 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroISP: Processing 32MP Photos on Mobile Devices with Deep Learning
Nov 08, 2022



While neural networks-based photo processing solutions can provide a better image quality compared to the traditional ISP systems, their application to mobile devices is still very limited due to their very high computational complexity. In this paper, we present a novel MicroISP model designed specifically for edge devices, taking into account their computational and memory limitations. The proposed solution is capable of processing up to 32MP photos on recent smartphones using the standard mobile ML libraries and requiring less than 1 second to perform the inference, while for FullHD images it achieves real-time performance. The architecture of the model is flexible, allowing to adjust its complexity to devices of different computational power. To evaluate the performance of the model, we collected a novel Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The experiments demonstrated that, despite its compact size, the MicroISP model is able to provide comparable or better visual results than the traditional mobile ISP systems, while outperforming the previously proposed efficient deep learning based solutions. Finally, this model is also compatible with the latest mobile AI accelerators, achieving good runtime and low power consumption on smartphone NPUs and APUs. The code, dataset and pre-trained models are available on the project website: https://people.ee.ethz.ch/~ihnatova/microisp.html
PyNet-V2 Mobile: Efficient On-Device Photo Processing With Neural Networks
Nov 08, 2022The increased importance of mobile photography created a need for fast and performant RAW image processing pipelines capable of producing good visual results in spite of the mobile camera sensor limitations. While deep learning-based approaches can efficiently solve this problem, their computational requirements usually remain too large for high-resolution on-device image processing. To address this limitation, we propose a novel PyNET-V2 Mobile CNN architecture designed specifically for edge devices, being able to process RAW 12MP photos directly on mobile phones under 1.5 second and producing high perceptual photo quality. To train and to evaluate the performance of the proposed solution, we use the real-world Fujifilm UltraISP dataset consisting on thousands of RAW-RGB image pairs captured with a professional medium-format 102MP Fujifilm camera and a popular Sony mobile camera sensor. The results demonstrate that the PyNET-V2 Mobile model can substantially surpass the quality of tradition ISP pipelines, while outperforming the previously introduced neural network-based solutions designed for fast image processing. Furthermore, we show that the proposed architecture is also compatible with the latest mobile AI accelerators such as NPUs or APUs that can be used to further reduce the latency of the model to as little as 0.5 second. The dataset, code and pre-trained models used in this paper are available on the project website: https://github.com/gmalivenko/PyNET-v2
