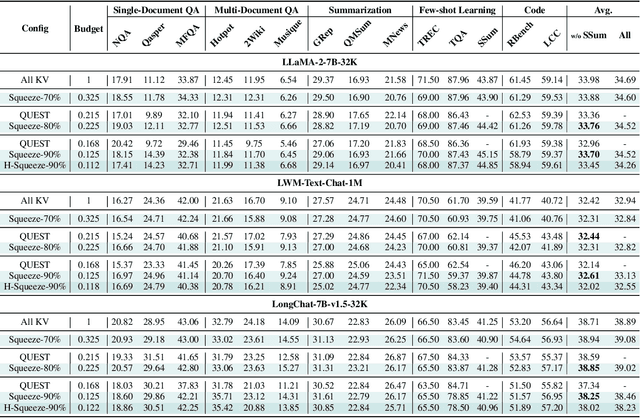
Emerging Large Language Model (LLM) applications require long input prompts to perform complex downstream tasks like document analysis and code generation. For these long context length applications, the length of the input prompt poses a significant challenge in terms of inference efficiency since the inference costs increase linearly with sequence length. However, for many of these applications, much of the context in the prompt is fixed across different user inputs, thereby providing the opportunity to perform offline optimizations to process user inputs quickly, as they are received. In this work, we propose Squeezed Attention as a mechanism to accelerate LLM applications where a large portion of the input prompt is fixed. We first leverage K-means clustering offline to group the keys for the fixed context based on semantic similarity and represent each cluster with a single centroid value. During inference, we compare query tokens from the user input with the centroids to predict which of the keys from the fixed context are semantically relevant and need to be loaded during inference. We then compute exact attention using only these important keys from the fixed context, thereby reducing bandwidth and computational costs. We also extend our method to use a hierarchical centroid lookup to identify important keys, which can reduce the complexity of attention from linear to logarithmic with respect to the context length. We implement optimized Triton kernels for centroid comparison and sparse FlashAttention with important keys, achieving more than 4x speedups during both the prefill and generation phases for long-context inference. Furthermore, we have extensively evaluated our method on various long-context benchmarks including LongBench, where it achieves a 3x reduction in KV cache budget without accuracy loss and up to an 8x reduction with <0.5 point accuracy gap for various models.
Efficient and Scalable Estimation of Tool Representations in Vector Space
Sep 02, 2024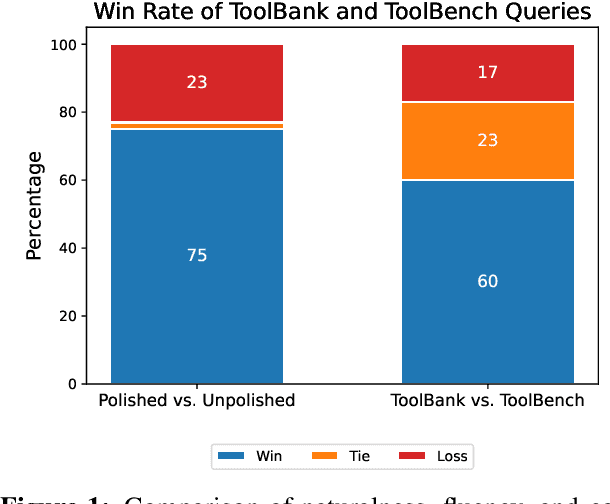
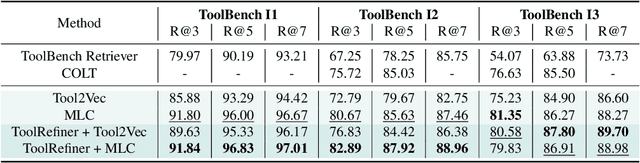
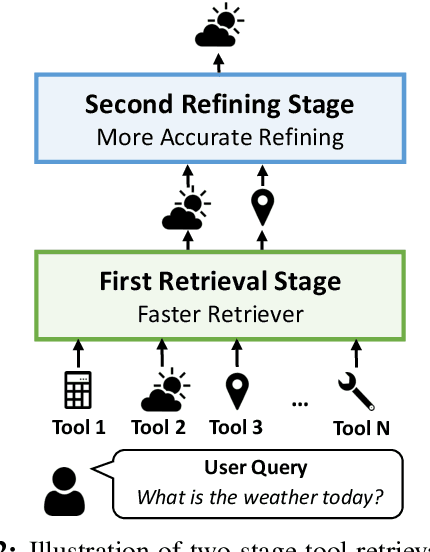
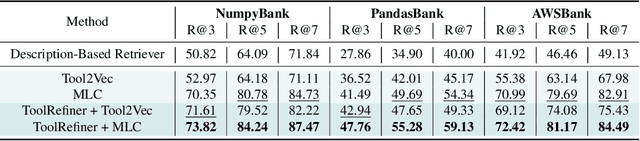
Recent advancements in function calling and tool use have significantly enhanced the capabilities of large language models (LLMs) by enabling them to interact with external information sources and execute complex tasks. However, the limited context window of LLMs presents challenges when a large number of tools are available, necessitating efficient methods to manage prompt length and maintain accuracy. Existing approaches, such as fine-tuning LLMs or leveraging their reasoning capabilities, either require frequent retraining or incur significant latency overhead. A more efficient solution involves training smaller models to retrieve the most relevant tools for a given query, although this requires high quality, domain-specific data. To address those challenges, we present a novel framework for generating synthetic data for tool retrieval applications and an efficient data-driven tool retrieval strategy using small encoder models. Empowered by LLMs, we create ToolBank, a new tool retrieval dataset that reflects real human user usages. For tool retrieval methodologies, we