 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Exploit the Transferability of Learned Image Compression to Conventional Codecs
Dec 03, 2020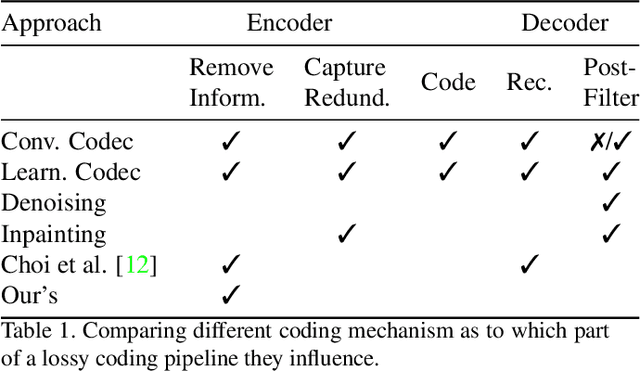
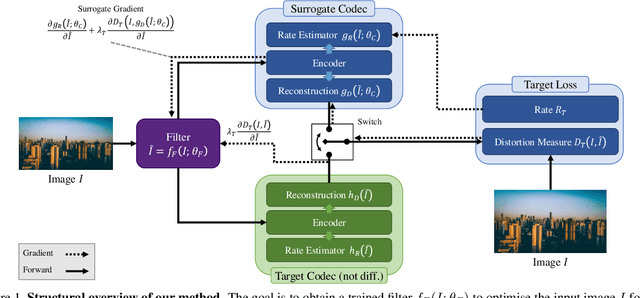
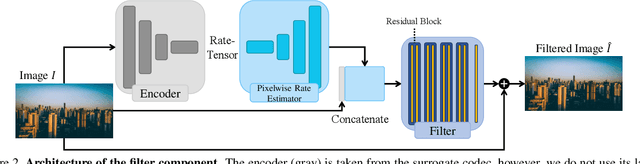

Lossy image compression is often limited by the simplicity of the chosen loss measure. Recent research suggests that generative adversarial networks have the ability to overcome this limitation and serve as a multi-modal loss, especially for textures. Together with learned image compression, these two techniques can be used to great effect when relaxing the commonly employed tight measures of distortion. However, convolutional neural network based algorithms have a large computational footprint. Ideally, an existing conventional codec should stay in place, which would ensure faster adoption and adhering to a balanced computational envelope. As a possible avenue to this goal, in this work, we propose and investigate how learned image coding can be used as a surrogate to optimize an image for encoding. The image is altered by a learned filter to optimise for a different performance measure or a particular task. Extending this idea with a generative adversarial network, we show how entire textures are replaced by ones that are less costly to encode but preserve sense of detail. Our approach can remodel a conventional codec to adjust for the MS-SSIM distortion with over 20% rate improvement without any decoding overhead. On task-aware image compression, we perform favourably against a similar but codec-specific approach.
Joint Pruning & Quantization for Extremely Sparse Neural Networks
Oct 05, 2020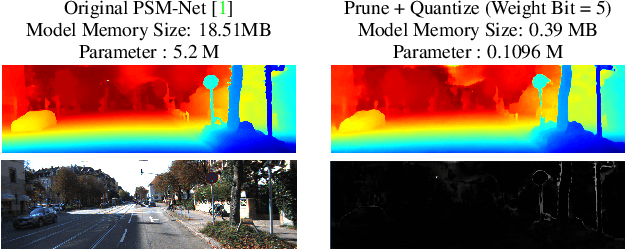
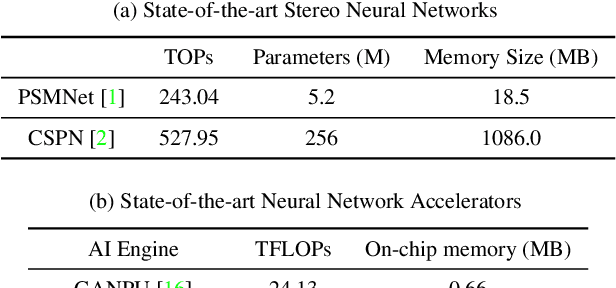
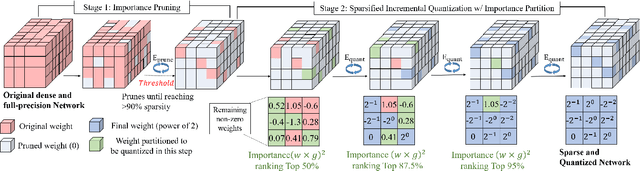
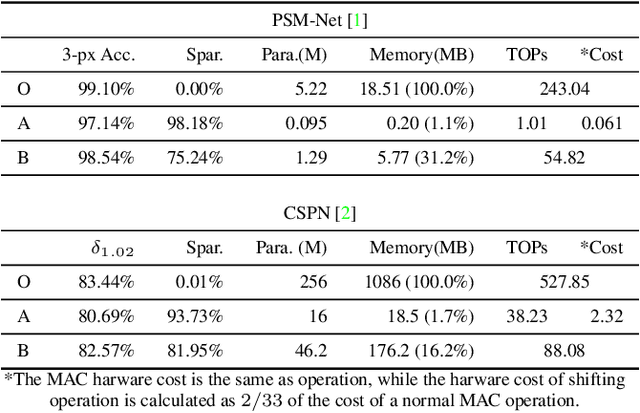
We investigate pruning and quantization for deep neural networks. Our goal is to achieve extremely high sparsity for quantized networks to enable implementation on low cost and low power accelerator hardware. In a practical scenario, there are particularly many applications for dense prediction tasks, hence we choose stereo depth estimation as target. We propose a two stage pruning and quantization pipeline and introduce a Taylor Score alongside a new fine-tuning mode to achieve extreme sparsity without sacrificing performance. Our evaluation does not only show that pruning and quantization should be investigated jointly, but also shows that almost 99% of memory demand can be cut while hardware costs can be reduced up to 99.9%. In addition, to compare with other works, we demonstrate that our pruning stage alone beats the state-of-the-art when applied to ResNet on CIFAR10 and ImageNet.
Utilising Low Complexity CNNs to Lift Non-Local Redundancies in Video Coding
Oct 19, 2019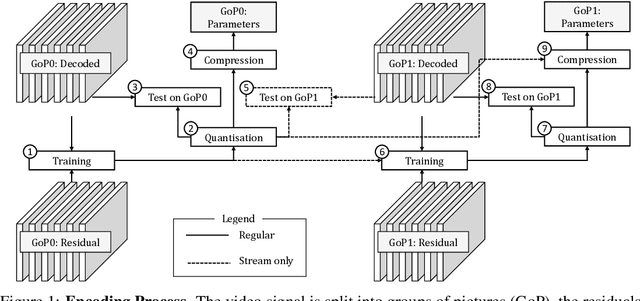


