 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Label Spreading: Efficient and Consistent Estimation of Soft Labels with Epistemic Uncertainty on Graphs
Feb 04, 2026Safe artificial intelligence for perception tasks remains a major challenge, partly due to the lack of data with high-quality labels. Annotations themselves are subject to aleatoric and epistemic uncertainty, which is typically ignored during annotation and evaluation. While crowdsourcing enables collecting multiple annotations per image to estimate these uncertainties, this approach is impractical at scale due to the required annotation effort. We introduce a probabilistic label spreading method that provides reliable estimates of aleatoric and epistemic uncertainty of labels. Assuming label smoothness over the feature space, we propagate single annotations using a graph-based diffusion method. We prove that label spreading yields consistent probability estimators even when the number of annotations per data point converges to zero. We present and analyze a scalable implementation of our method. Experimental results indicate that, compared to baselines, our approach substantially reduces the annotation budget required to achieve a desired label quality on common image datasets and achieves a new state of the art on the Data-Centric Image Classification benchmark.
Quantifying Ambiguity in Categorical Annotations: A Measure and Statistical Inference Framework
Oct 05, 2025Human-generated categorical annotations frequently produce empirical response distributions (soft labels) that reflect ambiguity rather than simple annotator error. We introduce an ambiguity measure that maps a discrete response distribution to a scalar in the unit interval, designed to quantify aleatoric uncertainty in categorical tasks. The measure bears a close relationship to quadratic entropy (Gini-style impurity) but departs from those indices by treating an explicit "can't solve" category asymmetrically, thereby separating uncertainty arising from class-level indistinguishability from uncertainty due to explicit unresolvability. We analyze the measure's formal properties and contrast its behavior with a representative ambiguity measure from the literature. Moving beyond description, we develop statistical tools for inference: we propose frequentist point estimators for population ambiguity and derive the Bayesian posterior over ambiguity induced by Dirichlet priors on the underlying probability vector, providing a principled account of epistemic uncertainty. Numerical examples illustrate estimation, calibration, and practical use for dataset-quality assessment and downstream machine-learning workflows.
Minority Reports: Balancing Cost and Quality in Ground Truth Data Annotation
Apr 12, 2025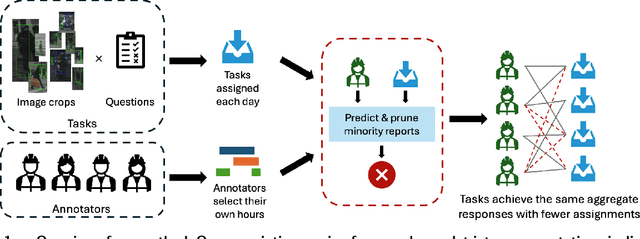
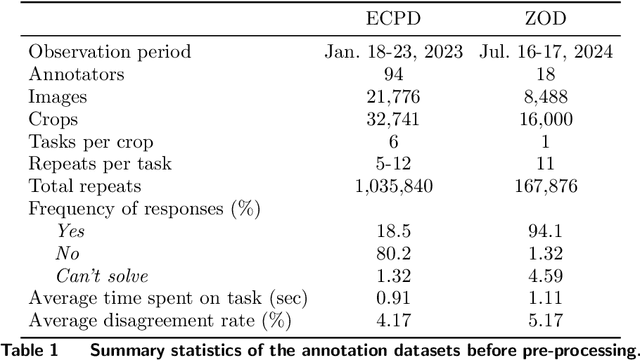

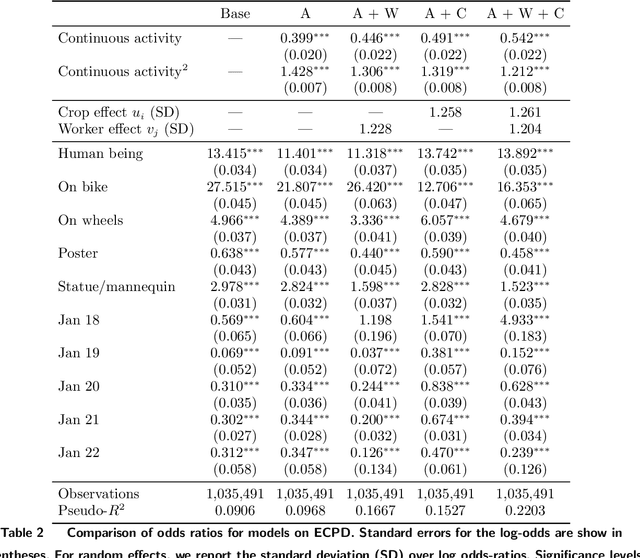
High-quality data annotation is an essential but laborious and costly aspect of developing machine learning-based software. We explore the inherent tradeoff between annotation accuracy and cost by detecting and removing minority reports -- instances where annotators provide incorrect responses -- that indicate unnecessary redundancy in task assignments. We propose an approach to prune potentially redundant annotation task assignments before they are executed by estimating the likelihood of an annotator disagreeing with the majority vote for a given task. Our approach is informed by an empirical analysis over computer vision datasets annotated by a professional data annotation platform, which reveals that the likelihood of a minority report event is dependent primarily on image ambiguity, worker variability, and worker fatigue. Simulations over these datasets show that we can reduce the number of annotations required by over 60% with a small compromise in label quality, saving approximately 6.6 days-equivalent of labor. Our approach provides annotation service platforms with a method to balance cost and dataset quality. Machine learning practitioners can tailor annotation accuracy levels according to specific application needs, thereby optimizing budget allocation while maintaining the data quality necessary for critical settings like autonomous driving technology.
Ambiguous Annotations: When is a Pedestrian not a Pedestrian?
May 14, 2024Datasets labelled by human annotators are widely used in the training and testing of machine learning models. In recent years, researchers are increasingly paying attention to label quality. However, it is not always possible to objectively determine whether an assigned label is correct or not. The present work investigates this ambiguity in the annotation of autonomous driving datasets as an important dimension of data quality. Our experiments show that excluding highly ambiguous data from the training improves model performance of a state-of-the-art pedestrian detector in terms of LAMR, precision and F1 score, thereby saving training time and annotation costs. Furthermore, we demonstrate that, in order to safely remove ambiguous instances and ensure the retained representativeness of the training data, an understanding of the properties of the dataset and class under investigation is crucial.
What, when, and where? -- Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions
Mar 29, 2023Spatio-temporal grounding describes the task of localizing events in space and time, e.g., in video data, based on verbal descriptions only. Models for this task are usually trained with human-annotated sentences and bounding box supervision. This work addresses this task from a multimodal supervision perspective, proposing a framework for spatio-temporal action grounding trained on loose video and subtitle supervision only, without human annotation. To this end, we combine local representation learning, which focuses on leveraging fine-grained spatial information, with a global representation encoding that captures higher-level representations and incorporates both in a joint approach. To evaluate this challenging task in a real-life setting, a new benchmark dataset is proposed providing dense spatio-temporal grounding annotations in long, untrimmed, multi-action instructional videos for over 5K events. We evaluate the proposed approach and other methods on the proposed and standard downstream tasks showing that our method improves over current baselines in various settings, including spatial, temporal, and untrimmed multi-action spatio-temporal grounding.