propose novel approaches: (1) Tool2Vec: usage-driven tool embedding generation for tool retrieval, (2) ToolRefiner: a staged retrieval method that iteratively improves the quality of retrieved tools, and (3) MLC: framing tool retrieval as a multi-label classification problem. With these new methods, we achieve improvements of up to 27.28 in Recall@K on the ToolBench dataset and 30.5 in Recall@K on ToolBank. Additionally, we present further experimental results to rigorously validate our methods. Our code is available at \url{https://github.com/SqueezeAILab/Tool2Vec}
TinyAgent: Function Calling at the Edge
Sep 01, 2024



Recent large language models (LLMs) have enabled the development of advanced agentic systems that can integrate various tools and APIs to fulfill user queries through function calling. However, the deployment of these LLMs on the edge has not been explored since they typically require cloud-based infrastructure due to their substantial model size and computational demands. To this end, we present TinyAgent, an end-to-end framework for training and deploying task-specific small language model agents capable of function calling for driving agentic systems at the edge. We first show how to enable accurate function calling for open-source models via the LLMCompiler framework. We then systematically curate a high-quality dataset for function calling, which we use to fine-tune two small language models, TinyAgent-1.1B and 7B. For efficient inference, we introduce a novel tool retrieval method to reduce the input prompt length and utilize quantization to further accelerate the inference speed. As a driving application, we demonstrate a local Siri-like system for Apple's MacBook that can execute user commands through text or voice input. Our results show that our models can achieve, and even surpass, the function-calling capabilities of larger models like GPT-4-Turbo, while being fully deployed at the edge. We open-source our dataset, models, and installable package and provide a demo video for our MacBook assistant agent.
Characterizing Prompt Compression Methods for Long Context Inference
Jul 11, 2024
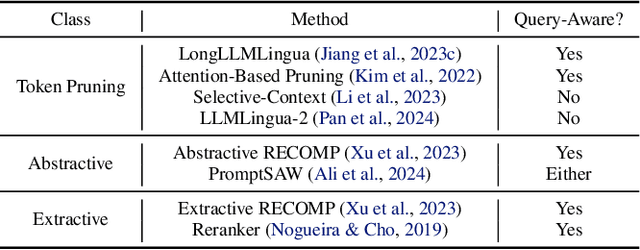
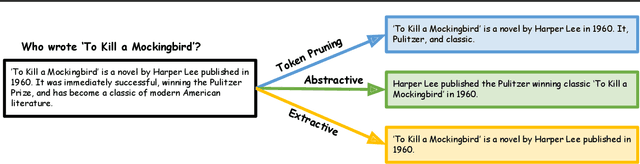

Long context inference presents challenges at the system level with increased compute and memory requirements, as well as from an accuracy perspective in being able to reason over long contexts. Recently, several methods have been proposed to compress the prompt to reduce the context length. However, there has been little work on comparing the different proposed methods across different tasks through a standardized analysis. This has led to conflicting results. To address this, here we perform a comprehensive characterization and evaluation of different prompt compression methods. In particular, we analyze extractive compression, summarization-based abstractive compression, and token pruning methods. Surprisingly, we find that extractive compression often outperforms all the other approaches, and enables up to 10x compression with minimal accuracy degradation. Interestingly, we also find that despite several recent claims, token pruning methods often lag behind extractive compression. We only found marginal improvements on summarization tasks.
