 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNCT-CRC-HE: Not All Histopathological Datasets Are Equally Useful
Sep 17, 2024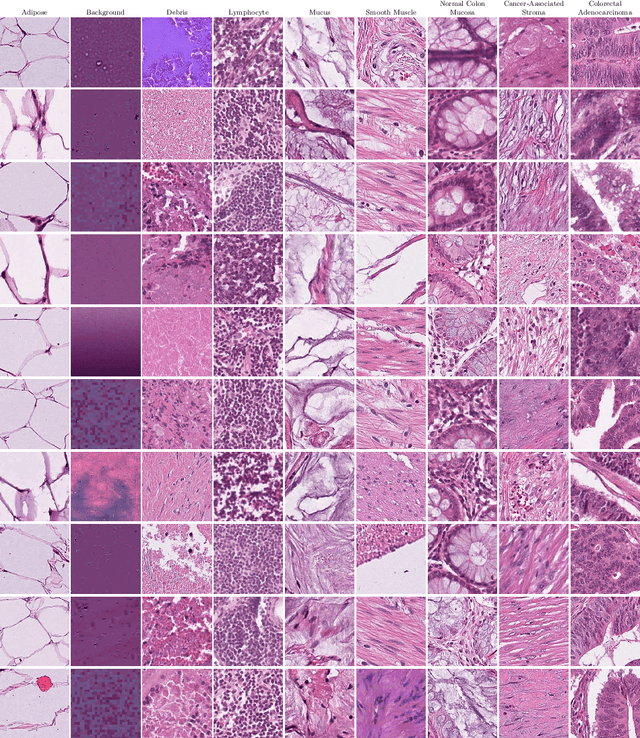
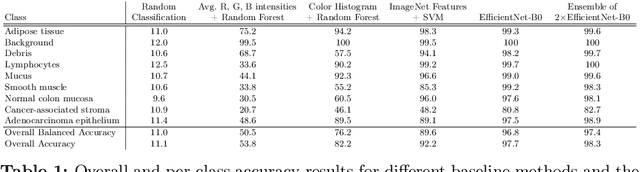
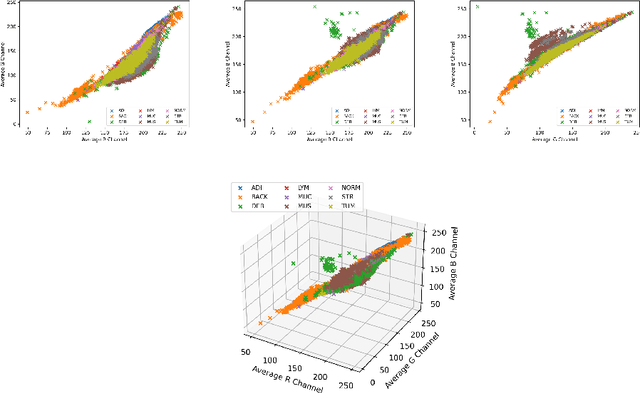

Numerous deep learning-based solutions have been proposed for histopathological image analysis over the past years. While they usually demonstrate exceptionally high accuracy, one key question is whether their precision might be affected by low-level image properties not related to histopathology but caused by microscopy image handling and pre-processing. In this paper, we analyze a popular NCT-CRC-HE-100K colorectal cancer dataset used in numerous prior works and show that both this dataset and the obtained results may be affected by data-specific biases. The most prominent revealed dataset issues are inappropriate color normalization, severe JPEG artifacts inconsistent between different classes, and completely corrupted tissue samples resulting from incorrect image dynamic range handling. We show that even the simplest model using only 3 features per image (red, green and blue color intensities) can demonstrate over 50% accuracy on this 9-class dataset, while using color histogram not explicitly capturing cell morphology features yields over 82% accuracy. Moreover, we show that a basic EfficientNet-B0 ImageNet pretrained model can achieve over 97.7% accuracy on this dataset, outperforming all previously proposed solutions developed for this task, including dedicated foundation histopathological models and large cell morphology-aware neural networks. The NCT-CRC-HE dataset is publicly available and can be freely used to replicate the presented results. The codes and pre-trained models used in this paper are available at https://github.com/gmalivenko/NCT-CRC-HE-experiments
Histopathological Image Classification with Cell Morphology Aware Deep Neural Networks
Jul 11, 2024



