 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Distance Estimation in Enclosures from Single-Channel Audio
Mar 26, 2024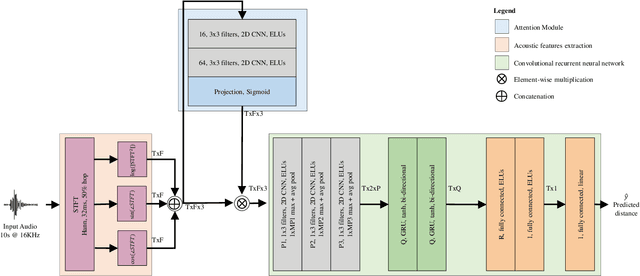


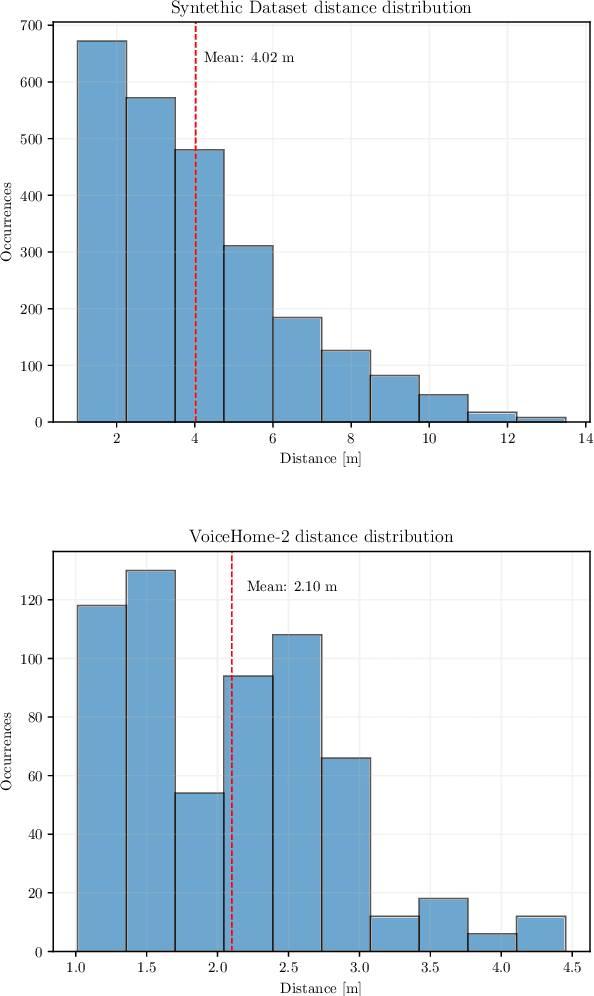
Distance estimation from audio plays a crucial role in various applications, such as acoustic scene analysis, sound source localization, and room modeling. Most studies predominantly center on employing a classification approach, where distances are discretized into distinct categories, enabling smoother model training and achieving higher accuracy but imposing restrictions on the precision of the obtained sound source position. Towards this direction, in this paper we propose a novel approach for continuous distance estimation from audio signals using a convolutional recurrent neural network with an attention module. The attention mechanism enables the model to focus on relevant temporal and spectral features, enhancing its ability to capture fine-grained distance-related information. To evaluate the effectiveness of our proposed method, we conduct extensive experiments using audio recordings in controlled environments with three levels of realism (synthetic room impulse response, measured response with convolved speech, and real recordings) on four datasets (our synthetic dataset, QMULTIMIT, VoiceHome-2, and STARSS23). Experimental results show that the model achieves an absolute error of 0.11 meters in a noiseless synthetic scenario. Moreover, the results showed an absolute error of about 1.30 meters in the hybrid scenario. The algorithm's performance in the real scenario, where unpredictable environmental factors and noise are prevalent, yields an absolute error of approximately 0.50 meters. For reproducible research purposes we make model, code, and synthetic datasets available at https://github.com/michaelneri/audio-distance-estimation.
STARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events
Jun 15, 2023



While direction of arrival (DOA) of sound events is generally estimated from multichannel audio data recorded in a microphone array, sound events usually derive from visually perceptible source objects, e.g., sounds of footsteps come from the feet of a walker. This paper proposes an audio-visual sound event localization and detection (SELD) task, which uses multichannel audio and video information to estimate the temporal activation and DOA of target sound events. Audio-visual SELD systems can detect and localize sound events using signals from a microphone array and audio-visual correspondence. We also introduce an audio-visual dataset, Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23), which consists of multichannel audio data recorded with a microphone array, video data, and spatiotemporal annotation of sound events. Sound scenes in STARSS23 are recorded with instructions, which guide recording participants to ensure adequate activity and occurrences of sound events. STARSS23 also serves human-annotated temporal activation labels and human-confirmed DOA labels, which are based on tracking results of a motion capture system. Our benchmark results show that the audio-visual SELD system achieves lower localization error than the audio-only system. The data is available at https://zenodo.org/record/7880637.
