 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTA-Vid: Generalized Test-Time Adaptation for Video Reasoning
Apr 01, 2026Recent video reasoning models have shown strong results on temporal and multimodal understanding, yet they depend on large-scale supervised data and multi-stage training pipelines, making them costly to train and difficult to adapt to new domains. In this work, we leverage the paradigm of Test-Time Reinforcement Learning on video-language data to allow for adapting a pretrained model to incoming video samples at test-time without explicit labels. The proposed test-time adaptation for video approach (TTA-Vid) combines two components that work simultaneously: (1) a test-time adaptation that performs step-by-step reasoning at inference time on multiple frame subsets. We then use a batch-aware frequency-based reward computed across different frame subsets as pseudo ground truth to update the model. It shows that the resulting model trained on a single batch or even a single sample from a dataset, is able to generalize at test-time to the whole dataset and even across datasets. Because the adaptation occurs entirely at test time, our method requires no ground-truth annotations or dedicated training splits. Additionally, we propose a multi-armed bandit strategy for adaptive frame selection that learns to prioritize informative frames, guided by the same reward formulation. Our evaluation shows that TTA-Vid yields consistent improvements across various video reasoning tasks and is able to outperform current state-of-the-art methods trained on large-scale data. This highlights the potential of test-time reinforcement learning for temporal multimodal understanding.
Self-Speculative Decoding for LLM-based ASR with CTC Encoder Drafts
Mar 11, 2026We propose self-speculative decoding for speech-aware LLMs by using the CTC encoder as a draft model to accelerate auto-regressive (AR) inference and improve ASR accuracy. Our three-step procedure works as follows: (1) if the frame entropies of the CTC output distributions are below a threshold, the greedy CTC hypothesis is accepted as final; (2) otherwise, the CTC hypothesis is verified in a single LLM forward pass using a relaxed acceptance criterion based on token likelihoods; (3) if verification fails, AR decoding resumes from the accepted CTC prefix. Experiments on nine corpora and five languages show that this approach can simultaneously accelerate decoding and reduce WER. On the HuggingFace Open ASR benchmark with a 1B parameter LLM and 440M parameter CTC encoder, we achieve a record 5.58% WER and improve the inverse real time factor by a factor of 4.4 with only a 12% relative WER increase over AR search. Code and model weights are publicly available under a permissive license.
NLE: Non-autoregressive LLM-based ASR by Transcript Editing
Mar 09, 2026While autoregressive (AR) LLM-based ASR systems achieve strong accuracy, their sequential decoding limits parallelism and incurs high latency. We propose NLE, a non-autoregressive (NAR) approach that formulates speech recognition as conditional transcript editing, enabling fully parallel prediction. NLE extracts acoustic embeddings and an initial hypothesis from a pretrained speech encoder, then refines the hypothesis using a bidirectional LLM editor trained with a latent alignment objective. An interleaved padding strategy exploits the identity mapping bias of Transformers, allowing the model to focus on corrections rather than full reconstruction. On the Open ASR leaderboard, NLE++ achieves 5.67% average WER with an RTFx (inverse real-time factor) of 1630. In single-utterance scenarios, NLE achieves 27x speedup over the AR baseline, making it suitable for real-time applications.
Omni-R1: Do You Really Need Audio to Fine-Tune Your Audio LLM?
