 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Speaker Diarization: Current Databases, Approaches and Challenges
Sep 09, 2024Nowadays, the large amount of audio-visual content available has fostered the need to develop new robust automatic speaker diarization systems to analyse and characterise it. This kind of system helps to reduce the cost of doing this process manually and allows the use of the speaker information for different applications, as a huge quantity of information is present, for example, images of faces, or audio recordings. Therefore, this paper aims to address a critical area in the field of speaker diarization systems, the integration of audio-visual content of different domains. This paper seeks to push beyond current state-of-the-art practices by developing a robust audio-visual speaker diarization framework adaptable to various data domains, including TV scenarios, meetings, and daily activities. Unlike most of the existing audio-visual speaker diarization systems, this framework will also include the proposal of an approach to lead the precise assignment of specific identities in TV scenarios where celebrities appear. In addition, in this work, we have conducted an extensive compilation of the current state-of-the-art approaches and the existing databases for developing audio-visual speaker diarization.
Defining and Measuring Disentanglement for non-Independent Factors of Variation
Aug 13, 2024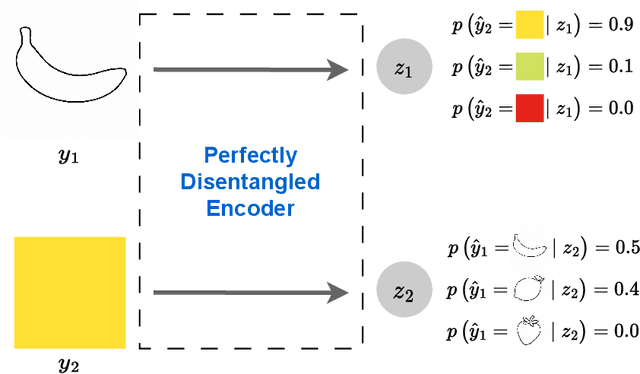
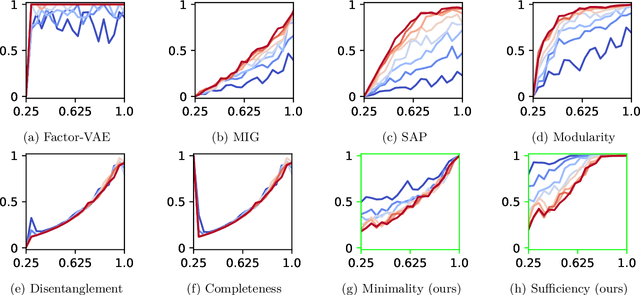

Representation learning is an approach that allows to discover and extract the factors of variation from the data. Intuitively, a representation is said to be disentangled if it separates the different factors of variation in a way that is understandable to humans. Definitions of disentanglement and metrics to measure it usually assume that the factors of variation are independent of each other. However, this is generally false in the real world, which limits the use of these definitions and metrics to very specific and unrealistic scenarios. In this paper we give a definition of disentanglement based on information theory that is also valid when the factors of variation are not independent. Furthermore, we relate this definition to the Information Bottleneck Method. Finally, we propose a method to measure the degree of disentanglement from the given definition that works when the factors of variation are not independent. We show through different experiments that the method proposed in this paper correctly measures disentanglement with non-independent factors of variation, while other methods fail in this scenario.
