 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenKBP-Opt: An international and reproducible evaluation of 76 knowledge-based planning pipelines
Feb 16, 2022

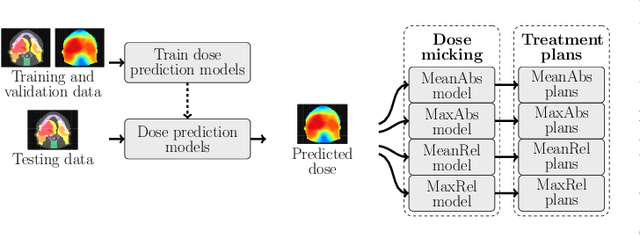
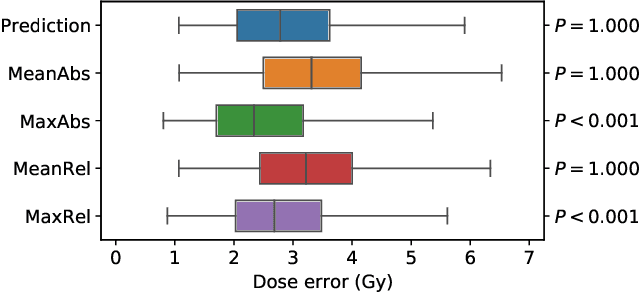
We establish an open framework for developing plan optimization models for knowledge-based planning (KBP) in radiotherapy. Our framework includes reference plans for 100 patients with head-and-neck cancer and high-quality dose predictions from 19 KBP models that were developed by different research groups during the OpenKBP Grand Challenge. The dose predictions were input to four optimization models to form 76 unique KBP pipelines that generated 7600 plans. The predictions and plans were compared to the reference plans via: dose score, which is the average mean absolute voxel-by-voxel difference in dose a model achieved; the deviation in dose-volume histogram (DVH) criterion; and the frequency of clinical planning criteria satisfaction. We also performed a theoretical investigation to justify our dose mimicking models. The range in rank order correlation of the dose score between predictions and their KBP pipelines was 0.50 to 0.62, which indicates that the quality of the predictions is generally positively correlated with the quality of the plans. Additionally, compared to the input predictions, the KBP-generated plans performed significantly better (P<0.05; one-sided Wilcoxon test) on 18 of 23 DVH criteria. Similarly, each optimization model generated plans that satisfied a higher percentage of criteria than the reference plans. Lastly, our theoretical investigation demonstrated that the dose mimicking models generated plans that are also optimal for a conventional planning model. This was the largest international effort to date for evaluating the combination of KBP prediction and optimization models. In the interest of reproducibility, our data and code is freely available at https://github.com/ababier/open-kbp-opt.
How to Exploit the Transferability of Learned Image Compression to Conventional Codecs
Dec 03, 2020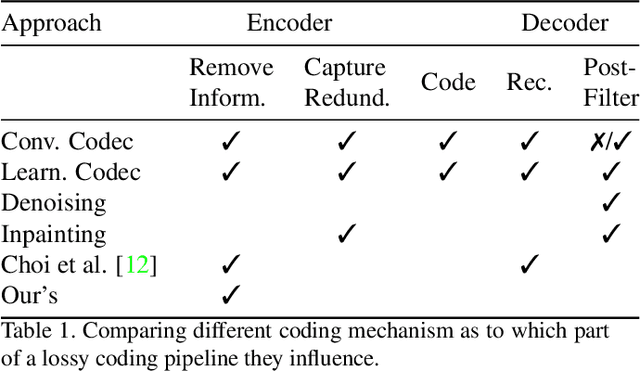
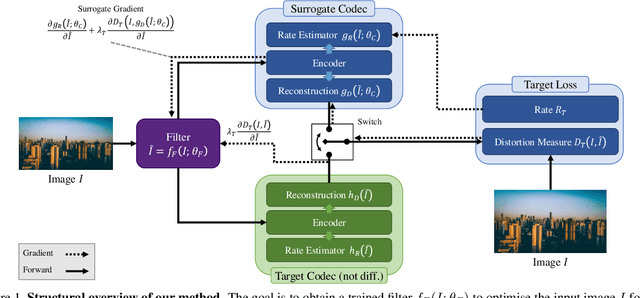
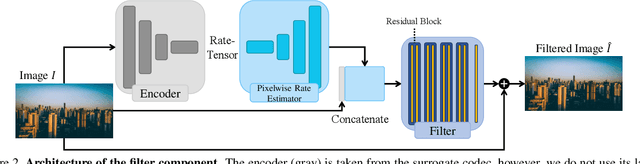

