 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultipole Attention for Efficient Long Context Reasoning
Jun 16, 2025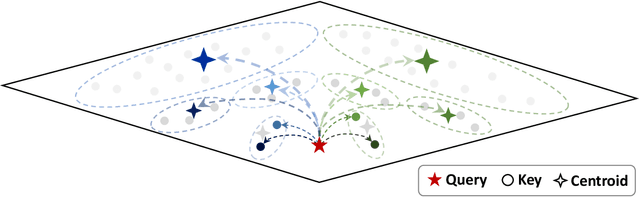

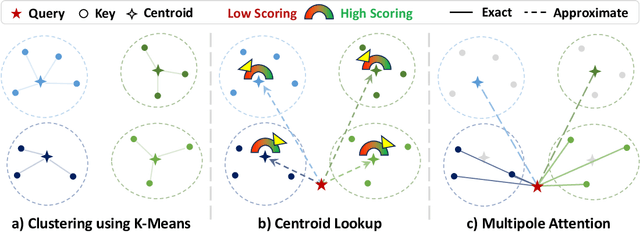
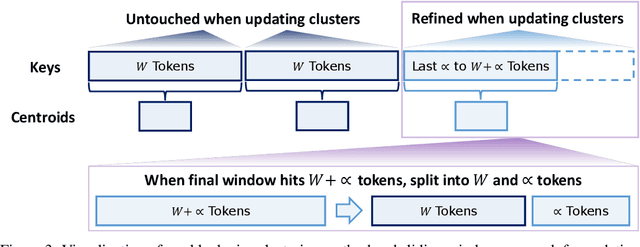
Large Reasoning Models (LRMs) have shown promising accuracy improvements on complex problem-solving tasks. While these models have attained high accuracy by leveraging additional computation at test time, they need to generate long chain-of-thought reasoning in order to think before answering, which requires generating thousands of tokens. While sparse attention methods can help reduce the KV cache pressure induced by this long autoregressive reasoning, these methods can introduce errors which disrupt the reasoning process. Additionally, prior methods often pre-process the input to make it easier to identify the important prompt tokens when computing attention during generation, and this pre-processing is challenging to perform online for newly generated reasoning tokens. Our work addresses these challenges by introducing Multipole Attention, which accelerates autoregressive reasoning by only computing exact attention for the most important tokens, while maintaining approximate representations for the remaining tokens. Our method first performs clustering to group together semantically similar key vectors, and then uses the cluster centroids both to identify important key vectors and to approximate the remaining key vectors in order to retain high accuracy. We design a fast cluster update process to quickly re-cluster the input and previously generated tokens, thereby allowing for accelerating attention to the previous output tokens. We evaluate our method using emerging LRMs such as Qwen-8B, demonstrating that our approach can maintain accuracy on complex reasoning tasks even with aggressive attention sparsity settings. We also provide kernel implementations to demonstrate the practical efficiency gains from our method, achieving up to 4.5$\times$ speedup for attention in long-context reasoning applications. Our code is available at https://github.com/SqueezeAILab/MultipoleAttention.
hdl2v: A Code Translation Dataset for Enhanced LLM Verilog Generation
Jun 05, 2025Large language models (LLMs) are playing an increasingly large role in domains such as code generation, including hardware code generation, where Verilog is the key language. However, the amount of publicly available Verilog code pales in comparison to the amount of code available for software languages like Python. In this work, we present hdl2v ("HDL-to-Verilog"), a dataset which seeks to increase the amount of available human-written Verilog data by translating or compiling three other hardware description languages - VHDL, Chisel, and PyMTL3 - to Verilog. Furthermore, we demonstrate the value of hdl2v in enhancing LLM Verilog generation by improving performance of a 32 billion-parameter open-weight model by up to 23% (pass@10) in VerilogEvalV2, without utilizing any data augmentation or knowledge distillation from larger models. We also show hdl2v's ability to boost the performance of a data augmentation-based fine-tuning approach by 63%. Finally, we characterize and analyze our dataset to better understand which characteristics of HDL-to-Verilog datasets can be expanded upon in future work for even better performance.