Predefined Prototypes for Intra-Class Separation and Disentanglement
Jun 23, 2024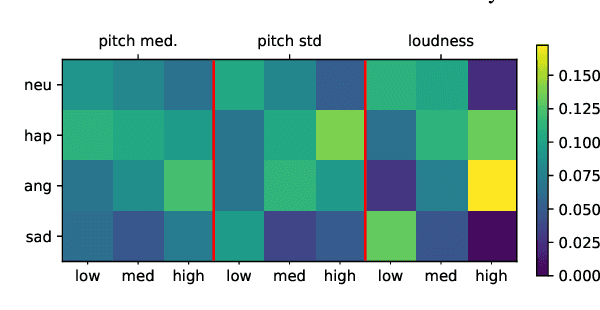
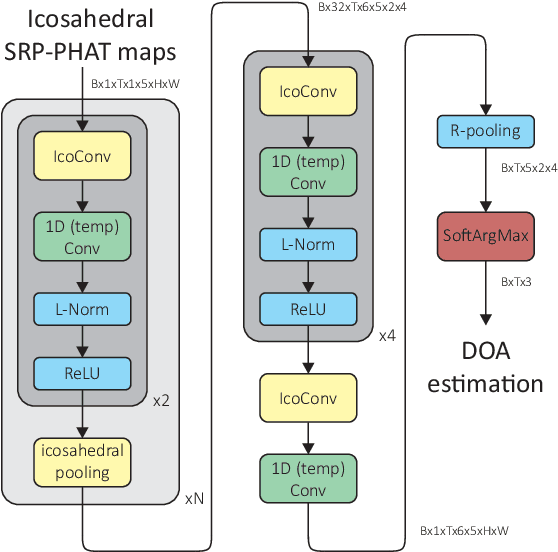
Prototypical Learning is based on the idea that there is a point (which we call prototype) around which the embeddings of a class are clustered. It has shown promising results in scenarios with little labeled data or to design explainable models. Typically, prototypes are either defined as the average of the embeddings of a class or are designed to be trainable. In this work, we propose to predefine prototypes following human-specified criteria, which simplify the training pipeline and brings different advantages. Specifically, in this work we explore two of these advantages: increasing the inter-class separability of embeddings and disentangling embeddings with respect to different variance factors, which can translate into the possibility of having explainable predictions. Finally, we propose different experiments that help to understand our proposal and demonstrate empirically the mentioned advantages.
Permutation Invariant Recurrent Neural Networks for Sound Source Tracking Applications
Jun 14, 2023



Many multi-source localization and tracking models based on neural networks use one or several recurrent layers at their final stages to track the movement of the sources. Conventional recurrent neural networks (RNNs), such as the long short-term memories (LSTMs) or the gated recurrent units (GRUs), take a vector as their input and use another vector to store their state. However, this approach results in the information from all the sources being contained in a single ordered vector, which is not optimal for permutation-invariant problems such as multi-source tracking. In this paper, we present a new recurrent architecture that uses unordered sets to represent both its input and its state and that is invariant to the permutations of the input set and equivariant to the permutations of the state set. Hence, the information of every sound source is represented in an individual embedding and the new estimates are assigned to the tracked trajectories regardless of their order.
Direction of Arrival Estimation of Sound Sources Using Icosahedral CNNs
Mar 31, 2022
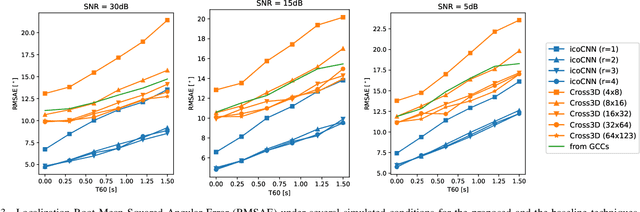
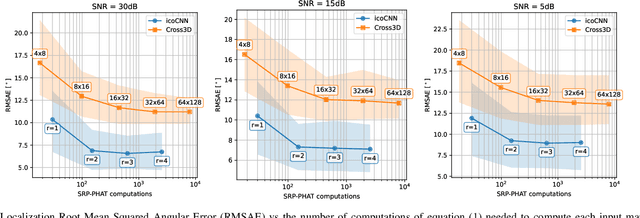
In this paper, we present a new model for Direction of Arrival (DOA) estimation of sound sources based on an Icosahedral Convolutional Neural Network (CNN) applied over SRP-PHAT power maps computed from the signals received by a microphone array. This icosahedral CNN is equivariant to the 60 rotational symmetries of the icosahedron, which represent a good approximation of the continuous space of spherical rotations, and can be implemented using standard 2D convolutional layers, having a lower computational cost than most of the spherical CNNs. In addition, instead of using fully connected layers after the icosahedral convolutions, we propose a new soft-argmax function that can be seen as a differentiable version of the argmax function and allows us to solve the DOA estimation as a regression problem interpreting the output of the convolutional layers as a probability distribution. We prove that using models that fit the equivariances of the problem allows us to outperform other state-of-the-art models with a lower computational cost and more robustness, obtaining root mean square localization errors lower than 10{\deg} even in scenarios with a reverberation time $T_{60}$ of 1.5 s.