Lossy image compression is often limited by the simplicity of the chosen loss measure. Recent research suggests that generative adversarial networks have the ability to overcome this limitation and serve as a multi-modal loss, especially for textures. Together with learned image compression, these two techniques can be used to great effect when relaxing the commonly employed tight measures of distortion. However, convolutional neural network based algorithms have a large computational footprint. Ideally, an existing conventional codec should stay in place, which would ensure faster adoption and adhering to a balanced computational envelope. As a possible avenue to this goal, in this work, we propose and investigate how learned image coding can be used as a surrogate to optimize an image for encoding. The image is altered by a learned filter to optimise for a different performance measure or a particular task. Extending this idea with a generative adversarial network, we show how entire textures are replaced by ones that are less costly to encode but preserve sense of detail. Our approach can remodel a conventional codec to adjust for the MS-SSIM distortion with over 20% rate improvement without any decoding overhead. On task-aware image compression, we perform favourably against a similar but codec-specific approach.
Self-similarity Student for Partial Label Histopathology Image Segmentation
Jul 19, 2020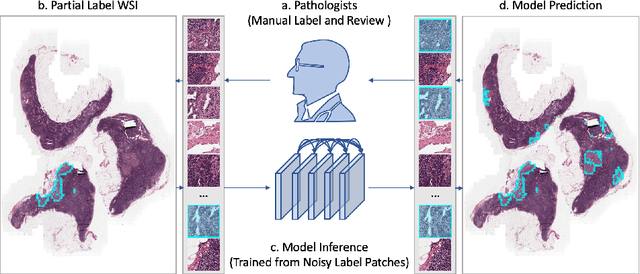
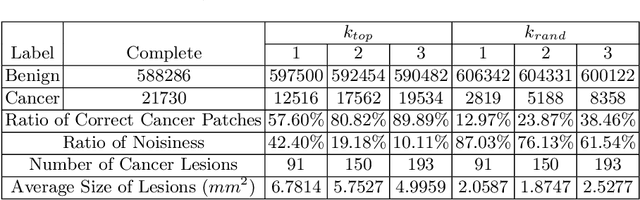
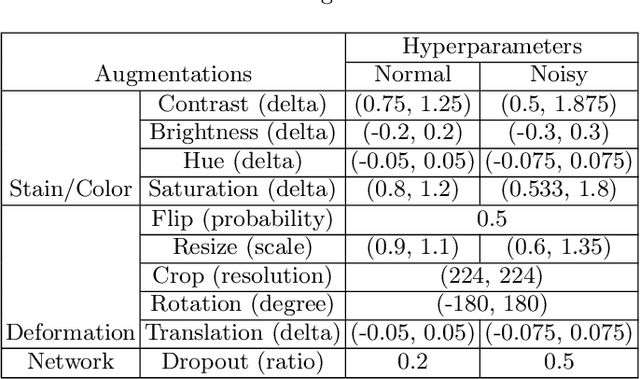
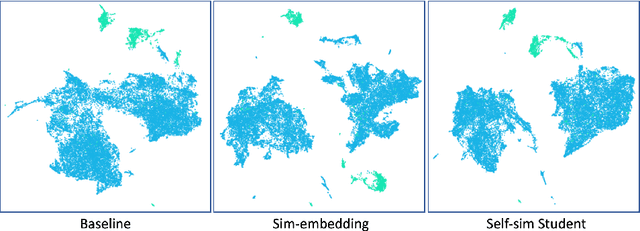
Delineation of cancerous regions in gigapixel whole slide images (WSIs) is a crucial diagnostic procedure in digital pathology. This process is time-consuming because of the large search space in the gigapixel WSIs, causing chances of omission and misinterpretation at indistinct tumor lesions. To tackle this, the development of an automated cancerous region segmentation method is imperative. We frame this issue as a modeling problem with partial label WSIs, where some cancerous regions may be misclassified as benign and vice versa, producing patches with noisy labels. To learn from these patches, we propose Self-similarity Student, combining teacher-student model paradigm