Autocomp: LLM-Driven Code Optimization for Tensor Accelerators
May 24, 2025Hardware accelerators, especially those designed for tensor processing, have become ubiquitous in today's computing landscape. However, even with significant efforts in building compilers, programming these tensor accelerators remains challenging, leaving much of their potential underutilized. Recently, large language models (LLMs), trained on large amounts of code, have shown significant promise in code generation and optimization tasks, but generating low-resource languages like specialized tensor accelerator code still poses a significant challenge. We tackle this challenge with Autocomp, an approach that empowers accelerator programmers to leverage domain knowledge and hardware feedback to optimize code via an automated LLM-driven search. We accomplish this by: 1) formulating each optimization pass as a structured two-phase prompt, divided into planning and code generation phases, 2) inserting domain knowledge during planning via a concise and adaptable optimization menu, and 3) integrating correctness and performance metrics from hardware as feedback at each search iteration. Across three categories of representative workloads and two different accelerators, we demonstrate that Autocomp-optimized code runs 5.6x (GEMM) and 2.7x (convolution) faster than the vendor-provided library, and outperforms expert-level hand-tuned code by 1.4x (GEMM), 1.1x (convolution), and 1.3x (fine-grained linear algebra). Additionally, we demonstrate that optimization schedules generated from Autocomp can be reused across similar tensor operations, improving speedups by up to 24% under a fixed sample budget.
Design Space Exploration of Embedded SoC Architectures for Real-Time Optimal Control
Oct 16, 2024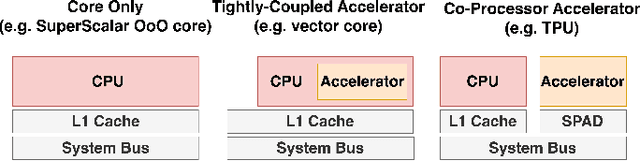
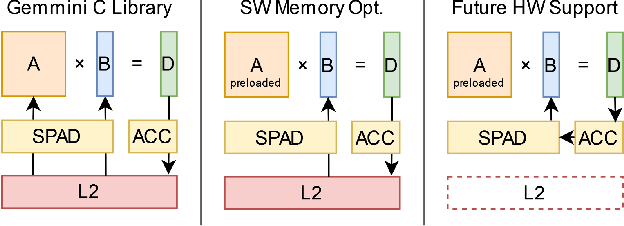
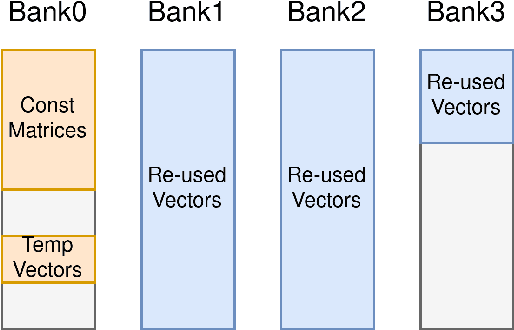
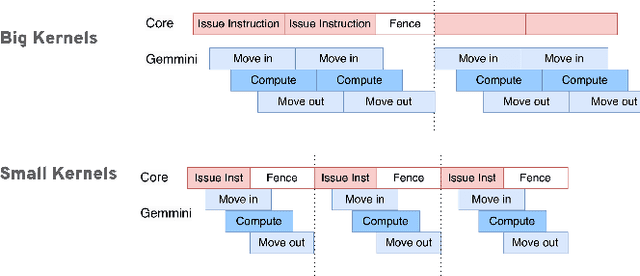
Empowering resource-limited robots to execute computationally intensive tasks like model/learning-based algorithms is challenging. Due to the complexity of the workload characteristic, the bottlenecks in different systems can depend on application requirements, preventing a single hardware architecture from being adequate across all robotics applications. This project provides a comprehensive design space exploration to determine optimal hardware computation platforms and architectures suitable for robotic algorithms. We profile and optimize representative architectural designs across general-purpose cores and specialized accelerators. Specifically, we compare CPUs, vector machines, and domain-specialized accelerators with kernel-level benchmarks and end-to-end representative robotic workloads. Our exploration provides a quantitative performance, area, and utilization comparison and analyzes the trade-offs between these representative distinct architectural designs. We demonstrate that the variation of hardware architecture choices depends on workload characteristics and application requirements. Finally, we explore how architectural modifications and software ecosystem optimization can alleviate bottlenecks and enhance utilization.
