 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling-Aware Data Selection for End-to-End Autonomous Driving Systems
Apr 09, 2026Large-scale deep learning models for physical AI applications depend on diverse training data collection efforts. These models and correspondingly, the training data, must address different evaluation criteria necessary for the models to be deployable in real-world environments. Data selection policies can guide the development of the training set, but current frameworks do not account for the ambiguity in how data points affect different metrics. In this work, we propose Mixture Optimization via Scaling-Aware Iterative Collection (MOSAIC), a general data selection framework that operates by: (i) partitioning the dataset into domains; (ii) fitting neural scaling laws from each data domain to the evaluation metrics; and (iii) optimizing a data mixture by iteratively adding data from domains that maximize the change in metrics. We apply MOSAIC to autonomous driving (AD), where an End-to-End (E2E) planner model is evaluated on the Extended Predictive Driver Model Score (EPDMS), an aggregate of driving rule compliance metrics. Here, MOSAIC outperforms a diverse set of baselines on EPDMS with up to 80\% less data.
Routing, Cascades, and User Choice for LLMs
Feb 10, 2026To mitigate the trade-offs between performance and costs, LLM providers route user tasks to different models based on task difficulty and latency. We study the effect of LLM routing with respect to user behavior. We propose a game between an LLM provider with two models (standard and reasoning) and a user who can re-prompt or abandon tasks if the routed model cannot solve them. The user's goal is to maximize their utility minus the delay from using the model, while the provider minimizes the cost of servicing the user. We solve this Stackelberg game by fully characterizing the user best response and simplifying the provider problem. We observe that in nearly all cases, the optimal routing policy involves a static policy with no cascading that depends on the expected utility of the models to the user. Furthermore, we reveal a misalignment gap between the provider-optimal and user-preferred routes when the user's and provider's rankings of the models with respect to utility and cost differ. Finally, we demonstrate conditions for extreme misalignment where providers are incentivized to throttle the latency of the models to minimize their costs, consequently depressing user utility. The results yield simple threshold rules for single-provider, single-user interactions and clarify when routing, cascading, and throttling help or harm.
Minority Reports: Balancing Cost and Quality in Ground Truth Data Annotation
Apr 12, 2025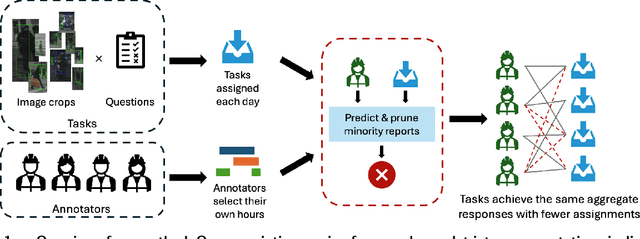
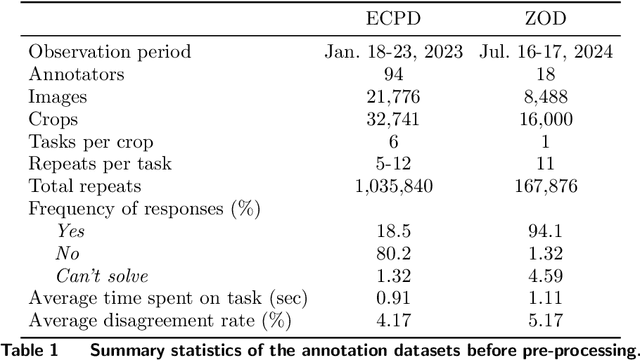

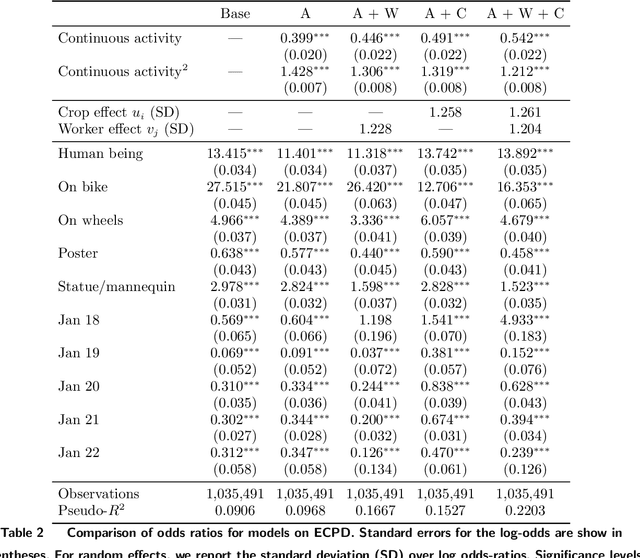
High-quality data annotation is an essential but laborious and costly aspect of developing machine learning-based software. We explore the inherent tradeoff between annotation accuracy and cost by detecting and removing minority reports -- instances where annotators provide incorrect responses -- that indicate unnecessary redundancy in task assignments. We propose an approach to prune potentially redundant annotation task assignments before they are executed by estimating the likelihood of an annotator disagreeing with the majority vote for a given task. Our approach is informed by an empirical analysis over computer vision datasets annotated