 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized RVQ-GAN For Disentangled Speech Tokenization
Jun 18, 2025We propose Hierarchical Audio Codec (HAC), a unified neural speech codec that factorizes its bottleneck into three linguistic levels-acoustic, phonetic, and lexical-within a single model. HAC leverages two knowledge distillation objectives: one from a pre-trained speech encoder (HuBERT) for phoneme-level structure, and another from a text-based encoder (LaBSE) for lexical cues. Experiments on English and multilingual data show that HAC's factorized bottleneck yields disentangled token sets: one aligns with phonemes, while another captures word-level semantics. Quantitative evaluations confirm that HAC tokens preserve naturalness and provide interpretable linguistic information, outperforming single-level baselines in both disentanglement and reconstruction quality. These findings underscore HAC's potential as a unified discrete speech representation, bridging acoustic detail and lexical meaning for downstream speech generation and understanding tasks.
Aligning Multimodal Representations through an Information Bottleneck
Jun 05, 2025Contrastive losses have been extensively used as a tool for multimodal representation learning. However, it has been empirically observed that their use is not effective to learn an aligned representation space. In this paper, we argue that this phenomenon is caused by the presence of modality-specific information in the representation space. Although some of the most widely used contrastive losses maximize the mutual information between representations of both modalities, they are not designed to remove the modality-specific information. We give a theoretical description of this problem through the lens of the Information Bottleneck Principle. We also empirically analyze how different hyperparameters affect the emergence of this phenomenon in a controlled experimental setup. Finally, we propose a regularization term in the loss function that is derived by means of a variational approximation and aims to increase the representational alignment. We analyze in a set of controlled experiments and real-world applications the advantages of including this regularization term.
Text-Speech Language Models with Improved Cross-Modal Transfer by Aligning Abstraction Levels
Mar 08, 2025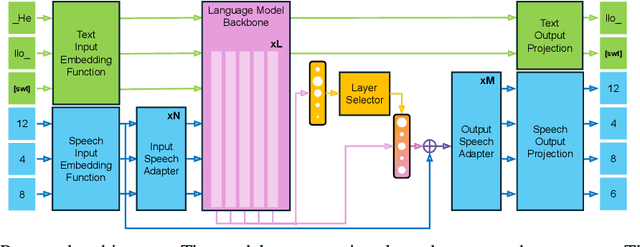
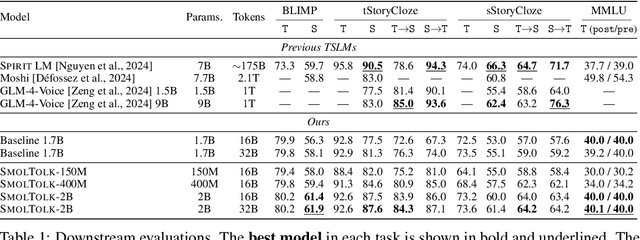
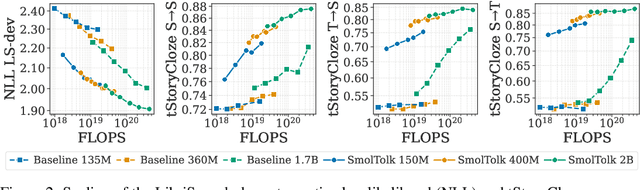
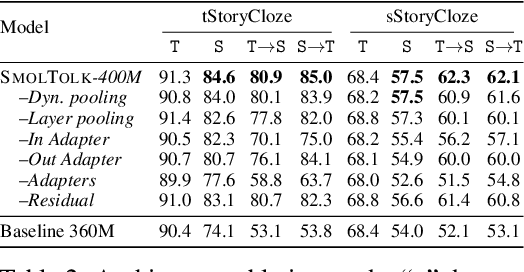
Text-Speech Language Models (TSLMs) -- language models trained to jointly process and generate text and speech -- aim to enable cross-modal knowledge transfer to overcome the scaling limitations of unimodal speech LMs. The predominant approach to TSLM training expands the vocabulary of a pre-trained text LM by appending new embeddings and linear projections for speech, followed by fine-tuning on speech data. We hypothesize that this method limits cross-modal transfer by neglecting feature compositionality, preventing text-learned functions from being fully leveraged at appropriate abstraction levels. To address this, we propose augmenting vocabulary expansion with modules that better align abstraction levels across layers. Our models, \textsc{SmolTolk}, rival or surpass state-of-the-art TSLMs trained with orders of magnitude more compute. Representation analyses and improved multimodal performance suggest our method enhances cross-modal transfer.