Digital media is ubiquitous and produced in ever-growing quantities. This necessitates a constant evolution of compression techniques, especially for video, in order to maintain efficient storage and transmission. In this work, we aim at exploiting non-local redundancies in video data that remain difficult to erase for conventional video codecs. We design convolutional neural networks with a particular emphasis on low memory and computational footprint. The parameters of those networks are trained on the fly, at encoding time, to predict the residual signal from the decoded video signal. After the training process has converged, the parameters are compressed and signalled as part of the code of the underlying video codec. The method can be applied to any existing video codec to increase coding gains while its low computational footprint allows for an application under resource-constrained conditions. Building on top of High Efficiency Video Coding, we achieve coding gains similar to those of pretrained denoising CNNs while only requiring about 1\% of their computational complexity. Through extensive experiments, we provide insights into the effectiveness of our network design decisions. In addition, we demonstrate that our algorithm delivers stable performance under conditions met in practical video compression: our algorithm performs without significant performance loss on very long random access segments (up to 256 frames) and with moderate performance drops can even be applied to single frames in high resolution low delay settings.
What Synthesis is Missing: Depth Adaptation Integrated with Weak Supervision for Indoor Scene Parsing
Mar 23, 2019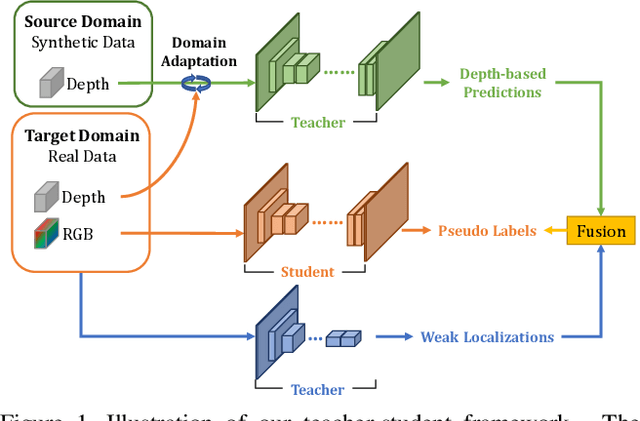

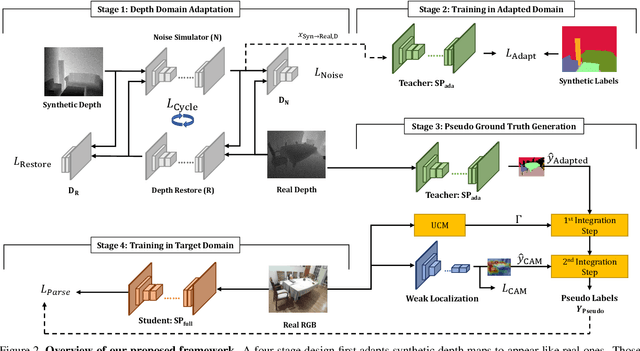
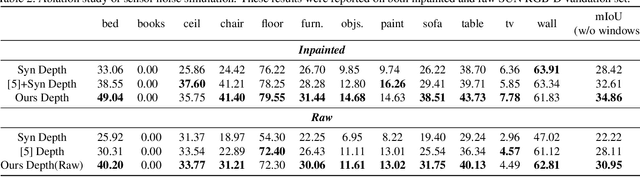
Scene Parsing is a crucial step to enable autonomous systems to understand and interact with their surroundings. Supervised deep learning methods have made great progress in solving scene parsing problems, however, come at the cost of laborious manual pixel-level annotation. To alleviate this effort synthetic data as well as weak supervision have both been investigated. Nonetheless, synthetically generated data still suffers from severe domain shift while weak labels are often imprecise. Moreover, most existing works for weakly supervised scene parsing are limited to salient foreground objects. The aim of this work is hence twofold: Exploit synthetic data where feasible and integrate weak supervision where necessary. More concretely, we address this goal by utilizing depth as transfer domain because its synthetic-to-real discrepancy is much lower than for color. At the same time, we perform weak localization from easily obtainable image level labels and integrate both using a novel contour-based scheme. Our approach is implemented as a teacher-student learning framework to solve the transfer learning problem by generating a pseudo ground truth. Using only depth-based adaptation, this approach already outperforms previous transfer learning approaches on the popular indoor scene parsing SUN RGB-D dataset. Our proposed two-stage integration more than halves the gap towards fully supervised methods when compared to previous state-of-the-art in transfer learning.