 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Foundation Model as Generic Booster for Music Downstream Tasks
Nov 05, 2024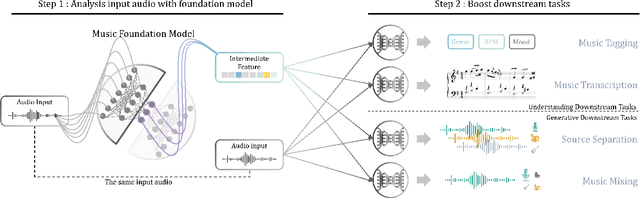

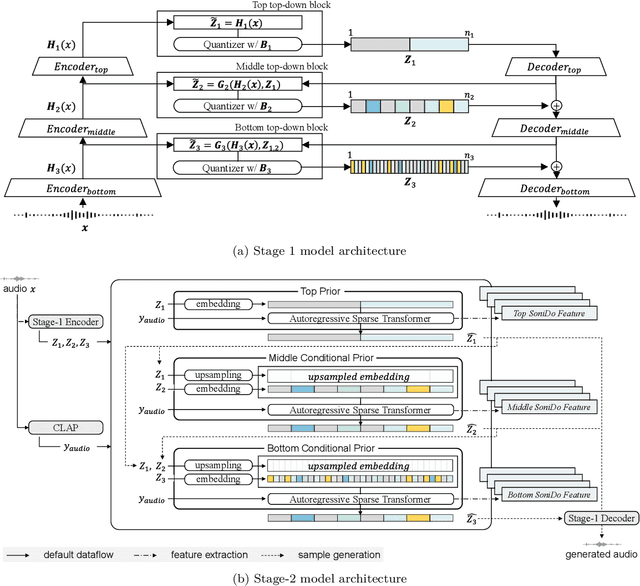

We demonstrate the efficacy of using intermediate representations from a single foundation model to enhance various music downstream tasks. We introduce SoniDo, a music foundation model (MFM) designed to extract hierarchical features from target music samples. By leveraging hierarchical intermediate features, SoniDo constrains the information granularity, leading to improved performance across various downstream tasks including both understanding and generative tasks. We specifically evaluated this approach on representative tasks such as music tagging, music transcription, music source separation, and music mixing. Our results reveal that the features extracted from foundation models provide valuable enhancements in training downstream task models. This highlights the capability of using features extracted from music foundation models as a booster for downstream tasks. Our approach not only benefits existing task-specific models but also supports music downstream tasks constrained by data scarcity. This paves the way for more effective and accessible music processing solutions.
Zero- and Few-shot Sound Event Localization and Detection
Sep 17, 2023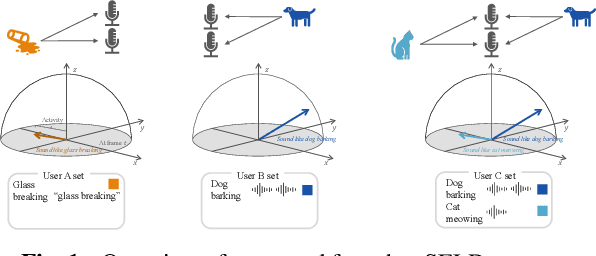



Sound event localization and detection (SELD) systems estimate direction-of-arrival (DOA) and temporal activation for sets of target classes. Neural network (NN)-based SELD systems have performed well in various sets of target classes, but they only output the DOA and temporal activation of preset classes that are trained before inference. To customize target classes after training, we tackle zero- and few-shot SELD tasks, in which we set new classes with a text sample or a few audio samples. While zero-shot sound classification tasks are achievable by embedding from contrastive language-audio pretraining (CLAP), zero-shot SELD tasks require assigning an activity and a DOA to each embedding, especially in overlapping cases. To tackle the assignment problem in overlapping cases, we propose an embed-ACCDOA model, which is trained to output track-wise CLAP embedding and corresponding activity-coupled Cartesian direction-of-arrival (ACCDOA). In our experimental evaluations on zero- and few-shot SELD tasks, the embed-ACCDOA model showed a better location-dependent scores than a straightforward combination of the CLAP audio encoder and a DOA estimation model. Moreover, the proposed combination of the embed-ACCDOA model and CLAP audio encoder with zero- or few-shot samples performed comparably to an official baseline system trained with complete train data in an evaluation dataset.
STARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events
Jun 15, 2023