SMITIN: Self-Monitored Inference-Time INtervention for Generative Music Transformers
Apr 02, 2024



We introduce Self-Monitored Inference-Time INtervention (SMITIN), an approach for controlling an autoregressive generative music transformer using classifier probes. These simple logistic regression probes are trained on the output of each attention head in the transformer using a small dataset of audio examples both exhibiting and missing a specific musical trait (e.g., the presence/absence of drums, or real/synthetic music). We then steer the attention heads in the probe direction, ensuring the generative model output captures the desired musical trait. Additionally, we monitor the probe output to avoid adding an excessive amount of intervention into the autoregressive generation, which could lead to temporally incoherent music. We validate our results objectively and subjectively for both audio continuation and text-to-music applications, demonstrating the ability to add controls to large generative models for which retraining or even fine-tuning is impractical for most musicians. Audio samples of the proposed intervention approach are available on our demo page http://tinyurl.com/smitin .
NIIRF: Neural IIR Filter Field for HRTF Upsampling and Personalization
Feb 27, 2024



Head-related transfer functions (HRTFs) are important for immersive audio, and their spatial interpolation has been studied to upsample finite measurements. Recently, neural fields (NFs) which map from sound source direction to HRTF have gained attention. Existing NF-based methods focused on estimating the magnitude of the HRTF from a given sound source direction, and the magnitude is converted to a finite impulse response (FIR) filter. We propose the neural infinite impulse response filter field (NIIRF) method that instead estimates the coefficients of cascaded IIR filters. IIR filters mimic the modal nature of HRTFs, thus needing fewer coefficients to approximate them well compared to FIR filters. We find that our method can match the performance of existing NF-based methods on multiple datasets, even outperforming them when measurements are sparse. We also explore approaches to personalize the NF to a subject and experimentally find low-rank adaptation to be effective.
NeuroHeed+: Improving Neuro-steered Speaker Extraction with Joint Auditory Attention Detection
Dec 12, 2023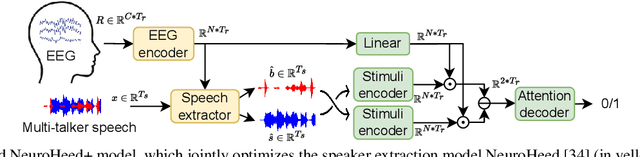

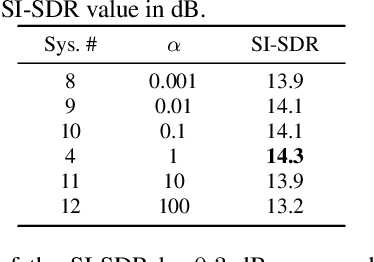
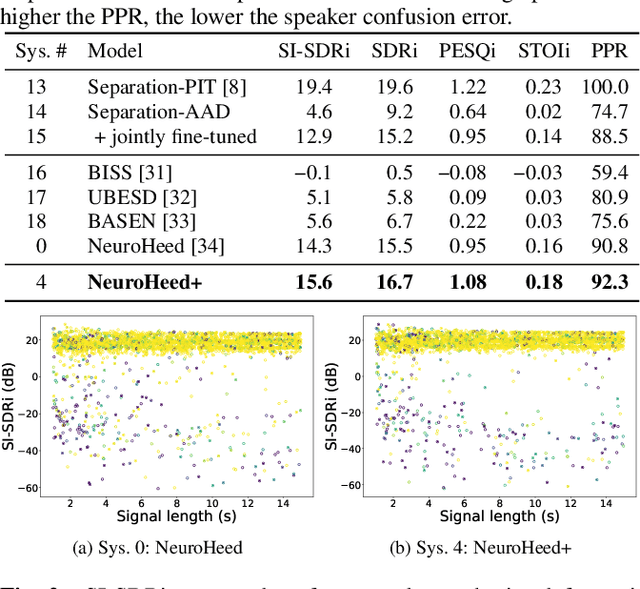
Neuro-steered speaker extraction aims to extract the listener's brain-attended speech signal from a multi-talker speech signal, in which the attention is derived from the cortical activity. This activity is usually recorded using electroencephalography (EEG) devices. Though promising, current methods often have a high speaker confusion error, where the interfering speaker is extracted instead of the attended speaker, degrading the listening experience. In this work, we aim to reduce the speaker confusion error in the neuro-steered speaker extraction model through a jointly fine-tuned auxiliary auditory attention detection model. The latter reinforces the consistency between the extracted target speech signal and the EEG representation, and also improves the EEG representation. Experimental results show that the proposed network significantly outperforms the baseline in terms of speaker confusion and overall signal quality in two-talker scenarios.
