 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKCP: Kernel Cluster Pruning for Dense Labeling Neural Networks
Jan 17, 2021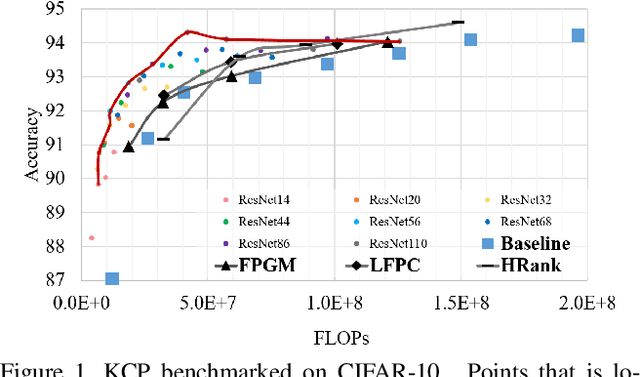
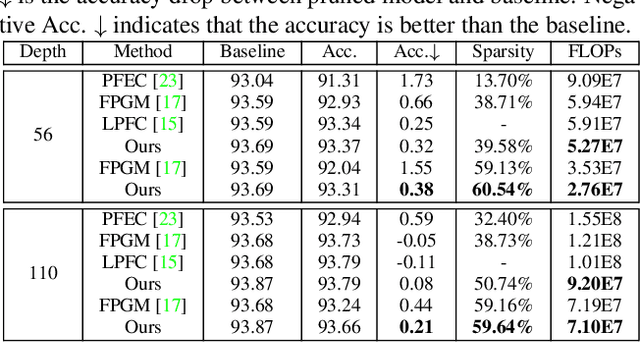
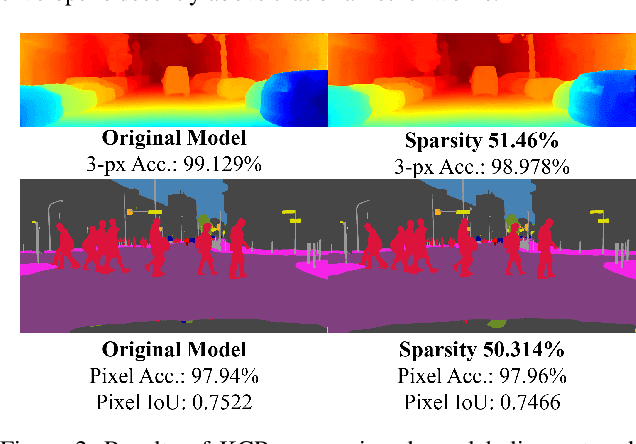
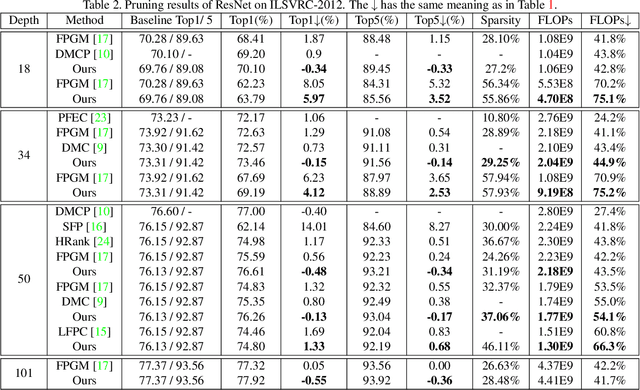
Pruning has become a promising technique used to compress and accelerate neural networks. Existing methods are mainly evaluated on spare labeling applications. However, dense labeling applications are those closer to real world problems that require real-time processing on resource-constrained mobile devices. Pruning for dense labeling applications is still a largely unexplored field. The prevailing filter channel pruning method removes the entire filter channel. Accordingly, the interaction between each kernel in one filter channel is ignored. In this study, we proposed kernel cluster pruning (KCP) to prune dense labeling networks. We developed a clustering technique to identify the least representational kernels in each layer. By iteratively removing those kernels, the parameter that can better represent the entire network is preserved; thus, we achieve better accuracy with a decent model size and computation reduction. When evaluated on stereo matching and semantic segmentation neural networks, our method can reduce more than 70% of FLOPs with less than 1% of accuracy drop. Moreover, for ResNet-50 on ILSVRC-2012, our KCP can reduce more than 50% of FLOPs reduction with 0.13% Top-1 accuracy gain. Therefore, KCP achieves state-of-the-art pruning results.
