 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralised Transcoding Framework for Arbitrary Spatial Audio Capture and Playback Formats
Jun 16, 2026This article introduces a unified framework for the parametric analysis and reproduction of spatial sound scenes captured either as Ambisonic signals or as raw microphone array signals. The proposed method estimates time-frequency-dependent spatial metadata that characterises a variable number of primary source components and an ambience component with its own angular power distribution, whose parameters fit the observed spatial covariances of the captured signals. This metadata is used to construct spatial covariances of the target playback formats, which are then used to derive optimal mixing matrices for transcoding the scene for playback over the target reproduction system. The method additionally handles independent rotations of both capture and playback setups. Real-time implementations of the method and other existing state-of-the-art parametric renderers are compared in a listening test using simulated scenes from Ambisonic, spherical, and head-worn arrays. The results highlight perceptual benefits of the proposed framework across a diverse range of content and receiver configurations, particularly for lower-order and geometrically constrained microphone arrays.
Inter-Speaker Relative Cues for Two-Stage Text-Guided Target Speech Extraction
Mar 01, 2026This paper investigates the use of relative cues for text-based target speech extraction (TSE). We first provide a theoretical justification for relative cues from the perspectives of human perception and label quantization, showing that relative cues preserve fine-grained distinctions often lost in absolute categorical representations. Building on this analysis, we propose a two-stage TSE framework, in which a speech separation model generates candidate sources, followed by a text-guided classifier that selects the target speaker based on embedding similarity. Using this framework, we train two separate classification models to evaluate the advantages of relative cues over independent cues in terms of both classification accuracy and TSE performance. Experimental results demonstrate that (i) relative cues achieve higher overall classification accuracy and improved TSE performance compared with independent cues, (ii) the two-stage framework substantially outperforms single-stage text-conditioned extraction methods on both signal-level and objective perceptual metrics, and (iii) certain relative cues (language, gender, loudness, distance, temporal order, speaking duration, random cue and all cue) can surpass the performance of an audio-based TSE system. Further analysis reveals notable differences in discriminative power across cue types, providing insights into the effectiveness of different relative cues for TSE.
Moving Speaker Separation via Parallel Spectral-Spatial Processing
Feb 25, 2026Multi-channel speech separation in dynamic environments is challenging as time-varying spatial and spectral features evolve at different temporal scales. Existing methods typically employ sequential architectures, forcing a single network stream to simultaneously model both feature types, creating an inherent modeling conflict. In this paper, we propose a dual-branch parallel spectral-spatial (PS2) architecture that separately processes spectral and spatial features through parallel streams. The spectral branch uses a bi-directional long short-term memory (BLSTM)-based frequency module, a Mamba-based temporal module, and a self-attention module to model spectral features. The spatial branch employs bi-directional gated recurrent unit (BGRU) networks to process spatial features that encode the evolving geometric relationships between sources and microphones. Features from both branches are integrated through a cross-attention fusion mechanism that adaptively weights their contributions. Experimental results demonstrate that the PS2 outperforms existing state-of-the-art (SOTA) methods by 1.6-2.2 dB in scale-invariant signal-to-distortion ratio (SI-SDR) for moving speaker scenarios, with robust separation quality under different reverberation times (RT60), noise levels, and source movement speeds. Even with fast source movements, the proposed model maintains SI-SDR improvements of over 13 dB. These improvements are consistently observed across multiple datasets, including WHAMR! and our generated WSJ0-Demand-6ch-Move dataset.
Beyond Omnidirectional: Neural Ambisonics Encoding for Arbitrary Microphone Directivity Patterns using Cross-Attention
Jan 30, 2026We present a deep neural network approach for encoding microphone array signals into Ambisonics that generalizes to arbitrary microphone array configurations with fixed microphone count but varying locations and frequency-dependent directional characteristics. Unlike previous methods that rely only on array geometry as metadata, our approach uses directional array transfer functions, enabling accurate characterization of real-world arrays. The proposed architecture employs separate encoders for audio and directional responses, combining them through cross-attention mechanisms to generate array-independent spatial audio representations. We evaluate the method on simulated data in two settings: a mobile phone with complex body scattering, and a free-field condition, both with varying numbers of sound sources in reverberant environments. Evaluations demonstrate that our approach outperforms both conventional digital signal processing-based methods and existing deep neural network solutions. Furthermore, using array transfer functions instead of geometry as metadata input improves accuracy on realistic arrays.