by a professional data annotation platform, which reveals that the likelihood of a minority report event is dependent primarily on image ambiguity, worker variability, and worker fatigue. Simulations over these datasets show that we can reduce the number of annotations required by over 60% with a small compromise in label quality, saving approximately 6.6 days-equivalent of labor. Our approach provides annotation service platforms with a method to balance cost and dataset quality. Machine learning practitioners can tailor annotation accuracy levels according to specific application needs, thereby optimizing budget allocation while maintaining the data quality necessary for critical settings like autonomous driving technology.
Pricing and Competition for Generative AI
Nov 04, 2024


Compared to classical machine learning (ML) models, generative models offer a new usage paradigm where (i) a single model can be used for many different tasks out-of-the-box; (ii) users interact with this model over a series of natural language prompts; and (iii) the model is ideally evaluated on binary user satisfaction with respect to model outputs. Given these characteristics, we explore the problem of how developers of new generative AI software can release and price their technology. We first develop a comparison of two different models for a specific task with respect to user cost-effectiveness. We then model the pricing problem of generative AI software as a game between two different companies who sequentially release their models before users choose their preferred model for each task. Here, the price optimization problem becomes piecewise continuous where the companies must choose a subset of the tasks on which to be cost-effective and forgo revenue for the remaining tasks. In particular, we reveal the value of market information by showing that a company who deploys later after knowing their competitor's price can always secure cost-effectiveness on at least one task, whereas the company who is the first-to-market must price their model in a way that incentivizes higher prices from the latecomer in order to gain revenue. Most importantly, we find that if the different tasks are sufficiently similar, the first-to-market model may become cost-ineffective on all tasks regardless of how this technology is priced.
Uncertainty Estimation for 3D Object Detection via Evidential Learning
Oct 31, 2024



3D object detection is an essential task for computer vision applications in autonomous vehicles and robotics. However, models often struggle to quantify detection reliability, leading to poor performance on unfamiliar scenes. We introduce a framework for quantifying uncertainty in 3D object detection by leveraging an evidential learning loss on Bird's Eye View representations in the 3D detector. These uncertainty estimates require minimal computational overhead and are generalizable across different architectures. We demonstrate both the efficacy and importance of these uncertainty estimates on identifying out-of-distribution scenes, poorly localized objects, and missing (false negative) detections; our framework consistently improves over baselines by 10-20% on average. Finally, we integrate this suite of tasks into a system where a 3D object detector auto-labels driving scenes and our uncertainty estimates verify label correctness before the labels are used to train a second model. Here, our uncertainty-driven verification results in a 1% improvement in mAP and a 1-2% improvement in NDS.