Histopathological images are widely used for the analysis of diseased (tumor) tissues and patient treatment selection. While the majority of microscopy image processing was previously done manually by pathologists, recent advances in computer vision allow for accurate recognition of lesion regions with deep learning-based solutions. Such models, however, usually require extensive annotated datasets for training, which is often not the case in the considered task, where the number of available patient data samples is very limited. To deal with this problem, we propose a novel DeepCMorph model pre-trained to learn cell morphology and identify a large number of different cancer types. The model consists of two modules: the first one performs cell nuclei segmentation and annotates each cell type, and is trained on a combination of 8 publicly available datasets to ensure its high generalizability and robustness. The second module combines the obtained segmentation map with the original microscopy image and is trained for the downstream task. We pre-trained this module on the Pan-Cancer TCGA dataset consisting of over 270K tissue patches extracted from 8736 diagnostic slides from 7175 patients. The proposed solution achieved a new state-of-the-art performance on the dataset under consideration, detecting 32 cancer types with over 82% accuracy and outperforming all previously proposed solutions by more than 4%. We demonstrate that the resulting pre-trained model can be easily fine-tuned on smaller microscopy datasets, yielding superior results compared to the current top solutions and models initialized with ImageNet weights. The codes and pre-trained models presented in this paper are available at: https://github.com/aiff22/DeepCMorph
Virtually Enriched NYU Depth V2 Dataset for Monocular Depth Estimation: Do We Need Artificial Augmentation?
Apr 15, 2024We present ANYU, a new virtually augmented version of the NYU depth v2 dataset, designed for monocular depth estimation. In contrast to the well-known approach where full 3D scenes of a virtual world are utilized to generate artificial datasets, ANYU was created by incorporating RGB-D representations of virtual reality objects into the original NYU depth v2 images. We specifically did not match each generated virtual object with an appropriate texture and a suitable location within the real-world image. Instead, an assignment of texture, location, lighting, and other rendering parameters was randomized to maximize a diversity of the training data, and to show that it is randomness that can improve the generalizing ability of a dataset. By conducting extensive experiments with our virtually modified dataset and validating on the original NYU depth v2 and iBims-1 benchmarks, we show that ANYU improves the monocular depth estimation performance and generalization of deep neural networks with considerably different architectures, especially for the current state-of-the-art VPD model. To the best of our knowledge, this is the first work that augments a real-world dataset with randomly generated virtual 3D objects for monocular depth estimation. We make our ANYU dataset publicly available in two training configurations with 10% and 100% additional synthetically enriched RGB-D pairs of training images, respectively, for efficient training and empirical exploration of virtual augmentation at https://github.com/ABrain-One/ANYU
MicroISP: Processing 32MP Photos on Mobile Devices with Deep Learning
Nov 08, 2022



While neural networks-based photo processing solutions can provide a better image quality compared to the traditional ISP systems, their application to mobile devices is still very limited due to their very high computational complexity. In this paper, we present a novel MicroISP model designed specifically for edge devices, taking into account their computational and memory limitations. The proposed solution is capable of processing up to 32MP photos on recent smartphones using the standard mobile ML libraries and requiring less than 1 second to perform the inference, while for FullHD images it achieves real-time performance. The architecture of the model is flexible, allowing to adjust its complexity to devices of different computational power. To evaluate the performance of the model, we collected a novel Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The experiments demonstrated that, despite its compact size, the MicroISP model is able to provide comparable or better visual results than the traditional mobile ISP systems, while outperforming the previously proposed efficient deep learning based solutions. Finally, this model is also compatible with the latest mobile AI accelerators, achieving good runtime and low power consumption on smartphone NPUs and APUs. The code, dataset and pre-trained models are available on the project website: https://people.ee.ethz.ch/~ihnatova/microisp.html
PyNet-V2 Mobile: Efficient On-Device Photo Processing With Neural Networks
Nov 08, 2022The increased importance of mobile photography created a need for fast and performant RAW image processing pipelines capable of producing good visual results in spite of the mobile camera sensor limitations. While deep learning-based approaches can efficiently solve this problem, their computational requirements usually remain too large for high-resolution on-device image processing. To address this limitation, we propose a novel PyNET-V2 Mobile CNN architecture designed specifically for edge devices, being able to process RAW 12MP photos directly on mobile phones under 1.5 second and producing high perceptual photo quality. To train and to evaluate the performance of the proposed solution, we use the real-world Fujifilm UltraISP dataset consisting on thousands of RAW-RGB image pairs captured with a professional medium-format 102MP Fujifilm camera and a popular Sony mobile camera sensor. The results demonstrate that the PyNET-V2 Mobile model can substantially surpass the quality of tradition ISP pipelines, while outperforming the previously introduced neural network-based solutions designed for fast image processing. Furthermore, we show that the proposed architecture is also compatible with the latest mobile AI accelerators such as NPUs or APUs that can be used to further reduce the latency of the model to as little as 0.5 second. The dataset, code and pre-trained models used in this paper are available on the project website: https://github.com/gmalivenko/PyNET-v2
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
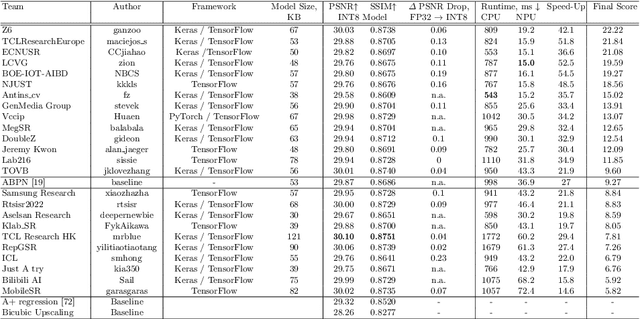
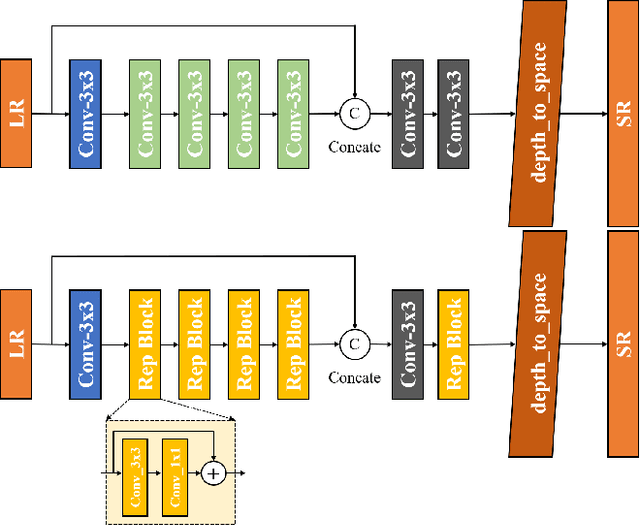
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Realistic Bokeh Effect Rendering on Mobile GPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