Class Token and Knowledge Distillation for Multi-head Self-Attention Speaker Verification Systems
Nov 06, 2021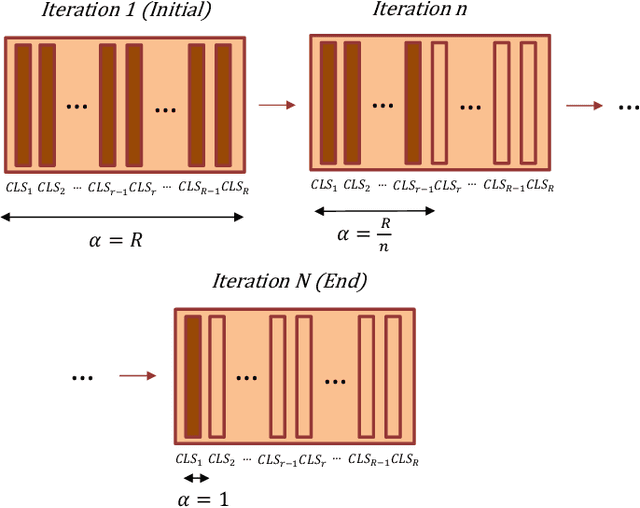
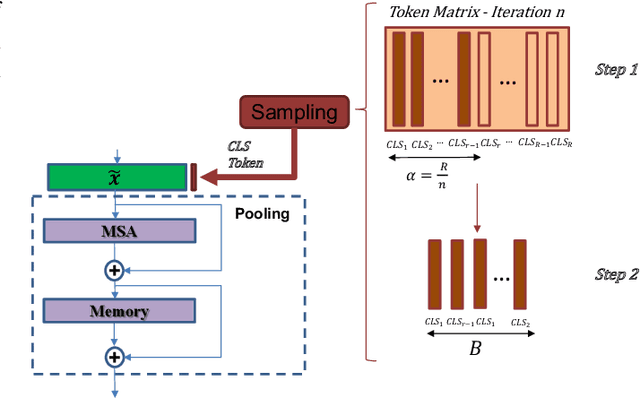
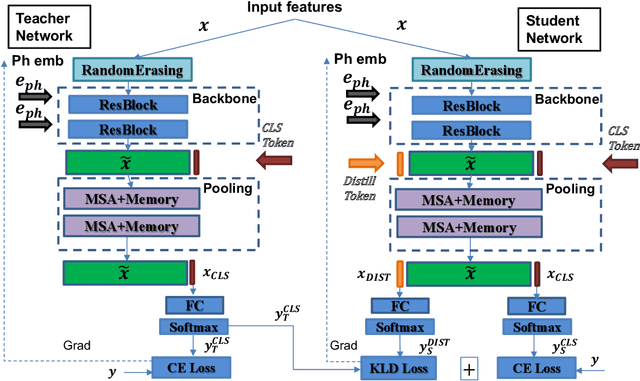
This paper explores three novel approaches to improve the performance of speaker verification (SV) systems based on deep neural networks (DNN) using Multi-head Self-Attention (MSA) mechanisms and memory layers. Firstly, we propose the use of a learnable vector called Class token to replace the average global pooling mechanism to extract the embeddings. Unlike global average pooling, our proposal takes into account the temporal structure of the input what is relevant for the text-dependent SV task. The class token is concatenated to the input before the first MSA layer, and its state at the output is used to predict the classes. To gain additional robustness, we introduce two approaches. First, we have developed a Bayesian estimation of the class token. Second, we have added a distilled representation token for training a teacher-student pair of networks using the Knowledge Distillation (KD) philosophy, which is combined with the class token. This distillation token is trained to mimic the predictions from the teacher network, while the class token replicates the true label. All the strategies have been tested on the RSR2015-Part II and DeepMine-Part 1 databases for text-dependent SV, providing competitive results compared to the same architecture using the average pooling mechanism to extract average embeddings.
Generalizing AUC Optimization to Multiclass Classification for Audio Segmentation With Limited Training Data
Oct 27, 2021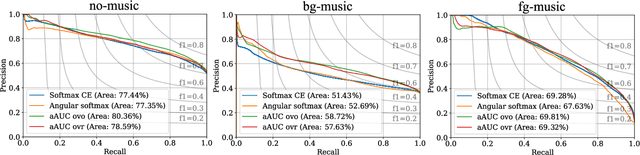
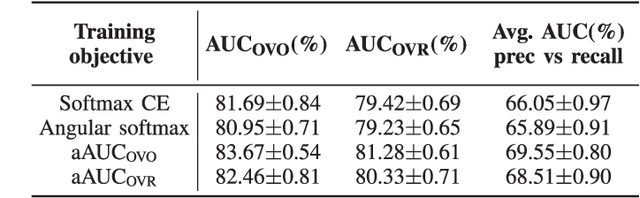

Area under the ROC curve (AUC) optimisation techniques developed for neural networks have recently demonstrated their capabilities in different audio and speech related tasks. However, due to its intrinsic nature, AUC optimisation has focused only on binary tasks so far. In this paper, we introduce an extension to the AUC optimisation framework so that it can be easily applied to an arbitrary number of classes, aiming to overcome the issues derived from training data limitations in deep learning solutions. Building upon the multiclass definitions of the AUC metric found in the literature, we define two new training objectives using a one-versus-one and a one-versus-rest approach. In order to demonstrate its potential, we apply them in an audio segmentation task with limited training data that aims to differentiate 3 classes: foreground music, background music and no music. Experimental results show that our proposal can improve the performance of audio segmentation systems significantly compared to traditional training criteria such as cross entropy.