Reliable edge machine learning hardware for scientific applications
Jun 27, 2024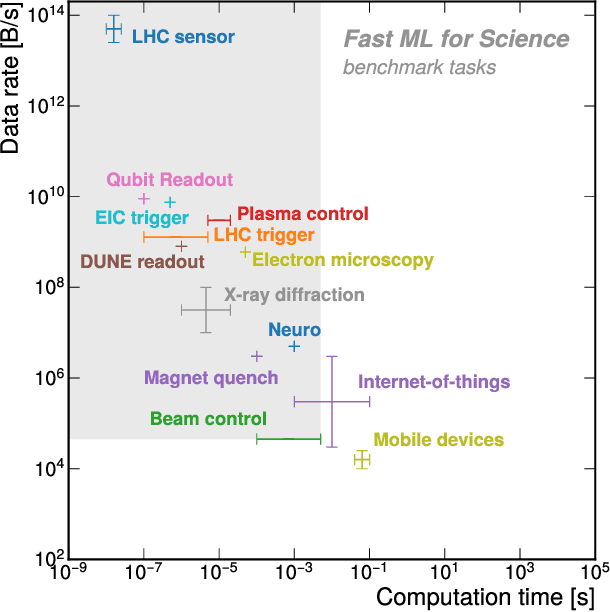
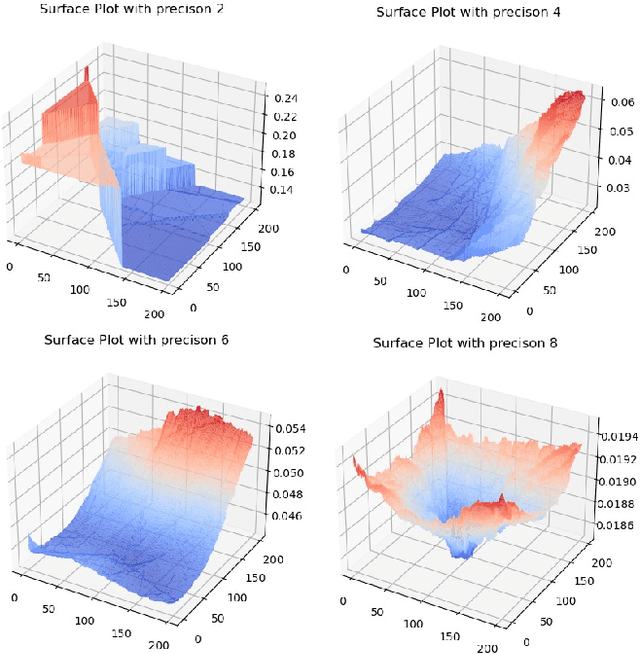
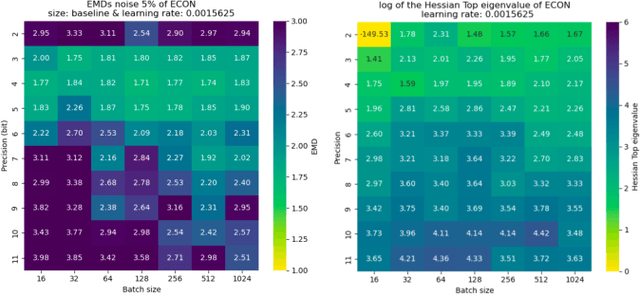
Extreme data rate scientific experiments create massive amounts of data that require efficient ML edge processing. This leads to unique validation challenges for VLSI implementations of ML algorithms: enabling bit-accurate functional simulations for performance validation in experimental software frameworks, verifying those ML models are robust under extreme quantization and pruning, and enabling ultra-fine-grained model inspection for efficient fault tolerance. We discuss approaches to developing and validating reliable algorithms at the scientific edge under such strict latency, resource, power, and area requirements in extreme experimental environments. We study metrics for developing robust algorithms, present preliminary results and mitigation strategies, and conclude with an outlook of these and future directions of research towards the longer-term goal of developing autonomous scientific experimentation methods for accelerated scientific discovery.