 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
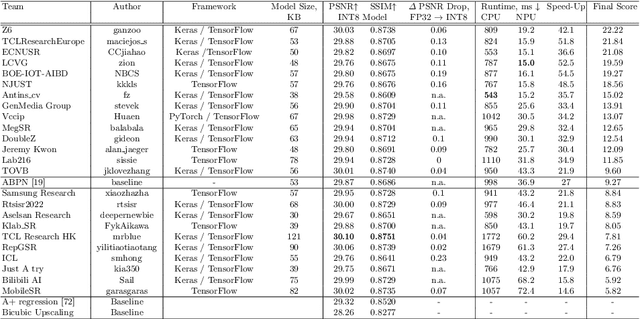
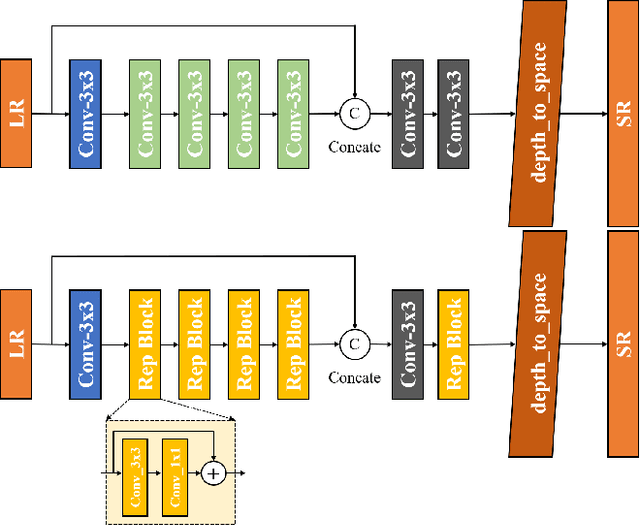
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Gemmini: An Agile Systolic Array Generator Enabling Systematic Evaluations of Deep-Learning Architectures
Dec 07, 2019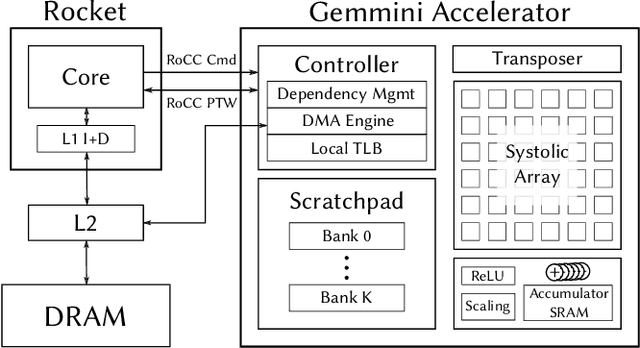
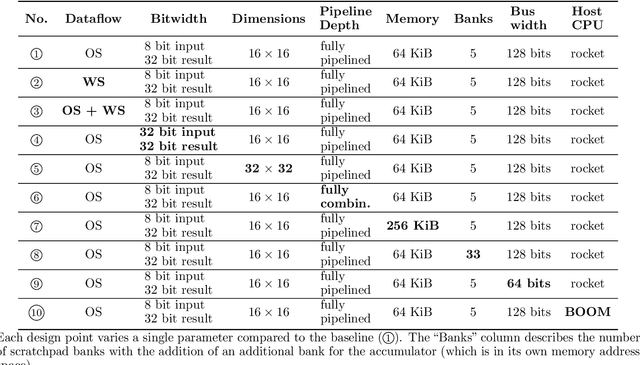
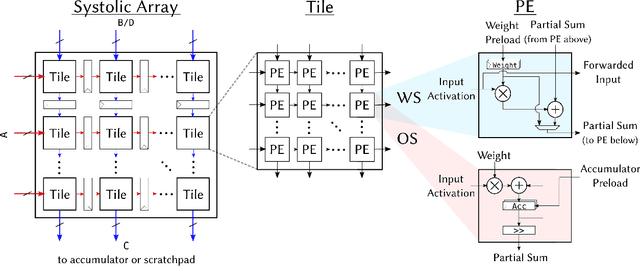
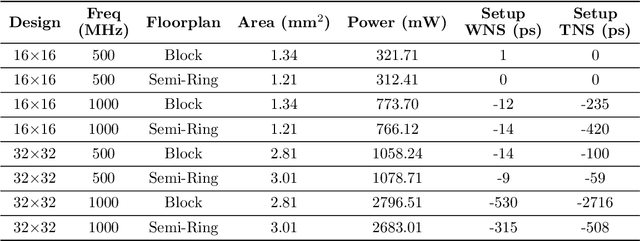
Advances in deep learning and neural networks have resulted in the rapid development of hardware accelerators that support them. A large majority of ASIC accelerators, however, target a single hardware design point to accelerate the main computational kernels of deep neural networks such as convolutions or matrix multiplication. On the other hand, the spectrum of use-cases for neural network accelerators, ranging from edge devices to cloud, presents a prime opportunity for agile hardware design and generator methodologies. We present Gemmini -- an open source and agile systolic array generator enabling systematic evaluations of deep-learning architectures. Gemmini generates a custom ASIC accelerator for matrix multiplication based on a systolic array architecture, complete with additional functions for neural network inference. Gemmini runs with the RISC-V ISA, and is integrated with the Rocket Chip System-on-Chip generator ecosystem, including Rocket in-order cores and BOOM out-of-order cores. Through an elaborate design space exploration case study, this work demonstrates the selection processes of various parameters for the use-case of inference on edge devices. Selected design points achieve two to three orders of magnitude speedup in deep neural network inference compared to the baseline execution on a host processor. Gemmini-generated accelerators were used in the fabrication of test systems-on-chip in TSMC 16nm and Intel 22FFL process technologies.