Scenario-Aware Audio-Visual TF-GridNet for Target Speech Extraction
Oct 30, 2023



Target speech extraction aims to extract, based on a given conditioning cue, a target speech signal that is corrupted by interfering sources, such as noise or competing speakers. Building upon the achievements of the state-of-the-art (SOTA) time-frequency speaker separation model TF-GridNet, we propose AV-GridNet, a visual-grounded variant that incorporates the face recording of a target speaker as a conditioning factor during the extraction process. Recognizing the inherent dissimilarities between speech and noise signals as interfering sources, we also propose SAV-GridNet, a scenario-aware model that identifies the type of interfering scenario first and then applies a dedicated expert model trained specifically for that scenario. Our proposed model achieves SOTA results on the second COG-MHEAR Audio-Visual Speech Enhancement Challenge, outperforming other models by a significant margin, objectively and in a listening test. We also perform an extensive analysis of the results under the two scenarios.
Generation or Replication: Auscultating Audio Latent Diffusion Models
Oct 16, 2023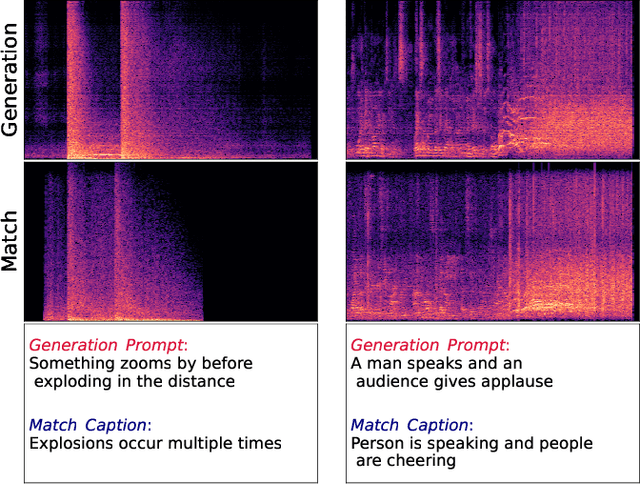
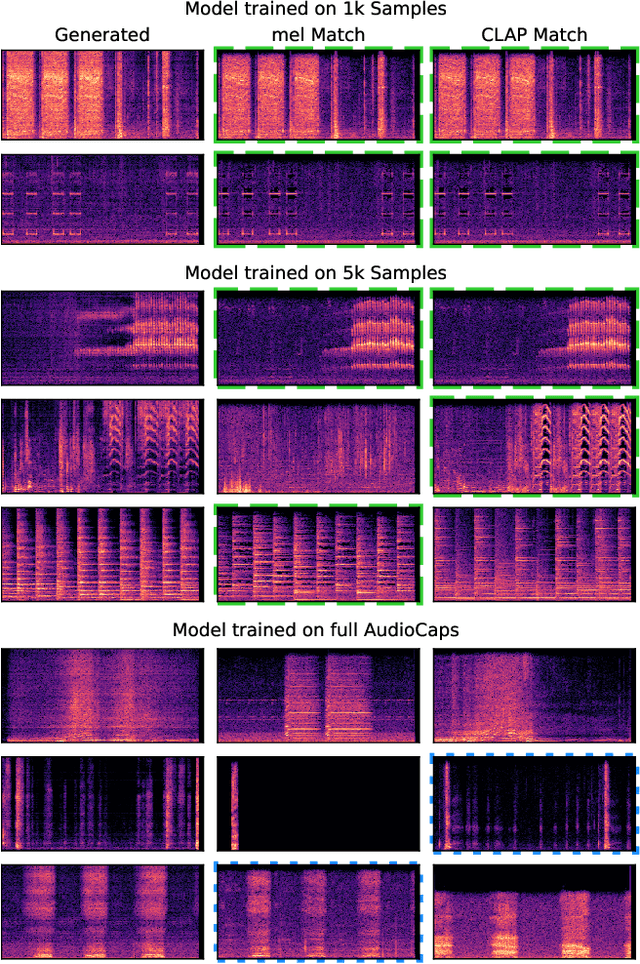
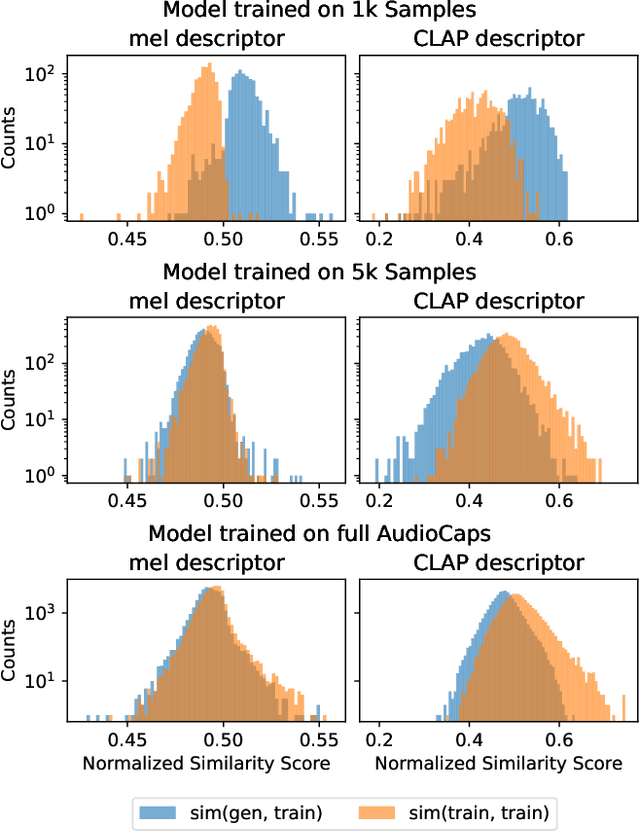
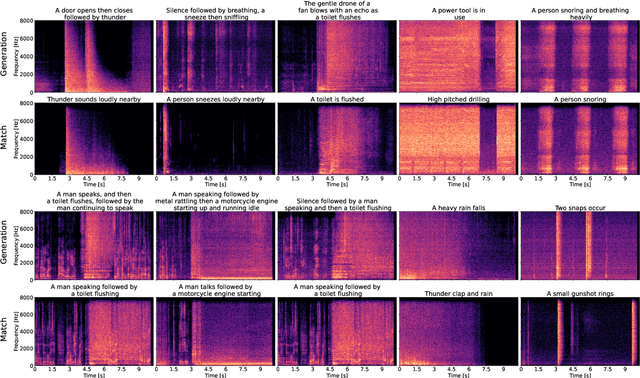
The introduction of audio latent diffusion models possessing the ability to generate realistic sound clips on demand from a text description has the potential to revolutionize how we work with audio. In this work, we make an initial attempt at understanding the inner workings of audio latent diffusion models by investigating how their audio outputs compare with the training data, similar to how a doctor auscultates a patient by listening to the sounds of their organs. Using text-to-audio latent diffusion models trained on the AudioCaps dataset, we systematically analyze memorization behavior as a function of training set size. We also evaluate different retrieval metrics for evidence of training data memorization, finding the similarity between mel spectrograms to be more robust in detecting matches than learned embedding vectors. In the process of analyzing memorization in audio latent diffusion models, we also discover a large amount of duplicated audio clips within the AudioCaps database.
