 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Text to Speech Translation System using Acoustic Units
Sep 14, 2023This paper proposes a direct text to speech translation system using discrete acoustic units. This framework employs text in different source languages as input to generate speech in the target language without the need for text transcriptions in this language. Motivated by the success of acoustic units in previous works for direct speech to speech translation systems, we use the same pipeline to extract the acoustic units using a speech encoder combined with a clustering algorithm. Once units are obtained, an encoder-decoder architecture is trained to predict them. Then a vocoder generates speech from units. Our approach for direct text to speech translation was tested on the new CVSS corpus with two different text mBART models employed as initialisation. The systems presented report competitive performance for most of the language pairs evaluated. Besides, results show a remarkable improvement when initialising our proposed architecture with a model pre-trained with more languages.
Improved Cross-Lingual Transfer Learning For Automatic Speech Translation
Jun 01, 2023



Research in multilingual speech-to-text translation is topical. Having a single model that supports multiple translation tasks is desirable. The goal of this work it to improve cross-lingual transfer learning in multilingual speech-to-text translation via semantic knowledge distillation. We show that by initializing the encoder of the encoder-decoder sequence-to-sequence translation model with SAMU-XLS-R, a multilingual speech transformer encoder trained using multi-modal (speech-text) semantic knowledge distillation, we achieve significantly better cross-lingual task knowledge transfer than the baseline XLS-R, a multilingual speech transformer encoder trained via self-supervised learning. We demonstrate the effectiveness of our approach on two popular datasets, namely, CoVoST-2 and Europarl. On the 21 translation tasks of the CoVoST-2 benchmark, we achieve an average improvement of 12.8 BLEU points over the baselines. In the zero-shot translation scenario, we achieve an average gain of 18.8 and 11.9 average BLEU points on unseen medium and low-resource languages. We make similar observations on Europarl speech translation benchmark.
Generalizing AUC Optimization to Multiclass Classification for Audio Segmentation With Limited Training Data
Oct 27, 2021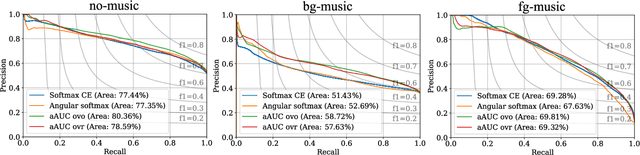
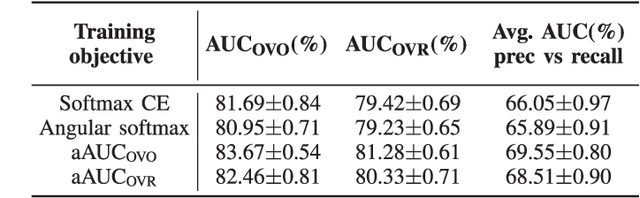

Area under the ROC curve (AUC) optimisation techniques developed for neural networks have recently demonstrated their capabilities in different audio and speech related tasks. However, due to its intrinsic nature, AUC optimisation has focused only on binary tasks so far. In this paper, we introduce an extension to the AUC optimisation framework so that it can be easily applied to an arbitrary number of classes, aiming to overcome the issues derived from training data limitations in deep learning solutions. Building upon the multiclass definitions of the AUC metric found in the literature, we define two new training objectives using a one-versus-one and a one-versus-rest approach. In order to demonstrate its potential, we apply them in an audio segmentation task with limited training data that aims to differentiate 3 classes: foreground music, background music and no music. Experimental results show that our proposal can improve the performance of audio segmentation systems significantly compared to traditional training criteria such as cross entropy.