While direction of arrival (DOA) of sound events is generally estimated from multichannel audio data recorded in a microphone array, sound events usually derive from visually perceptible source objects, e.g., sounds of footsteps come from the feet of a walker. This paper proposes an audio-visual sound event localization and detection (SELD) task, which uses multichannel audio and video information to estimate the temporal activation and DOA of target sound events. Audio-visual SELD systems can detect and localize sound events using signals from a microphone array and audio-visual correspondence. We also introduce an audio-visual dataset, Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23), which consists of multichannel audio data recorded with a microphone array, video data, and spatiotemporal annotation of sound events. Sound scenes in STARSS23 are recorded with instructions, which guide recording participants to ensure adequate activity and occurrences of sound events. STARSS23 also serves human-annotated temporal activation labels and human-confirmed DOA labels, which are based on tracking results of a motion capture system. Our benchmark results show that the audio-visual SELD system achieves lower localization error than the audio-only system. The data is available at https://zenodo.org/record/7880637.
Diffusion-Based Speech Enhancement with Joint Generative and Predictive Decoders
May 18, 2023



Diffusion-based speech enhancement (SE) has been investigated recently, but its decoding is very time-consuming. One solution is to initialize the decoding process with the enhanced feature estimated by a predictive SE system. However, this two-stage method ignores the complementarity between predictive and diffusion SE. In this paper, we propose a unified system that integrates these two SE modules. The system encodes both generative and predictive information, and then applies both generative and predictive decoders, whose outputs are fused. Specifically, the two SE modules are fused in the first and final diffusion steps: the first step fusion initializes the diffusion process with the predictive SE for improving the convergence, and the final step fusion combines the two complementary SE outputs to improve the SE performance. Experiments on the Voice-Bank dataset show that the diffusion score estimation can benefit from the predictive information and speed up the decoding.
Diffusion-based Signal Refiner for Speech Separation
May 12, 2023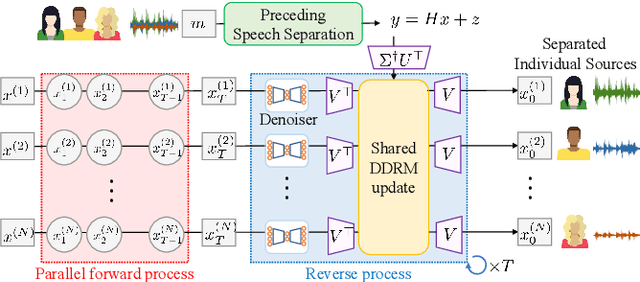



We have developed a diffusion-based speech refiner that improves the reference-free perceptual quality of the audio predicted by preceding single-channel speech separation models. Although modern deep neural network-based speech separation models have show high performance in reference-based metrics, they often produce perceptually unnatural artifacts. The recent advancements made to diffusion models motivated us to tackle this problem by restoring the degraded parts of initial separations with a generative approach. Utilizing the denoising diffusion restoration model (DDRM) as a basis, we propose a shared DDRM-based refiner that generates samples conditioned on the global information of preceding outputs from arbitrary speech separation models. We experimentally show that our refiner can provide a clearer harmonic structure of speech and improves the reference-free metric of perceptual quality for arbitrary preceding model architectures. Furthermore, we tune the variance of the measurement noise based on preceding outputs, which results in higher scores in both reference-free and reference-based metrics. The separation quality can also be further improved by blending the discriminative and generative outputs.
STARSS22: A dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events
Jun 04, 2022
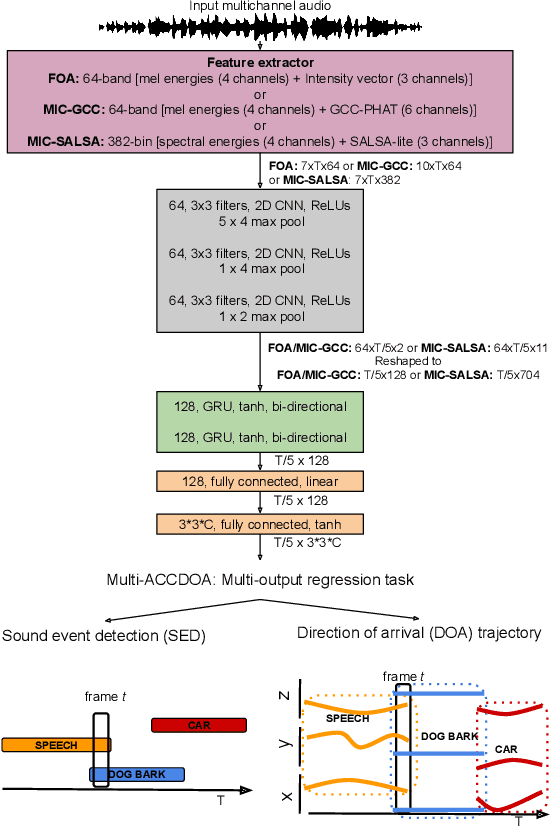
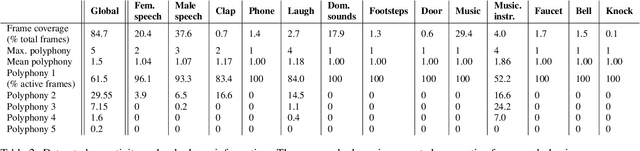