LLM-Aided Compilation for Tensor Accelerators
Aug 06, 2024Hardware accelerators, in particular accelerators for tensor processing, have many potential application domains. However, they currently lack the software infrastructure to support the majority of domains outside of deep learning. Furthermore, a compiler that can easily be updated to reflect changes at both application and hardware levels would enable more agile development and design space exploration of accelerators, allowing hardware designers to realize closer-to-optimal performance. In this work, we discuss how large language models (LLMs) could be leveraged to build such a compiler. Specifically, we demonstrate the ability of GPT-4 to achieve high pass rates in translating code to the Gemmini accelerator, and prototype a technique for decomposing translation into smaller, more LLM-friendly steps. Additionally, we propose a 2-phase workflow for utilizing LLMs to generate hardware-optimized code.
KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization
Feb 07, 2024LLMs are seeing growing use for applications such as document analysis and summarization which require large context windows, and with these large context windows KV cache activations surface as the dominant contributor to memory consumption during inference. Quantization is a promising approach for compressing KV cache activations; however, existing solutions fail to represent activations accurately in ultra-low precisions, such as sub-4-bit. In this work, we present KVQuant, which addresses this problem by incorporating novel methods for quantizing cached KV activations, including: (i) Per-Channel Key Quantization, where we adjust the dimension along which we quantize the Key activations to better match the distribution; (ii) Pre-RoPE Key Quantization, where we quantize Key activations before the rotary positional embedding to mitigate its impact on quantization; (iii) Non-Uniform KV Cache Quantization, where we derive per-layer sensitivity-weighted non-uniform datatypes that better represent the distributions; (iv) Per-Vector Dense-and-Sparse Quantization, where we isolate outliers separately for each vector to minimize skews in quantization ranges; and (v) Q-Norm, where we normalize quantization centroids in order to mitigate distribution shift, providing additional benefits for 2-bit quantization. By applying our method to the LLaMA, LLaMA-2, and Mistral models, we achieve $<0.1$ perplexity degradation with 3-bit quantization on both Wikitext-2 and C4, outperforming existing approaches. Our method enables serving the LLaMA-7B model with a context length of up to 1 million on a single A100-80GB GPU and up to 10 million on an 8-GPU system.
MoCA: Memory-Centric, Adaptive Execution for Multi-Tenant Deep Neural Networks
May 10, 2023



Driven by the wide adoption of deep neural networks (DNNs) across different application domains, multi-tenancy execution, where multiple DNNs are deployed simultaneously on the same hardware, has been proposed to satisfy the latency requirements of different applications while improving the overall system utilization. However, multi-tenancy execution could lead to undesired system-level resource contention, causing quality-of-service (QoS) degradation for latency-critical applications. To address this challenge, we propose MoCA, an adaptive multi-tenancy system for DNN accelerators. Unlike existing solutions that focus on compute resource partition, MoCA dynamically manages shared memory resources of co-located applications to meet their QoS targets. Specifically, MoCA leverages the regularities in both DNN operators and accelerators to dynamically modulate memory access rates based on their latency targets and user-defined priorities so that co-located applications get the resources they demand without significantly starving their co-runners. We demonstrate that MoCA improves the satisfaction rate of the service level agreement (SLA) up to 3.9x (1.8x average), system throughput by 2.3x (1.7x average), and fairness by 1.3x (1.2x average), compared to prior work.