Reasoning Paths with Reference Objects Elicit Quantitative Spatial Reasoning in Large Vision-Language Models
Sep 15, 2024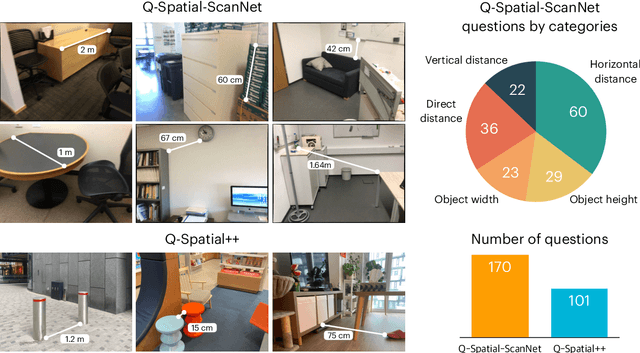
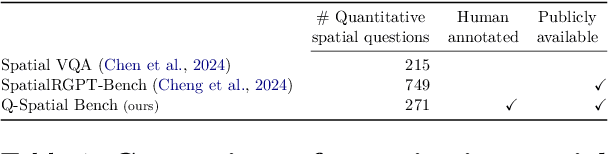
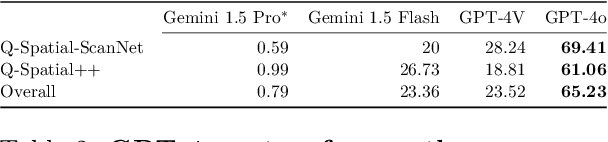

Despite recent advances demonstrating vision-language models' (VLMs) abilities to describe complex relationships in images using natural language, their capability to quantitatively reason about object sizes and distances remains underexplored. In this work, we introduce a manually annotated benchmark, Q-Spatial Bench, with 271 questions across five categories designed for quantitative spatial reasoning and systematically investigate the performance of state-of-the-art VLMs on this task. Our analysis reveals that reasoning about distances between objects is particularly challenging for SoTA VLMs; however, some VLMs significantly outperform others, with an over 40-point gap between the two best performing models. We also make the surprising observation that the success rate of the top-performing VLM increases by 19 points when a reasoning path using a reference object emerges naturally in the response. Inspired by this observation, we develop a zero-shot prompting technique, SpatialPrompt, that encourages VLMs to answer quantitative spatial questions using reference objects as visual cues. By instructing VLMs to use reference objects in their reasoning paths via SpatialPrompt, Gemini 1.5 Pro, Gemini 1.5 Flash, and GPT-4V improve their success rates by over 40, 20, and 30 points, respectively. We emphasize that these significant improvements are obtained without needing more data, model architectural modifications, or fine-tuning.
AutoScale: Automatic Prediction of Compute-optimal Data Composition for Training LLMs
Jul 29, 2024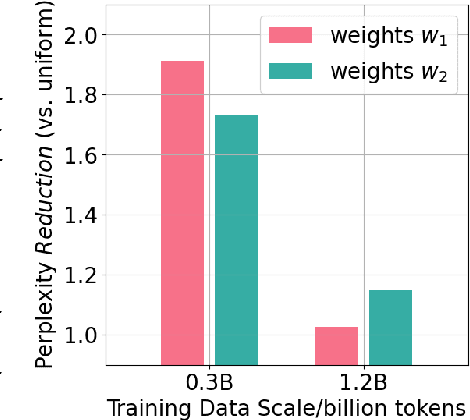
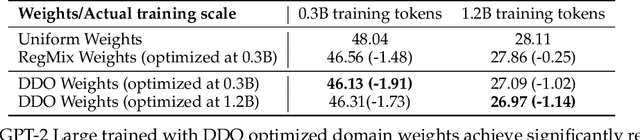
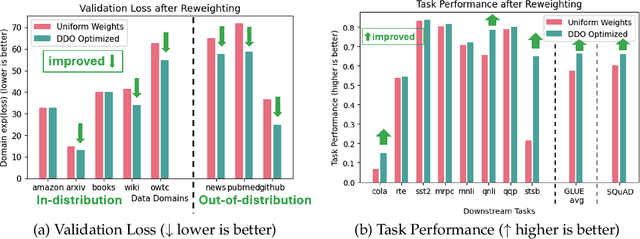
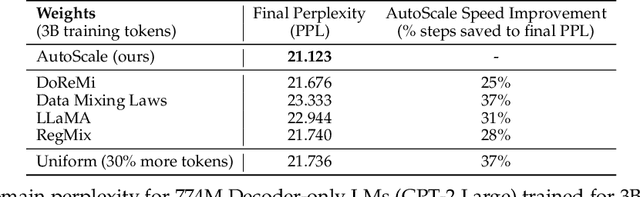
To ensure performance on a diverse set of downstream tasks, LLMs are pretrained via data mixtures over different domains. In this work, we demonstrate that the optimal data composition for a fixed compute budget varies depending on the scale of the training data, suggesting that the common practice of empirically determining an optimal composition using small-scale experiments will not yield the optimal data mixtures when scaling up to the final model. To address this challenge, we propose *AutoScale*, an automated tool that finds a compute-optimal data composition for training at any desired target scale. AutoScale first determines the optimal composition at a small scale using a novel bilevel optimization framework, Direct Data Optimization (*DDO*), and then fits a predictor to estimate the optimal composition at larger scales. The predictor's design is inspired by our theoretical analysis of scaling laws related to data composition, which could be of independent interest. In empirical studies with pre-training 774M Decoder-only LMs (GPT-2 Large) on RedPajama dataset, AutoScale