This report presents the Sony-TAu Realistic Spatial Soundscapes 2022 (STARS22) dataset for sound event localization and detection, comprised of spatial recordings of real scenes collected in various interiors of two different sites. The dataset is captured with a high resolution spherical microphone array and delivered in two 4-channel formats, first-order Ambisonics and tetrahedral microphone array. Sound events in the dataset belonging to 13 target sound classes are annotated both temporally and spatially through a combination of human annotation and optical tracking. The dataset serves as the development and evaluation dataset for the Task 3 of the DCASE2022 Challenge on Sound Event Localization and Detection and introduces significant new challenges for the task compared to the previous iterations, which were based on synthetic spatialized sound scene recordings. Dataset specifications are detailed including recording and annotation process, target classes and their presence, and details on the development and evaluation splits. Additionally, the report presents the baseline system that accompanies the dataset in the challenge with emphasis on the differences with the baseline of the previous iterations; namely, introduction of the multi-ACCDOA representation to handle multiple simultaneous occurences of events of the same class, and support for additional improved input features for the microphone array format. Results of the baseline indicate that with a suitable training strategy a reasonable detection and localization performance can be achieved on real sound scene recordings. The dataset is available in https://zenodo.org/record/6387880.
Removing Distortion Effects in Music Using Deep Neural Networks
Feb 03, 2022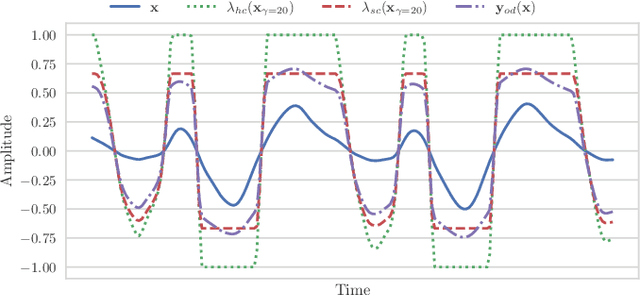
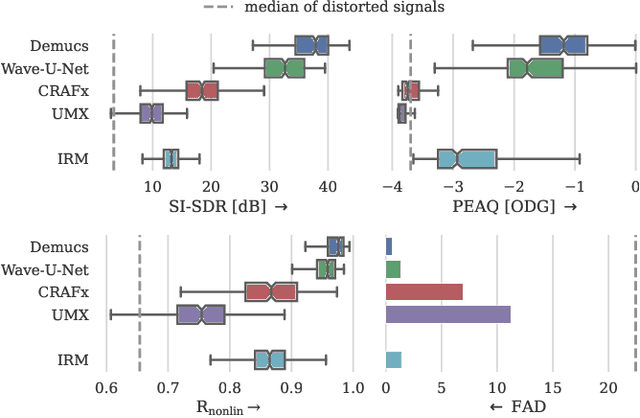
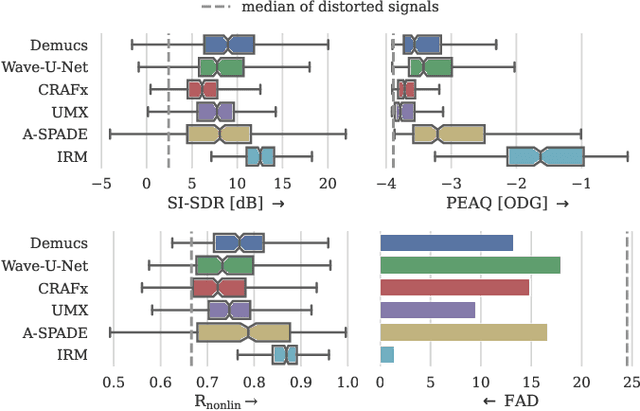
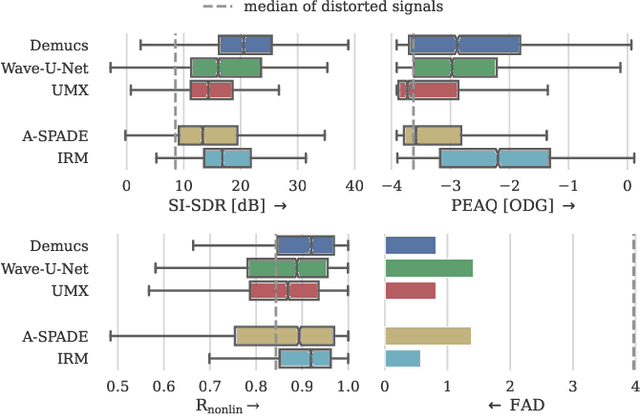
Audio effects are an essential element in the context of music production, and therefore, modeling analog audio effects has been extensively researched for decades using system-identification methods, circuit simulation, and recently, deep learning. However, only few works tackled the reconstruction of signals that were processed using an audio effect unit. Given the recent advances in music source separation and automatic mixing, the removal of audio effects could facilitate an automatic remixing system. This paper focuses on removing distortion and clipping applied to guitar tracks for music production while presenting a comparative investigation of different deep neural network (DNN) architectures on this task. We achieve exceptionally good results in distortion removal using DNNs for effects that superimpose the clean signal to the distorted signal, while the task is more challenging if the clean signal is not superimposed. Nevertheless, in the latter case, the neural models under evaluation surpass one state-of-the-art declipping system in terms of source-to-distortion ratio, leading to better quality and faster inference.
Multi-ACCDOA: Localizing and Detecting Overlapping Sounds from the Same Class with Auxiliary Duplicating Permutation Invariant Training
Oct 14, 2021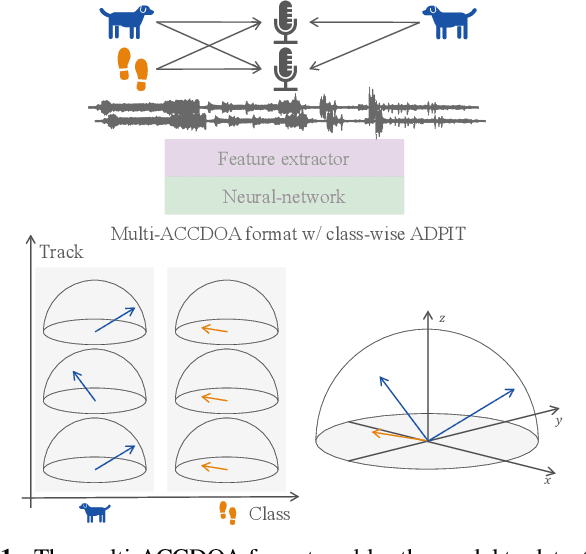