Full Stack Optimization of Transformer Inference: a Survey
Feb 27, 2023Recent advances in state-of-the-art DNN architecture design have been moving toward Transformer models. These models achieve superior accuracy across a wide range of applications. This trend has been consistent over the past several years since Transformer models were originally introduced. However, the amount of compute and bandwidth required for inference of recent Transformer models is growing at a significant rate, and this has made their deployment in latency-sensitive applications challenging. As such, there has been an increased focus on making Transformer models more efficient, with methods that range from changing the architecture design, all the way to developing dedicated domain-specific accelerators. In this work, we survey different approaches for efficient Transformer inference, including: (i) analysis and profiling of the bottlenecks in existing Transformer architectures and their similarities and differences with previous convolutional models; (ii) implications of Transformer architecture on hardware, including the impact of non-linear operations such as Layer Normalization, Softmax, and GELU, as well as linear operations, on hardware design; (iii) approaches for optimizing a fixed Transformer architecture; (iv) challenges in finding the right mapping and scheduling of operations for Transformer models; and (v) approaches for optimizing Transformer models by adapting the architecture using neural architecture search. Finally, we perform a case study by applying the surveyed optimizations on Gemmini, the open-source, full-stack DNN accelerator generator, and we show how each of these approaches can yield improvements, compared to previous benchmark results on Gemmini. Among other things, we find that a full-stack co-design approach with the aforementioned methods can result in up to 88.7x speedup with a minimal performance degradation for Transformer inference.
CoSA: Scheduling by Constrained Optimization for Spatial Accelerators
May 05, 2021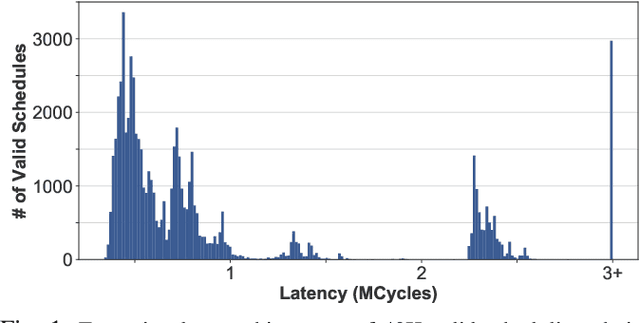
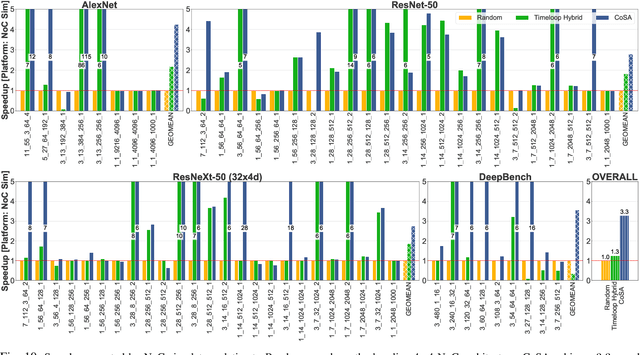
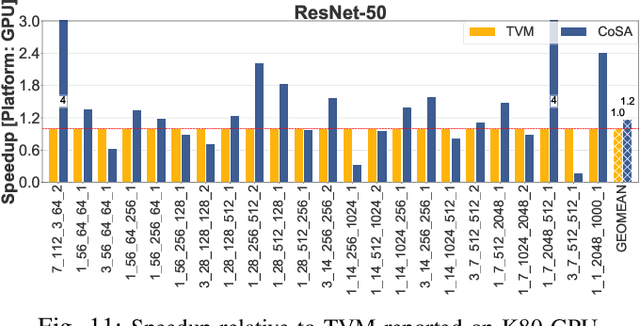
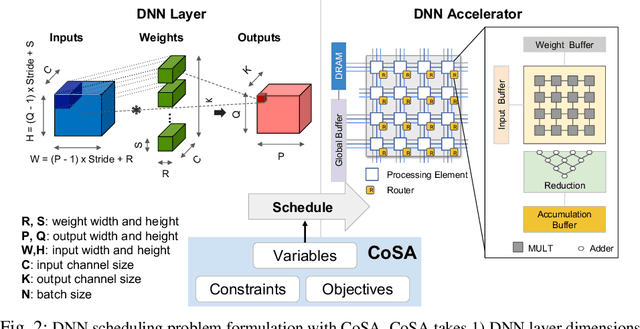
Recent advances in Deep Neural Networks (DNNs) have led to active development of specialized DNN accelerators, many of which feature a large number of processing elements laid out spatially, together with a multi-level memory hierarchy and flexible interconnect. While DNN accelerators can take advantage of data reuse and achieve high peak throughput, they also expose a large number of runtime parameters to the programmers who need to explicitly manage how computation is scheduled both spatially and temporally. In fact, different scheduling choices can lead to wide variations in performance and efficiency, motivating the need for a fast and efficient search strategy to navigate the vast scheduling space. To address this challenge, we present CoSA, a constrained-optimization-based approach for scheduling DNN accelerators. As opposed to existing approaches that either rely on designers' heuristics or iterative methods to navigate the search space, CoSA expresses scheduling decisions as a constrained-optimization problem that can be deterministically solved using mathematical optimization techniques. Specifically, CoSA leverages the regularities in DNN operators and hardware to formulate the DNN scheduling space into a mixed-integer programming (MIP) problem with algorithmic and architectural constraints, which can be solved to automatically generate a highly efficient schedule in one shot. We demonstrate that CoSA-generated schedules significantly outperform state-of-the-art approaches by a geometric mean of up to 2.5x across a wide range of DNN networks while improving the time-to-solution by 90x.