Robust Sound Source Tracking Using SRP-PHAT and 3D Convolutional Neural Networks
Jun 16, 2020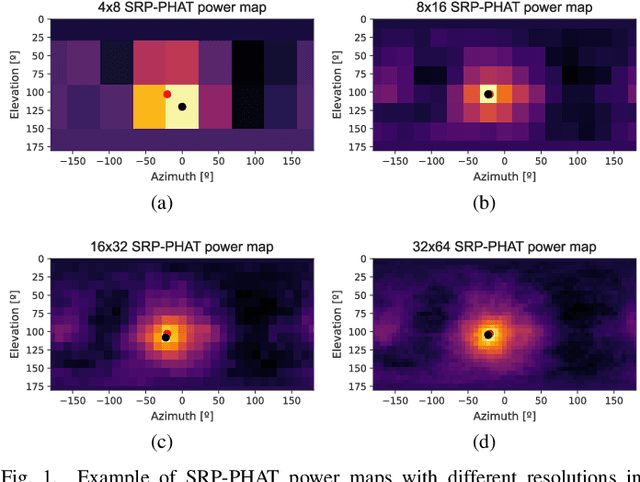
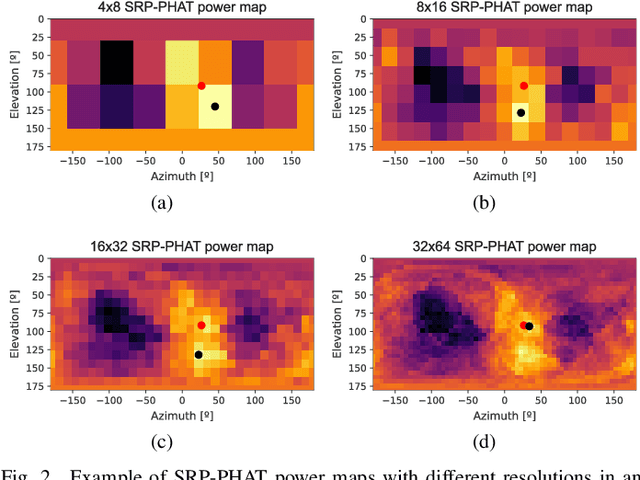
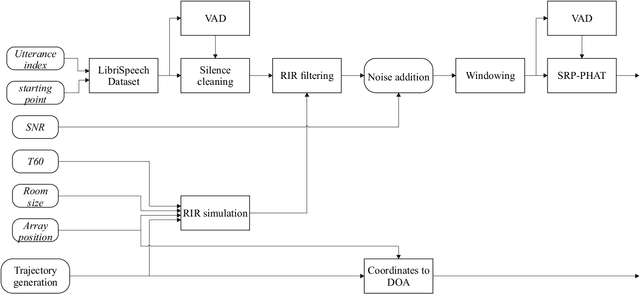
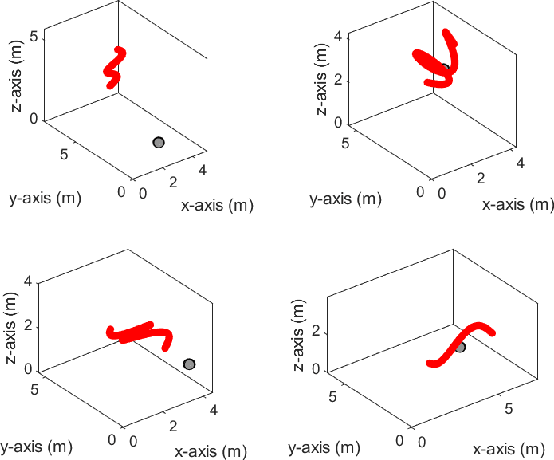
In this paper, we present a new sound source DOA estimation and tracking system based on the well known SRP-PHAT algorithm and a three-dimensional Convolutional Neural Network. It uses SRP-PHAT power maps as input features of a fully convolutional causal architecture that uses 3D convolutional layers to accurately perform the tracking of a sound source even in highly reverberant scenarios where most of the state of the art techniques fail. Unlike previous methods, since we do not use bidirectional recurrent layers and all our convolutional layers are causal in the time dimension, our system is feasible for real-time applications and it provides a new DOA estimation for each new SRP-PHAT map. To train the model, we introduce a new procedure to simulate random trajectories as they are needed during the training, equivalent to an infinite-size dataset with high flexibility to modify its acoustical conditions such as the reverberation time. We use both acoustical simulations on a large range of reverberation times and the actual recordings of the LOCATA dataset to prove the robustness of our system and its good performance even using low-resolution SRP-PHAT maps.