Sound event localization and detection (SELD) involves identifying the direction-of-arrival (DOA) and the event class. The SELD methods with a class-wise output format make the model predict activities of all sound event classes and corresponding locations. The class-wise methods can output activity-coupled Cartesian DOA (ACCDOA) vectors, which enable us to solve a SELD task with a single target using a single network. However, there is still a challenge in detecting the same event class from multiple locations. To overcome this problem while maintaining the advantages of the class-wise format, we extended ACCDOA to a multi one and proposed auxiliary duplicating permutation invariant training (ADPIT). The multi- ACCDOA format (a class- and track-wise output format) enables the model to solve the cases with overlaps from the same class. The class-wise ADPIT scheme enables each track of the multi-ACCDOA format to learn with the same target as the single-ACCDOA format. In evaluations with the DCASE 2021 Task 3 dataset, the model trained with the multi-ACCDOA format and with the class-wise ADPIT detects overlapping events from the same class while maintaining its performance in the other cases. Also, the proposed method performed comparably to state-of-the-art SELD methods with fewer parameters.
Spatial Data Augmentation with Simulated Room Impulse Responses for Sound Event Localization and Detection
Oct 13, 2021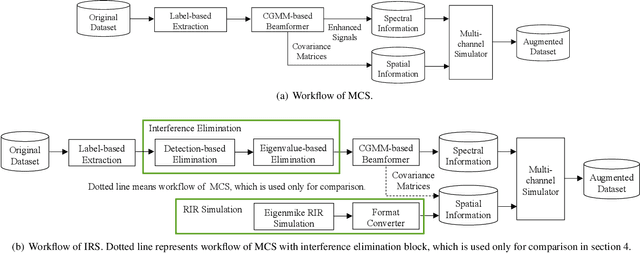
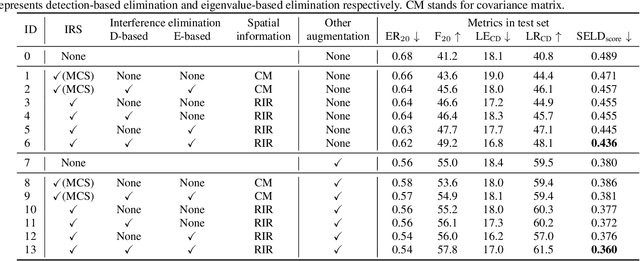