As mobile cameras with compact optics are unable to produce a strong bokeh effect, lots of interest is now devoted to deep learning-based solutions for this task. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based bokeh effect rendering approach that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The runtime of the resulting models was evaluated on the Kirin 9000's Mali GPU that provides excellent acceleration results for the majority of common deep learning ops. A detailed description of all models developed in this challenge is provided in this paper.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Efficient Single-Image Depth Estimation on Mobile Devices, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022

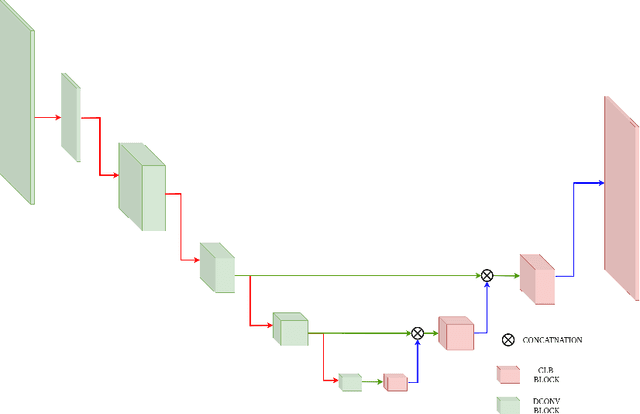
Various depth estimation models are now widely used on many mobile and IoT devices for image segmentation, bokeh effect rendering, object tracking and many other mobile tasks. Thus, it is very crucial to have efficient and accurate depth estimation models that can run fast on low-power mobile chipsets. In this Mobile AI challenge, the target was to develop deep learning-based single image depth estimation solutions that can show a real-time performance on IoT platforms and smartphones. For this, the participants used a large-scale RGB-to-depth dataset that was collected with the ZED stereo camera capable to generated depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the Raspberry Pi 4 platform, where the developed solutions were able to generate VGA resolution depth maps at up to 27 FPS while achieving high fidelity results. All models developed in the challenge are also compatible with any Android or Linux-based mobile devices, their detailed description is provided in this paper.
Learned Smartphone ISP on Mobile GPUs with Deep Learning, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022
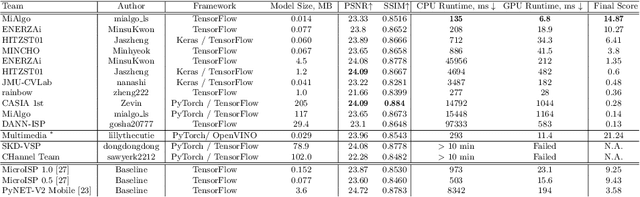
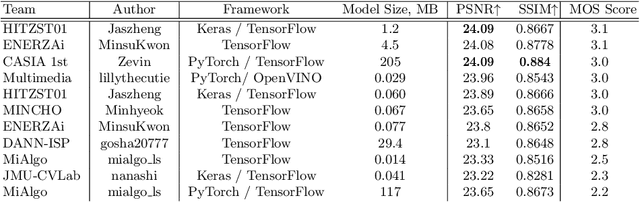
The role of mobile cameras increased dramatically over the past few years, leading to more and more research in automatic image quality enhancement and RAW photo processing. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based image signal processing (ISP) pipeline replacing the standard mobile ISPs that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The runtime of the resulting models was evaluated on the Snapdragon's 8 Gen 1 GPU that provides excellent acceleration results for the majority of common deep learning ops. The proposed solutions are compatible with all recent mobile GPUs, being able to process Full HD photos in less than 20-50 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.