Direct Text to Speech Translation System using Acoustic Units
Sep 14, 2023This paper proposes a direct text to speech translation system using discrete acoustic units. This framework employs text in different source languages as input to generate speech in the target language without the need for text transcriptions in this language. Motivated by the success of acoustic units in previous works for direct speech to speech translation systems, we use the same pipeline to extract the acoustic units using a speech encoder combined with a clustering algorithm. Once units are obtained, an encoder-decoder architecture is trained to predict them. Then a vocoder generates speech from units. Our approach for direct text to speech translation was tested on the new CVSS corpus with two different text mBART models employed as initialisation. The systems presented report competitive performance for most of the language pairs evaluated. Besides, results show a remarkable improvement when initialising our proposed architecture with a model pre-trained with more languages.
Whisper-AT: Noise-Robust Automatic Speech Recognizers are Also Strong General Audio Event Taggers
Jul 06, 2023



In this paper, we focus on Whisper, a recent automatic speech recognition model trained with a massive 680k hour labeled speech corpus recorded in diverse conditions. We first show an interesting finding that while Whisper is very robust against real-world background sounds (e.g., music), its audio representation is actually not noise-invariant, but is instead highly correlated to non-speech sounds, indicating that Whisper recognizes speech conditioned on the noise type. With this finding, we build a unified audio tagging and speech recognition model Whisper-AT by freezing the backbone of Whisper, and training a lightweight audio tagging model on top of it. With <1% extra computational cost, Whisper-AT can recognize audio events, in addition to spoken text, in a single forward pass.