decreases validation perplexity at least 25% faster than any baseline with up to 38% speed up compared to without reweighting, achieving the best overall performance across downstream tasks. On pre-training Encoder-only LMs (BERT) with masked language modeling, DDO is shown to decrease loss on all domains while visibly improving average task performance on GLUE benchmark by 8.7% and on large-scale QA dataset (SQuAD) by 5.9% compared with without reweighting. AutoScale speeds up training by up to 28%. Our codes are open-sourced.
Can Feedback Enhance Semantic Grounding in Large Vision-Language Models?
Apr 09, 2024Enhancing semantic grounding abilities in Vision-Language Models (VLMs) often involves collecting domain-specific training data, refining the network architectures, or modifying the training recipes. In this work, we venture into an orthogonal direction and explore whether VLMs can improve their semantic grounding by "receiving" feedback, without requiring in-domain data, fine-tuning, or modifications to the network architectures. We systematically analyze this hypothesis using a feedback mechanism composed of a binary signal. We find that if prompted appropriately, VLMs can utilize feedback both in a single step and iteratively, showcasing the potential of feedback as an alternative technique to improve grounding in internet-scale VLMs. Furthermore, VLMs, like LLMs, struggle to self-correct errors out-of-the-box. However, we find that this issue can be mitigated via a binary verification mechanism. Finally, we explore the potential and limitations of amalgamating these findings and applying them iteratively to automatically enhance VLMs' grounding performance, showing grounding accuracy consistently improves using automated feedback across all models in all settings investigated. Overall, our iterative framework improves semantic grounding in VLMs by more than 15 accuracy points under noise-free feedback and up to 5 accuracy points under a simple automated binary verification mechanism. The project website is hosted at https://andrewliao11.github.io/vlms_feedback
Bridging the Sim2Real gap with CARE: Supervised Detection Adaptation with Conditional Alignment and Reweighting
Feb 09, 2023



Sim2Real domain adaptation (DA) research focuses on the constrained setting of adapting from a labeled synthetic source domain to an unlabeled or sparsely labeled real target domain. However, for high-stakes applications (e.g. autonomous driving), it is common to have a modest amount of human-labeled real data in addition to plentiful auto-labeled source data (e.g. from a driving simulator). We study this setting of supervised sim2real DA applied to 2D object detection. We propose Domain Translation via Conditional Alignment and Reweighting (CARE) a novel algorithm that systematically exploits target labels to explicitly close the sim2real appearance and content gaps. We present an analytical justification of our algorithm and demonstrate strong gains over competing methods on standard benchmarks.