STARSS22: A dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events
Jun 04, 2022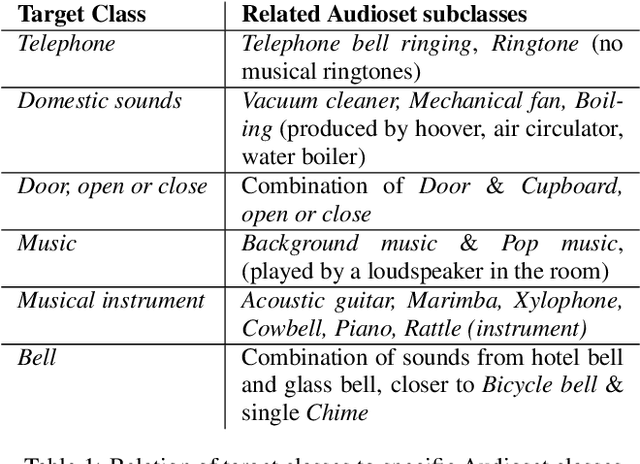
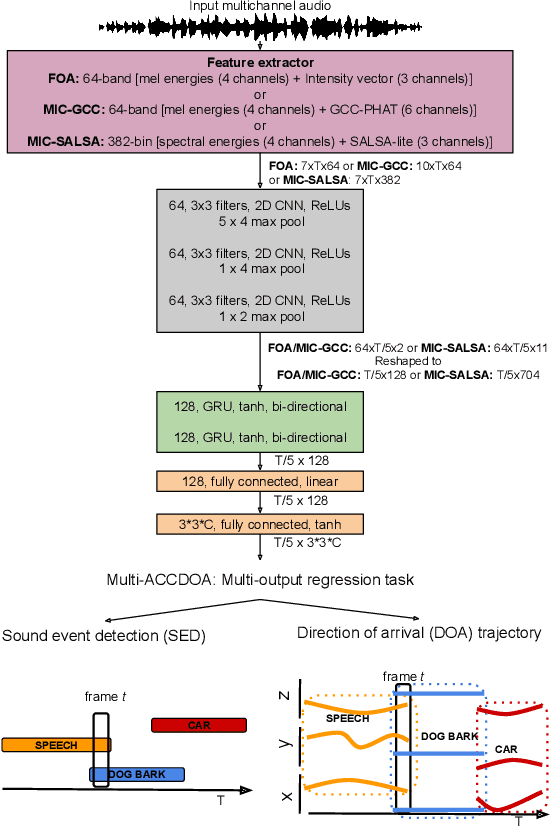
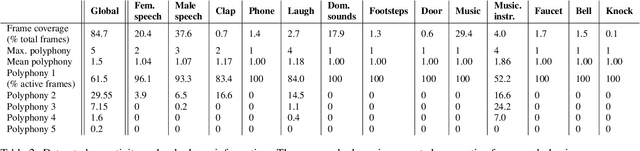

This report presents the Sony-TAu Realistic Spatial Soundscapes 2022 (STARS22) dataset for sound event localization and detection, comprised of spatial recordings of real scenes collected in various interiors of two different sites. The dataset is captured with a high resolution spherical microphone array and delivered in two 4-channel formats, first-order Ambisonics and tetrahedral microphone array. Sound events in the dataset belonging to 13 target sound classes are annotated both temporally and spatially through a combination of human annotation and optical tracking. The dataset serves as the development and evaluation dataset for the Task 3 of the DCASE2022 Challenge on Sound Event Localization and Detection and introduces significant new challenges for the task compared to the previous iterations, which were based on synthetic spatialized sound scene recordings. Dataset specifications are detailed including recording and annotation process, target classes and their presence, and details on the development and evaluation splits. Additionally, the report presents the baseline system that accompanies the dataset in the challenge with emphasis on the differences with the baseline of the previous iterations; namely, introduction of the multi-ACCDOA representation to handle multiple simultaneous occurences of events of the same class, and support for additional improved input features for the microphone array format. Results of the baseline indicate that with a suitable training strategy a reasonable detection and localization performance can be achieved on real sound scene recordings. The dataset is available in https://zenodo.org/record/6387880.