with similarity learning. Specifically, for each patch, we first sample its similar and dissimilar patches according to spatial distance. A teacher-student model is then introduced, featuring the exponential moving average on both student model weights and teacher predictions ensemble. While our student model takes patches, teacher model takes all their corresponding similar and dissimilar patches for learning robust representation against noisy label patches. Following this similarity learning, our similarity ensemble merges similar patches' ensembled predictions as the pseudo-label of a given patch to counteract its noisy label. On the CAMELYON16 dataset, our method substantially outperforms state-of-the-art noise-aware learning methods by 5$\%$ and the supervised-trained baseline by 10$\%$ in various degrees of noise. Moreover, our method is superior to the baseline on our TVGH TURP dataset with 2$\%$ improvement, demonstrating the generalizability to more clinical histopathology segmentation tasks.
A Cascaded Learning Strategy for Robust COVID-19 Pneumonia Chest X-Ray Screening
Apr 30, 2020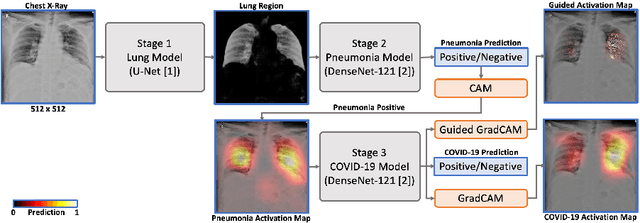
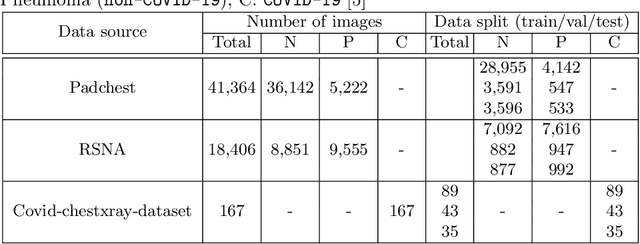
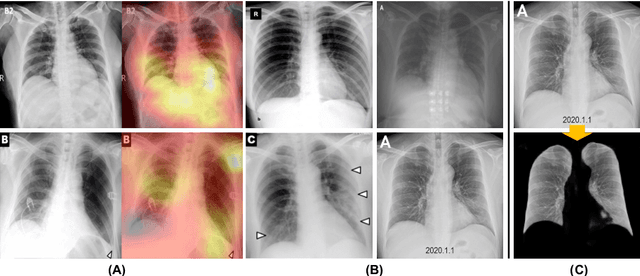
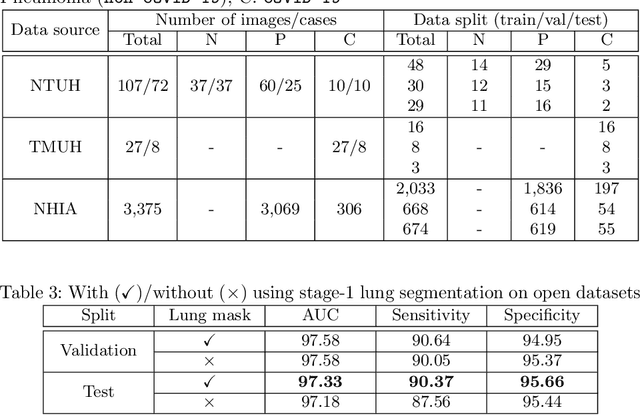
We introduce a comprehensive screening platform for the COVID-19 (a.k.a., SARS-CoV-2) pneumonia. The proposed AI-based system works on chest x-ray (CXR) images to predict whether a patient is infected with the COVID-19 disease. Although the recent international joint effort on making the availability of all sorts of open data, the public collection of CXR images is still relatively small for reliably training a deep neural network (DNN) to carry out COVID-19 prediction. To better address such inefficiency, we design a cascaded learning strategy to improve both the sensitivity and the specificity of the resulting DNN classification model. Our approach leverages a large CXR image dataset of non-COVID-19 pneumonia to generalize the original well-trained classification model via a cascaded learning scheme. The resulting screening system is shown to achieve good classification performance on the expanded dataset, including those newly added COVID-19 CXR images.