May 14, 2025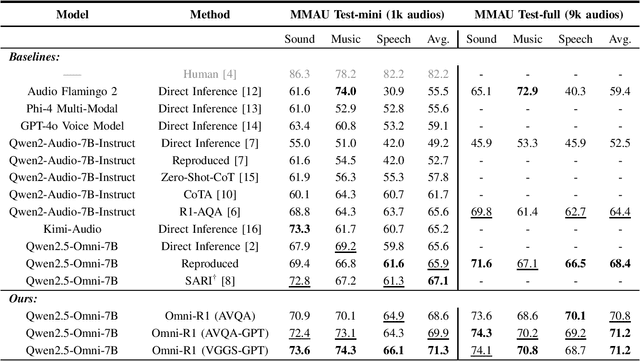
We propose Omni-R1 which fine-tunes a recent multi-modal LLM, Qwen2.5-Omni, on an audio question answering dataset with the reinforcement learning method GRPO. This leads to new State-of-the-Art performance on the recent MMAU benchmark. Omni-R1 achieves the highest accuracies on the sounds, music, speech, and overall average categories, both on the Test-mini and Test-full splits. To understand the performance improvement, we tested models both with and without audio and found that much of the performance improvement from GRPO could be attributed to better text-based reasoning. We also made a surprising discovery that fine-tuning without audio on a text-only dataset was effective at improving the audio-based performance.
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
CAV-MAE Sync: Improving Contrastive Audio-Visual Mask Autoencoders via Fine-Grained Alignment
May 02, 2025Recent advances in audio-visual learning have shown promising results in learning representations across modalities. However, most approaches rely on global audio representations that fail to capture fine-grained temporal correspondences with visual frames. Additionally, existing methods often struggle with conflicting optimization objectives when trying to jointly learn reconstruction and cross-modal alignment. In this work, we propose CAV-MAE Sync as a simple yet effective extension of the original CAV-MAE framework for self-supervised audio-visual learning. We address three key challenges: First, we tackle the granularity mismatch between modalities by treating audio as a temporal sequence aligned with video frames, rather than using global representations. Second, we resolve conflicting optimization goals by separating contrastive and reconstruction objectives through dedicated global tokens. Third, we improve spatial localization by introducing learnable register tokens that reduce semantic load on patch tokens. We evaluate the proposed approach on AudioSet, VGG Sound, and the ADE20K Sound dataset on zero-shot retrieval, classification and localization tasks demonstrating state-of-the-art performance and outperforming more complex architectures.
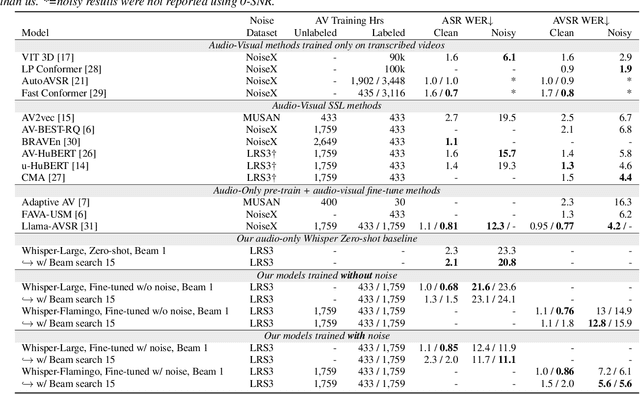
mWhisper-Flamingo for Multilingual Audio-Visual Noise-Robust Speech Recognition
Feb 03, 2025Audio-Visual Speech Recognition (AVSR) combines lip-based video with audio and can improve performance in noise, but most methods are trained only on English data. One limitation is the lack of large-scale multilingual video data, which makes it hard hard to train models from scratch. In this work, we propose mWhisper-Flamingo for multilingual AVSR which combines the strengths of a pre-trained audio model (Whisper) and video model (AV-HuBERT). To enable better multi-modal integration and improve the noisy multilingual performance, we introduce decoder modality dropout where the model is trained both on paired audio-visual inputs and separate audio/visual inputs. mWhisper-Flamingo achieves state-of-the-art WER on MuAViC, an AVSR dataset of 9 languages. Audio-visual mWhisper-Flamingo consistently outperforms audio-only Whisper on all languages in noisy conditions.