KCP: Kernel Cluster Pruning for Dense Labeling Neural Networks
Jan 17, 2021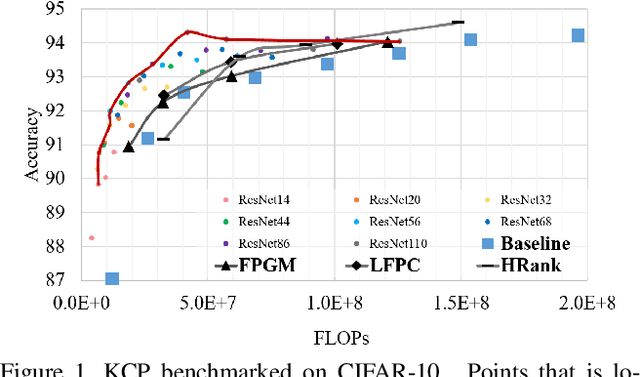
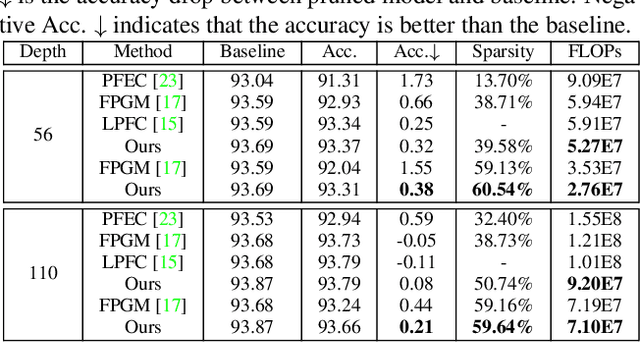
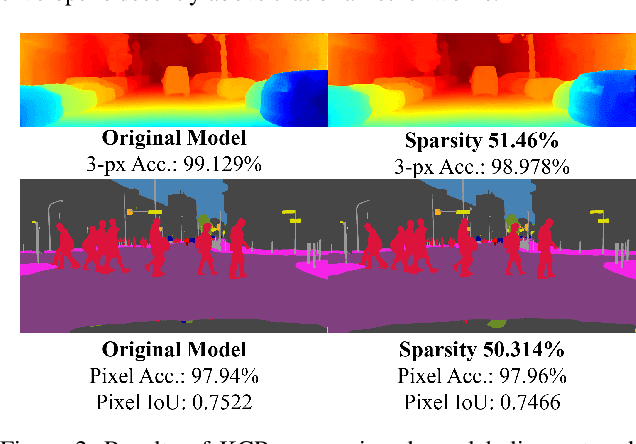
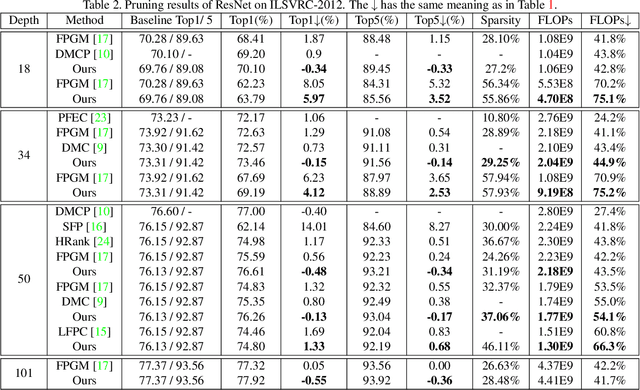
Pruning has become a promising technique used to compress and accelerate neural networks. Existing methods are mainly evaluated on spare labeling applications. However, dense labeling applications are those closer to real world problems that require real-time processing on resource-constrained mobile devices. Pruning for dense labeling applications is still a largely unexplored field. The prevailing filter channel pruning method removes the entire filter channel. Accordingly, the interaction between each kernel in one filter channel is ignored. In this study, we proposed kernel cluster pruning (KCP) to prune dense labeling networks. We developed a clustering technique to identify the least representational kernels in each layer. By iteratively removing those kernels, the parameter that can better represent the entire network is preserved; thus, we achieve better accuracy with a decent model size and computation reduction. When evaluated on stereo matching and semantic segmentation neural networks, our method can reduce more than 70% of FLOPs with less than 1% of accuracy drop. Moreover, for ResNet-50 on ILSVRC-2012, our KCP can reduce more than 50% of FLOPs reduction with 0.13% Top-1 accuracy gain. Therefore, KCP achieves state-of-the-art pruning results.
Joint Pruning & Quantization for Extremely Sparse Neural Networks
Oct 05, 2020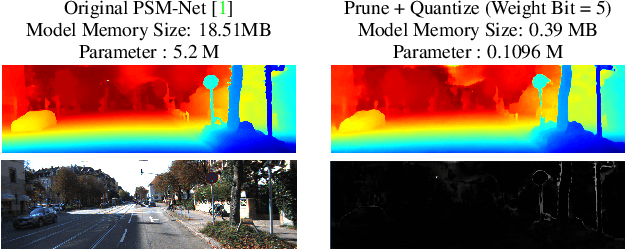
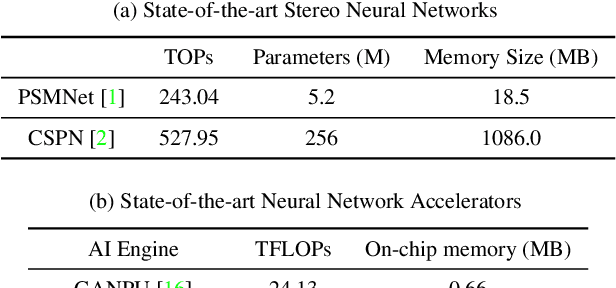
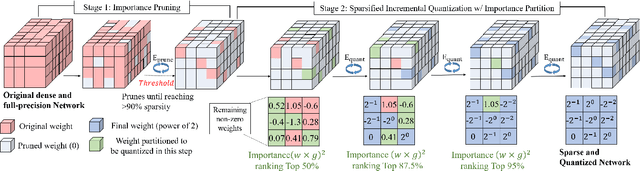
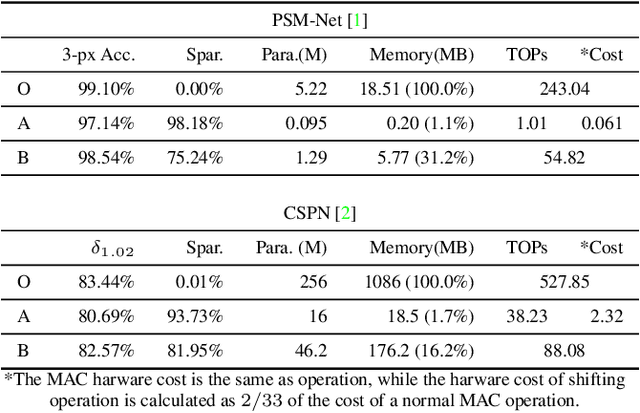
We investigate pruning and quantization for deep neural networks. Our goal is to achieve extremely high sparsity for quantized networks to enable implementation on low cost and low power accelerator hardware. In a practical scenario, there are particularly many applications for dense prediction tasks, hence we choose stereo depth estimation as target. We propose a two stage pruning and quantization pipeline and introduce a Taylor Score alongside a new fine-tuning mode to achieve extreme sparsity without sacrificing performance. Our evaluation does not only show that pruning and quantization should be investigated jointly, but also shows that almost 99% of memory demand can be cut while hardware costs can be reduced up to 99.9%. In addition, to compare with other works, we demonstrate that our pruning stage alone beats the state-of-the-art when applied to ResNet on CIFAR10 and ImageNet.