Multi-Utterance Speech Separation and Association Trained on Short Segments
Jul 03, 2025Current deep neural network (DNN) based speech separation faces a fundamental challenge -- while the models need to be trained on short segments due to computational constraints, real-world applications typically require processing significantly longer recordings with multiple utterances per speaker than seen during training. In this paper, we investigate how existing approaches perform in this challenging scenario and propose a frequency-temporal recurrent neural network (FTRNN) that effectively bridges this gap. Our FTRNN employs a full-band module to model frequency dependencies within each time frame and a sub-band module that models temporal patterns in each frequency band. Despite being trained on short fixed-length segments of 10 s, our model demonstrates robust separation when processing signals significantly longer than training segments (21-121 s) and preserves speaker association across utterance gaps exceeding those seen during training. Unlike the conventional segment-separation-stitch paradigm, our lightweight approach (0.9 M parameters) performs inference on long audio without segmentation, eliminating segment boundary distortions while simplifying deployment. Experimental results demonstrate the generalization ability of FTRNN for multi-utterance speech separation and speaker association.
Attractor-Based Speech Separation of Multiple Utterances by Unknown Number of Speakers
May 22, 2025This paper addresses the problem of single-channel speech separation, where the number of speakers is unknown, and each speaker may speak multiple utterances. We propose a speech separation model that simultaneously performs separation, dynamically estimates the number of speakers, and detects individual speaker activities by integrating an attractor module. The proposed system outperforms existing methods by introducing an attractor-based architecture that effectively combines local and global temporal modeling for multi-utterance scenarios. To evaluate the method in reverberant and noisy conditions, a multi-speaker multi-utterance dataset was synthesized by combining Librispeech speech signals with WHAM! noise signals. The results demonstrate that the proposed system accurately estimates the number of sources. The system effectively detects source activities and separates the corresponding utterances into correct outputs in both known and unknown source count scenarios.
Score-informed Music Source Separation: Improving Synthetic-to-real Generalization in Classical Music
Mar 10, 2025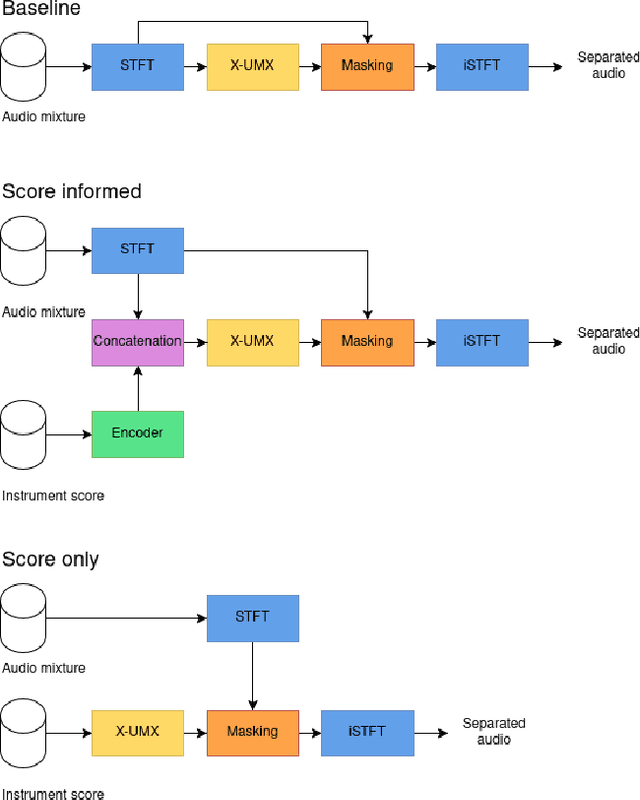
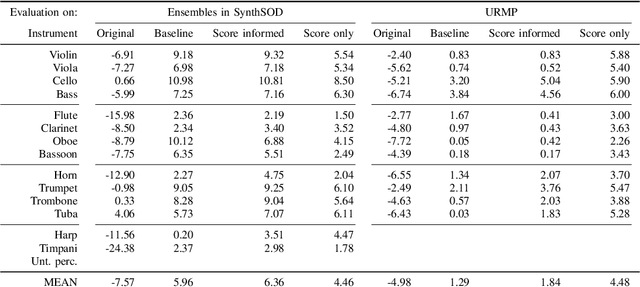
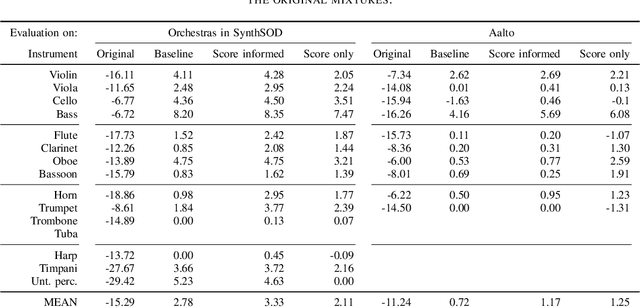