A Non-autoregressive Model for Joint STT and TTS
Jan 15, 2025In this paper, we take a step towards jointly modeling automatic speech recognition (STT) and speech synthesis (TTS) in a fully non-autoregressive way. We develop a novel multimodal framework capable of handling the speech and text modalities as input either individually or together. The proposed model can also be trained with unpaired speech or text data owing to its multimodal nature. We further propose an iterative refinement strategy to improve the STT and TTS performance of our model such that the partial hypothesis at the output can be fed back to the input of our model, thus iteratively improving both STT and TTS predictions. We show that our joint model can effectively perform both STT and TTS tasks, outperforming the STT-specific baseline in all tasks and performing competitively with the TTS-specific baseline across a wide range of evaluation metrics.
Whisper-Flamingo: Integrating Visual Features into Whisper for Audio-Visual Speech Recognition and Translation
Jun 14, 2024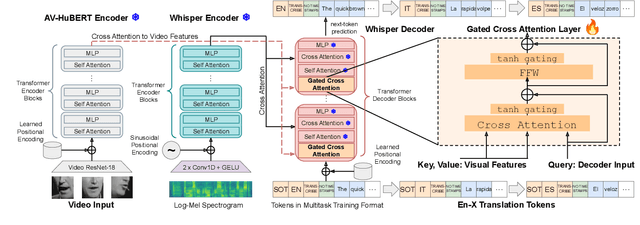
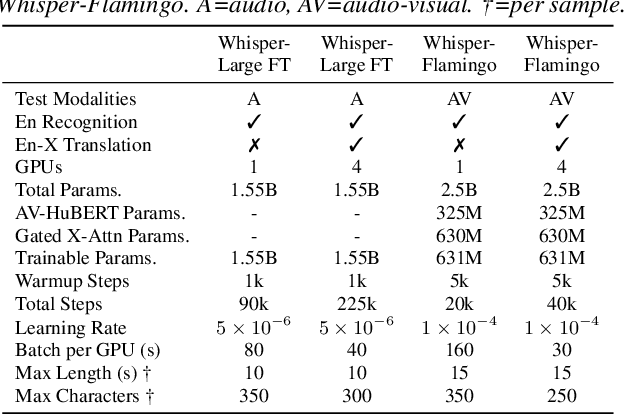
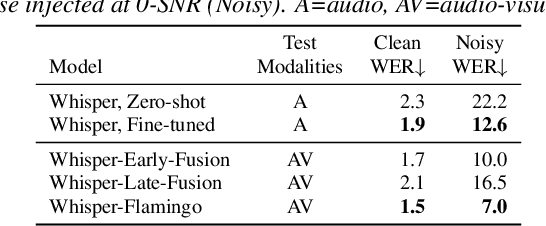
Audio-Visual Speech Recognition (AVSR) uses lip-based video to improve performance in noise. Since videos are harder to obtain than audio, the video training data of AVSR models is usually limited to a few thousand hours. In contrast, speech models such as Whisper are trained with hundreds of thousands of hours of data, and thus learn a better speech-to-text decoder. The huge training data difference motivates us to adapt Whisper to handle video inputs. Inspired by Flamingo which injects visual features into language models, we propose Whisper-Flamingo which integrates visual features into the Whisper speech recognition and translation model with gated cross attention. Our audio-visual Whisper-Flamingo outperforms audio-only Whisper on English speech recognition and En-X translation for 6 languages in noisy conditions. Moreover, Whisper-Flamingo is a versatile model and conducts all of these tasks using one set of parameters, while prior methods are trained separately on each language.
Comparison of Multilingual Self-Supervised and Weakly-Supervised Speech Pre-Training for Adaptation to Unseen Languages
May 21, 2023



Recent models such as XLS-R and Whisper have made multilingual speech technologies more accessible by pre-training on audio from around 100 spoken languages each. However, there are thousands of spoken languages worldwide, and adapting to new languages is an important problem. In this work, we aim to understand which model adapts better to languages unseen during pre-training. We fine-tune both models on 13 unseen languages and 18 seen languages. Our results show that the number of hours seen per language and language family during pre-training is predictive of how the models compare, despite the significant differences in the pre-training methods.