What Synthesis is Missing: Depth Adaptation Integrated with Weak Supervision for Indoor Scene Parsing
Mar 23, 2019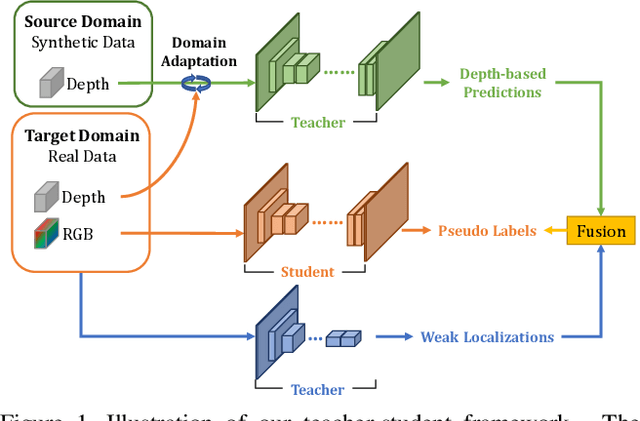

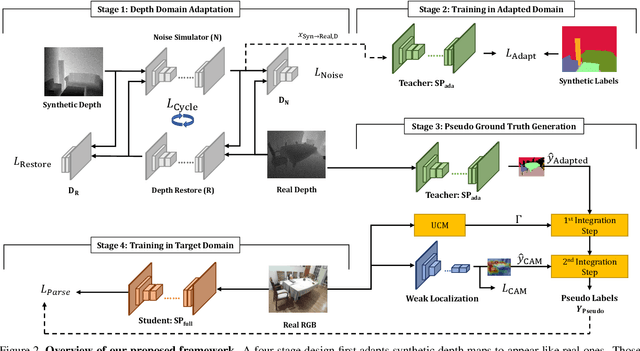
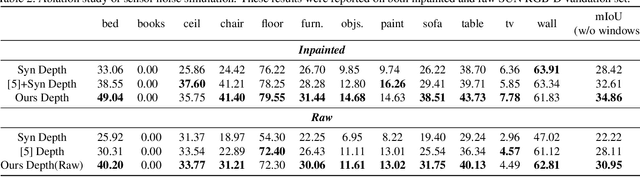
Scene Parsing is a crucial step to enable autonomous systems to understand and interact with their surroundings. Supervised deep learning methods have made great progress in solving scene parsing problems, however, come at the cost of laborious manual pixel-level annotation. To alleviate this effort synthetic data as well as weak supervision have both been investigated. Nonetheless, synthetically generated data still suffers from severe domain shift while weak labels are often imprecise. Moreover, most existing works for weakly supervised scene parsing are limited to salient foreground objects. The aim of this work is hence twofold: Exploit synthetic data where feasible and integrate weak supervision where necessary. More concretely, we address this goal by utilizing depth as transfer domain because its synthetic-to-real discrepancy is much lower than for color. At the same time, we perform weak localization from easily obtainable image level labels and integrate both using a novel contour-based scheme. Our approach is implemented as a teacher-student learning framework to solve the transfer learning problem by generating a pseudo ground truth. Using only depth-based adaptation, this approach already outperforms previous transfer learning approaches on the popular indoor scene parsing SUN RGB-D dataset. Our proposed two-stage integration more than halves the gap towards fully supervised methods when compared to previous state-of-the-art in transfer learning.