Music source separation is the task of separating a mixture of instruments into constituent tracks. Music source separation models are typically trained using only audio data, although additional information can be used to improve the model's separation capability. In this paper, we propose two ways of using musical scores to aid music source separation: a score-informed model where the score is concatenated with the magnitude spectrogram of the audio mixture as the input of the model, and a model where we use only the score to calculate the separation mask. We train our models on synthetic data in the SynthSOD dataset and evaluate our methods on the URMP and Aalto anechoic orchestra datasets, comprised of real recordings. The score-informed model improves separation results compared to a baseline approach, but struggles to generalize from synthetic to real data, whereas the score-only model shows a clear improvement in synthetic-to-real generalization.
Gen-A: Generalizing Ambisonics Neural Encoding to Unseen Microphone Arrays
Jan 14, 2025


Using deep neural networks (DNNs) for encoding of microphone array (MA) signals to the Ambisonics spatial audio format can surpass certain limitations of established conventional methods, but existing DNN-based methods need to be trained separately for each MA. This paper proposes a DNN-based method for Ambisonics encoding that can generalize to arbitrary MA geometries unseen during training. The method takes as inputs the MA geometry and MA signals and uses a multi-level encoder consisting of separate paths for geometry and signal data, where geometry features inform the signal encoder at each level. The method is validated in simulated anechoic and reverberant conditions with one and two sources. The results indicate improvement over conventional encoding across the whole frequency range for dry scenes, while for reverberant scenes the improvement is frequency-dependent.
Class-Incremental Learning for Sound Event Localization and Detection
Nov 19, 2024This paper investigates the feasibility of class-incremental learning (CIL) for Sound Event Localization and Detection (SELD) tasks. The method features an incremental learner that can learn new sound classes independently while preserving knowledge of old classes. The continual learning is achieved through a mean square error-based distillation loss to minimize output discrepancies between subsequent learners. The experiments are conducted on the TAU-NIGENS Spatial Sound Events 2021 dataset, which includes 12 different sound classes and demonstrate the efficacy of proposed method. We begin by learning 8 classes and introduce the 4 new classes at next stage. After the incremental phase, the system is evaluated on the full set of learned classes. Results show that, for this realistic dataset, our proposed method successfully maintains baseline performance across all metrics.