Optimization of the Area Under the ROC Curve using Neural Network Supervectors for Text-Dependent Speaker Verification
Jan 31, 2019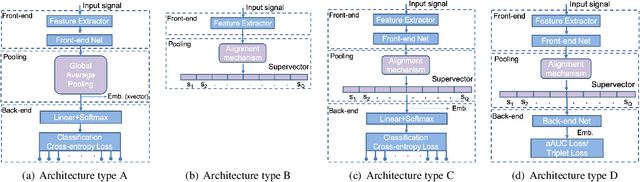
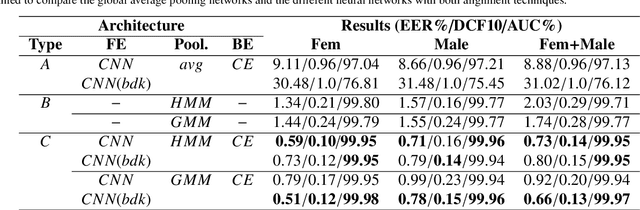

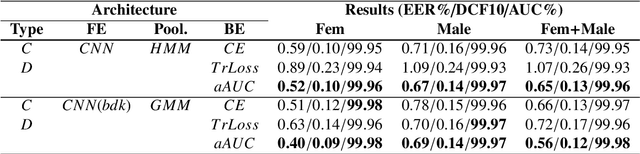
This paper explores two techniques to improve the performance of text-dependent speaker verification systems based on deep neural networks. Firstly, we propose a general alignment mechanism to keep the temporal structure of each phrase and obtain a supervector with the speaker and phrase information, since both are relevant for a text-dependent verification. As we show, it is possible to use different alignment techniques to replace the average pooling providing significant gains in performance. Moreover, we present a novel back-end approach to train a neural network for detection tasks by optimizing the Area Under the Curve (AUC) as an alternative to the usual triplet loss function, so the system is end-to-end, with a cost function closed to our desired measure of performance. As we can see in the experimental section, this approach improves the system performance, since our triplet AUC neural network learns how to discriminate between pairs of examples from the same identity and pairs of different identities. The different alignment techniques to produce supervectors in addition to the new back-end approach were tested on the RSR2015-Part I database for text-dependent speaker verification, providing competitive results compared to similar size networks using the average pooling to extract supervectors and using a simple back-end or triplet loss training.
Disentangling in Variational Autoencoders with Natural Clustering
Jan 27, 2019

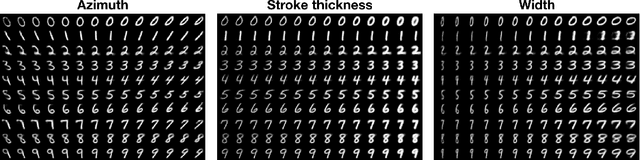

Learning representations that disentangle the underlying factors of variability in data is an intuitive precursor to AI with human-like reasoning. Consequently, it has been the object of many efforts of the machine learning community. This work takes a step further in this direction by addressing the scenario where generative factors present a multimodal distribution due to the existence of class distinction in the data. We formulate a lower bound on the joint distribution of inputs and class labels and present N-VAE, a model which is capable of separating factors of variation which are exclusive to certain classes from factors that are shared among classes. This model implements the natural clustering prior through the use of a class-conditioned latent space and a shared latent space. We show its usefulness for detecting and disentangling class-dependent generative factors as well as for generating rich artificial samples.