Efficient emotion recognition using hyperdimensional computing with combinatorial channel encoding and cellular automata
Apr 06, 2021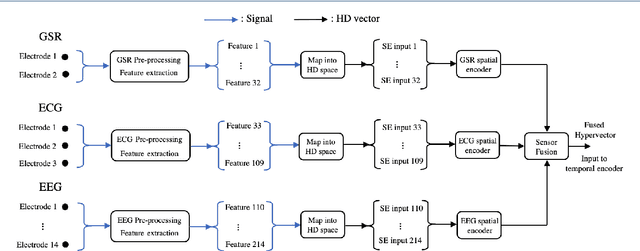
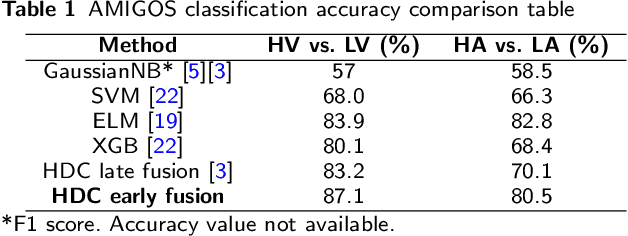
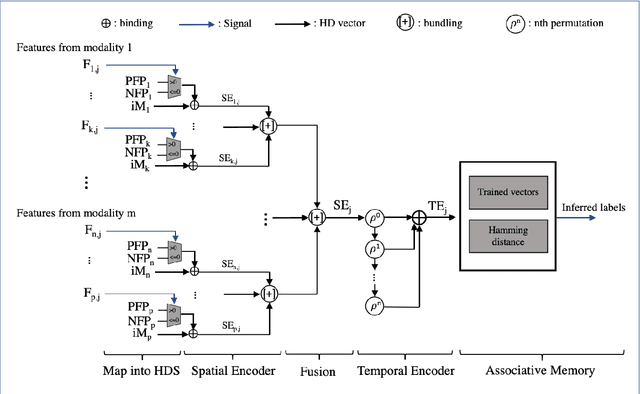
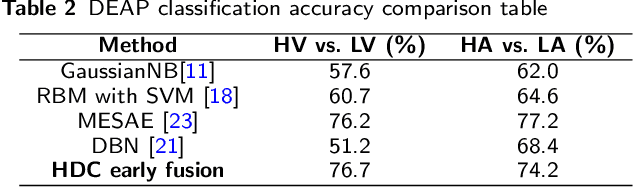
In this paper, a hardware-optimized approach to emotion recognition based on the efficient brain-inspired hyperdimensional computing (HDC) paradigm is proposed. Emotion recognition provides valuable information for human-computer interactions, however the large number of input channels (>200) and modalities (>3) involved in emotion recognition are significantly expensive from a memory perspective. To address this, methods for memory reduction and optimization are proposed, including a novel approach that takes advantage of the combinatorial nature of the encoding process, and an elementary cellular automaton. HDC with early sensor fusion is implemented alongside the proposed techniques achieving two-class multi-modal classification accuracies of >76% for valence and >73% for arousal on the multi-modal AMIGOS and DEAP datasets, almost always better than state of the art. The required vector storage is seamlessly reduced by 98% and the frequency of vector requests by at least 1/5. The results demonstrate the potential of efficient hyperdimensional computing for low-power, multi-channeled emotion recognition tasks.