Optimizing Data Collection for Machine Learning
Oct 03, 2022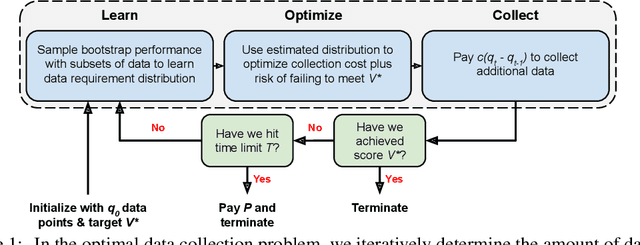
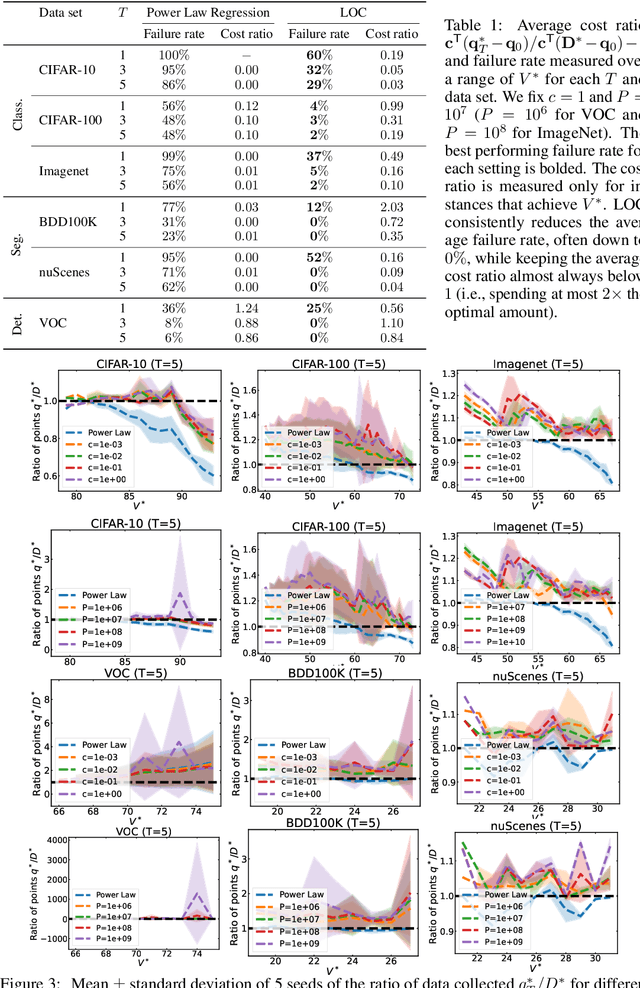
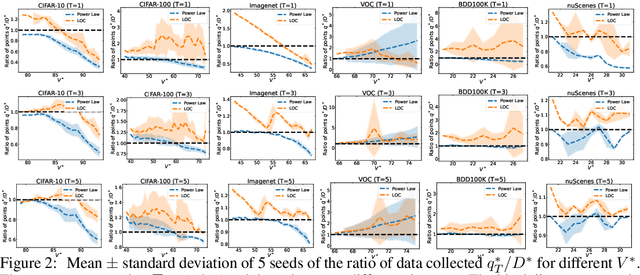
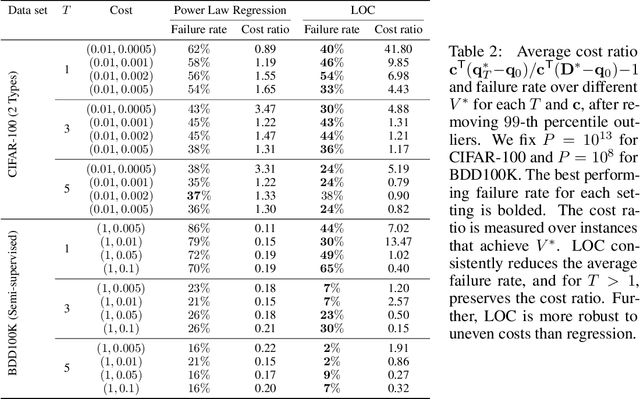
Modern deep learning systems require huge data sets to achieve impressive performance, but there is little guidance on how much or what kind of data to collect. Over-collecting data incurs unnecessary present costs, while under-collecting may incur future costs and delay workflows. We propose a new paradigm for modeling the data collection workflow as a formal optimal data collection problem that allows designers to specify performance targets, collection costs, a time horizon, and penalties for failing to meet the targets. Additionally, this formulation generalizes to tasks requiring multiple data sources, such as labeled and unlabeled data used in semi-supervised learning. To solve our problem, we develop Learn-Optimize-Collect (LOC), which minimizes expected future collection costs. Finally, we numerically compare our framework to the conventional baseline of estimating data requirements by extrapolating from neural scaling laws. We significantly reduce the risks of failing to meet desired performance targets on several classification, segmentation, and detection tasks, while maintaining low total collection costs.