Joint Pruning & Quantization for Extremely Sparse Neural Networks
Oct 05, 2020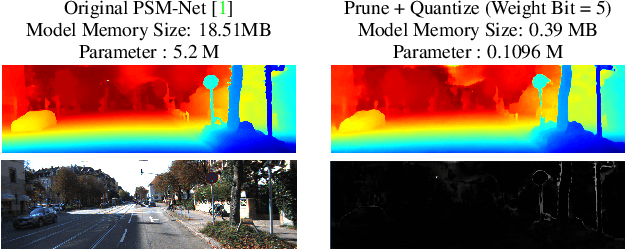
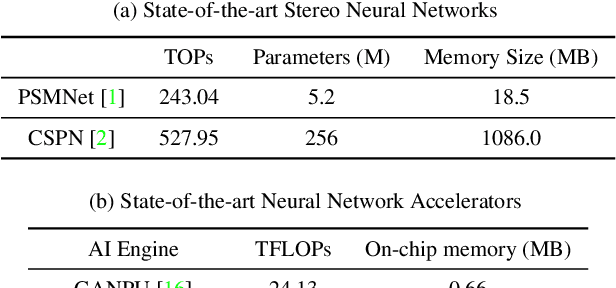
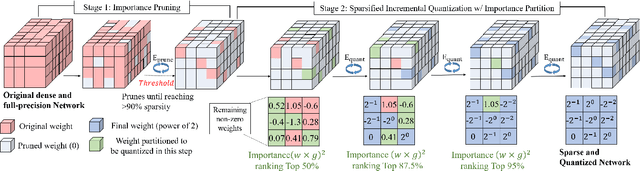
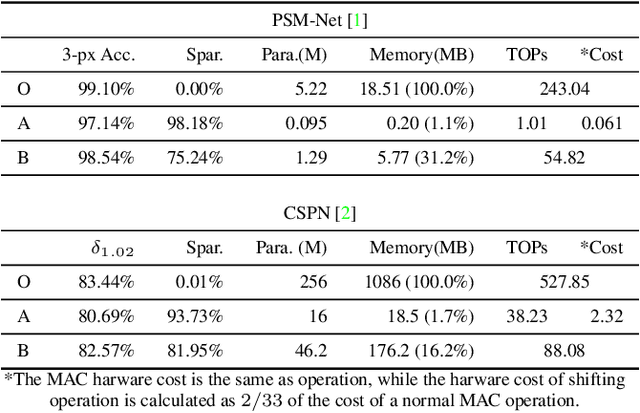
We investigate pruning and quantization for deep neural networks. Our goal is to achieve extremely high sparsity for quantized networks to enable implementation on low cost and low power accelerator hardware. In a practical scenario, there are particularly many applications for dense prediction tasks, hence we choose stereo depth estimation as target. We propose a two stage pruning and quantization pipeline and introduce a Taylor Score alongside a new fine-tuning mode to achieve extreme sparsity without sacrificing performance. Our evaluation does not only show that pruning and quantization should be investigated jointly, but also shows that almost 99% of memory demand can be cut while hardware costs can be reduced up to 99.9%. In addition, to compare with other works, we demonstrate that our pruning stage alone beats the state-of-the-art when applied to ResNet on CIFAR10 and ImageNet.