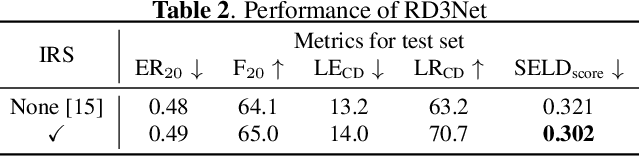
Recording and annotating real sound events for a sound event localization and detection (SELD) task is time consuming, and data augmentation techniques are often favored when the amount of data is limited. However, how to augment the spatial information in a dataset, including unlabeled directional interference events, remains an open research question. Furthermore, directional interference events make it difficult to accurately extract spatial characteristics from target sound events. To address this problem, we propose an impulse response simulation framework (IRS) that augments spatial characteristics using simulated room impulse responses (RIR). RIRs corresponding to a microphone array assumed to be placed in various rooms are accurately simulated, and the source signals of the target sound events are extracted from a mixture. The simulated RIRs are then convolved with the extracted source signals to obtain an augmented multi-channel training dataset. Evaluation results obtained using the TAU-NIGENS Spatial Sound Events 2021 dataset show that the IRS contributes to improving the overall SELD performance. Additionally, we conducted an ablation study to discuss the contribution and need for each component within the IRS.
Music Source Separation with Deep Equilibrium Models
Oct 13, 2021


While deep neural network-based music source separation (MSS) is very effective and achieves high performance, its model size is often a problem for practical deployment. Deep implicit architectures such as deep equilibrium models (DEQ) were recently proposed, which can achieve higher performance than their explicit counterparts with limited depth while keeping the number of parameters small. This makes DEQ also attractive for MSS, especially as it was originally applied to sequential modeling tasks in natural language processing and thus should in principle be also suited for MSS. However, an investigation of a good architecture and training scheme for MSS with DEQ is needed as the characteristics of acoustic signals are different from those of natural language data. Hence, in this paper we propose an architecture and training scheme for MSS with DEQ. Starting with the architecture of Open-Unmix (UMX), we replace its sequence model with DEQ. We refer to our proposed method as DEQ-based UMX (DEQ-UMX). Experimental results show that DEQ-UMX performs better than the original UMX while reducing its number of parameters by 30%.