A Dataset of Dynamic Reverberant Sound Scenes with Directional Interferers for Sound Event Localization and Detection
Jul 04, 2021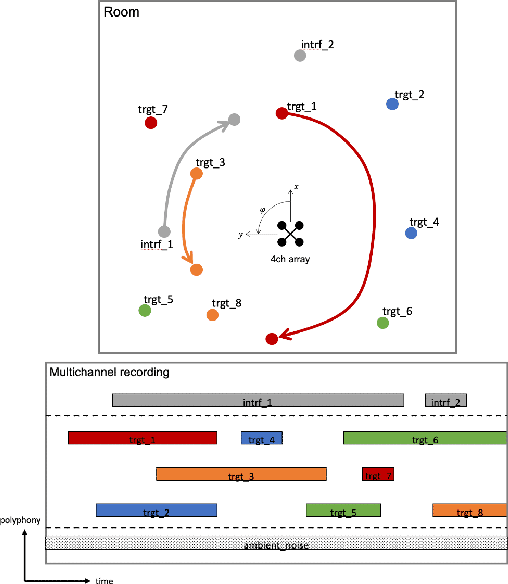

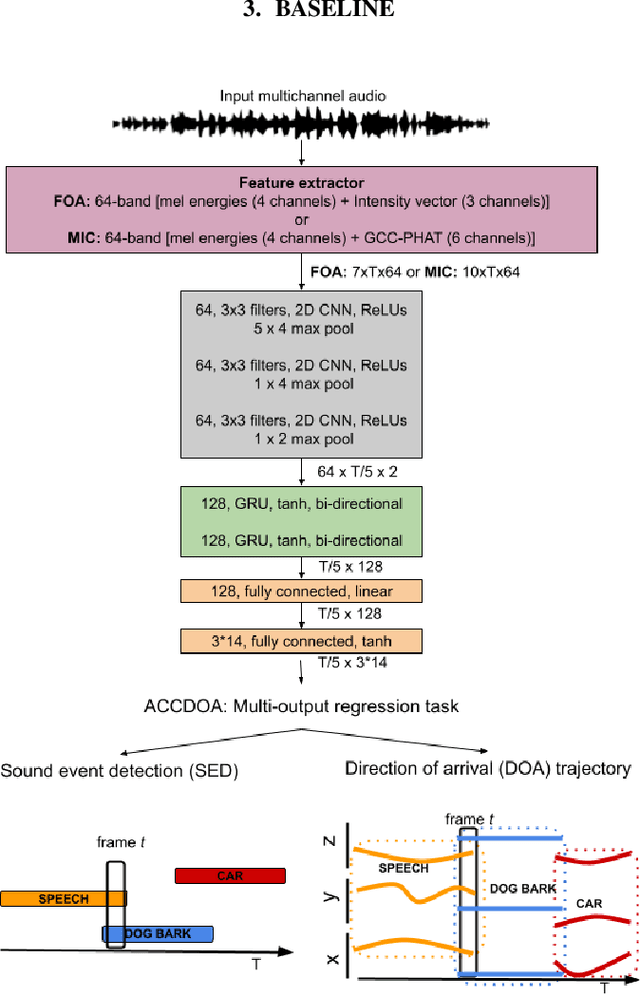
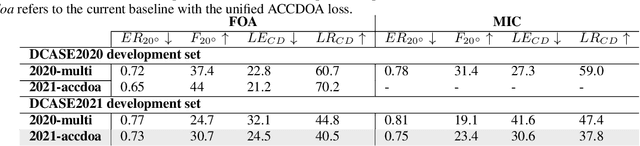
This report presents the dataset and baseline of Task 3 of the DCASE2021 Challenge on Sound Event Localization and Detection (SELD). The dataset is based on emulation of real recordings of static or moving sound events under real conditions of reverberation and ambient noise, using spatial room impulse responses captured in a variety of rooms and delivered in two spatial formats. The acoustical synthesis remains the same as in the previous iteration of the challenge, however the new dataset brings more challenging conditions of polyphony and overlapping instances of the same class. The most important difference of the new dataset is the introduction of directional interferers, meaning sound events that are localized in space but do not belong to the target classes to be detected and are not annotated. Since such interfering events are expected in every real-world scenario of SELD, the new dataset aims to promote systems that deal with this condition effectively. A modified SELDnet baseline employing the recent ACCDOA representation of SELD problems accompanies the dataset and it is shown to outperform the previous one. The new dataset is shown to be significantly more challenging for both baselines according to all considered metrics. To investigate the individual and combined effects of ambient noise, interferers, and reverberation, we study the performance of the baseline on different versions of the dataset excluding or including combinations of these factors. The results indicate that by far the most detrimental effects are caused by directional interferers.