SynthSOD: Developing an Heterogeneous Dataset for Orchestra Music Source Separation
Sep 17, 2024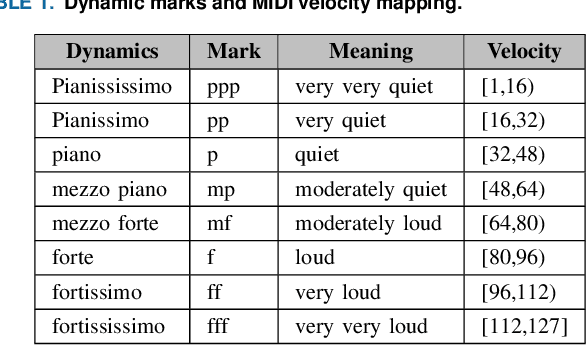
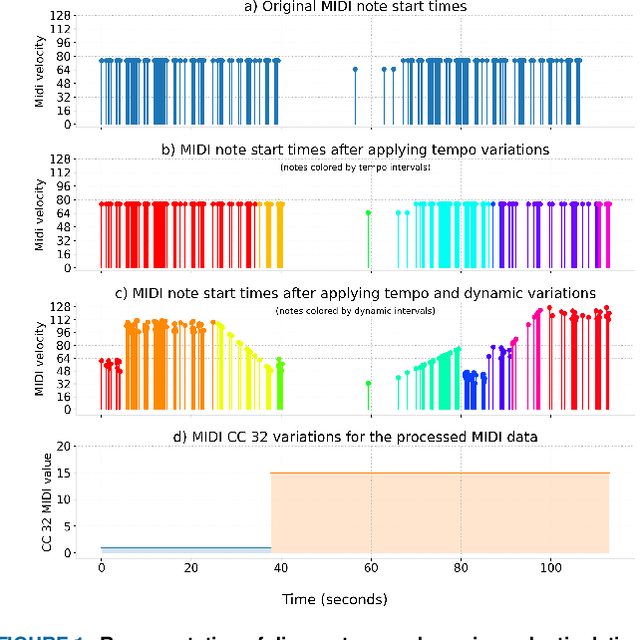
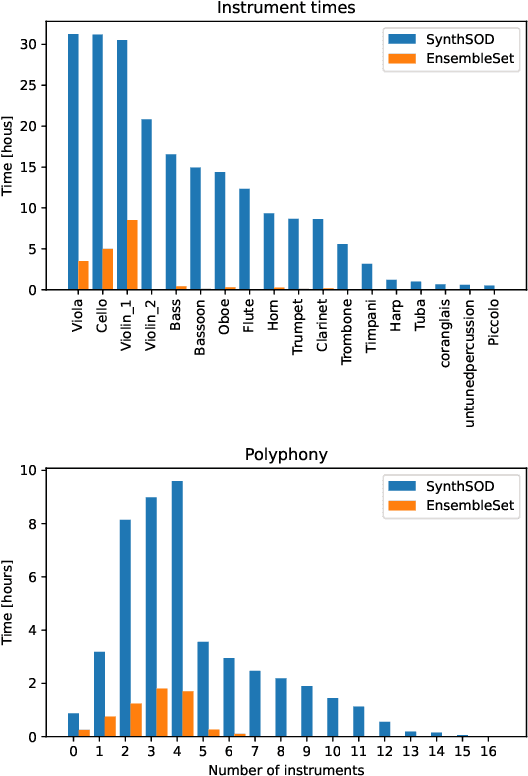
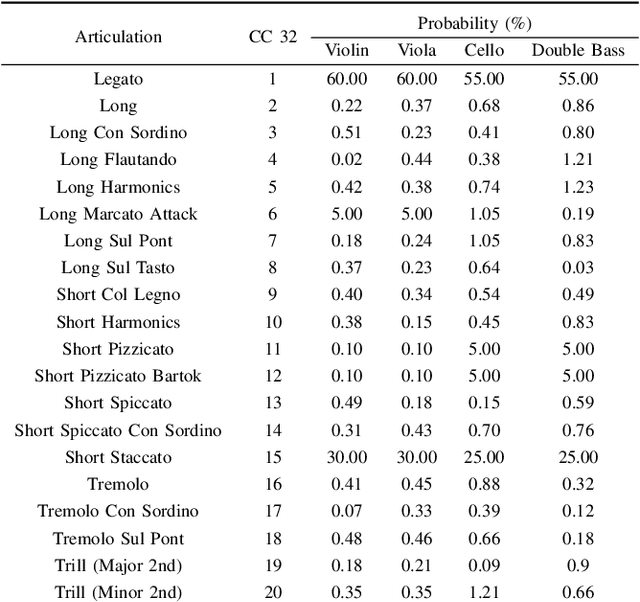
Recent advancements in music source separation have significantly progressed, particularly in isolating vocals, drums, and bass elements from mixed tracks. These developments owe much to the creation and use of large-scale, multitrack datasets dedicated to these specific components. However, the challenge of extracting similarly sounding sources from orchestra recordings has not been extensively explored, largely due to a scarcity of comprehensive and clean (i.e bleed-free) multitrack datasets. In this paper, we introduce a novel multitrack dataset called SynthSOD, developed using a set of simulation techniques to create a realistic (i.e. using high-quality soundfonts), musically motivated, and heterogeneous training set comprising different dynamics, natural tempo changes, styles, and conditions. Moreover, we demonstrate the application of a widely used baseline music separation model trained on our synthesized dataset w.r.t to the well-known EnsembleSet, and evaluate its performance under both synthetic and real-world conditions.