 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero- and Few-shot Sound Event Localization and Detection
Paper and Code
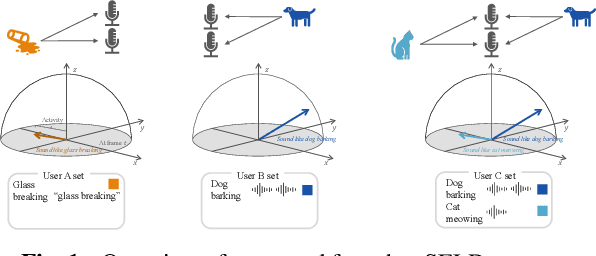



Sound event localization and detection (SELD) systems estimate direction-of-arrival (DOA) and temporal activation for sets of target classes. Neural network (NN)-based SELD systems have performed well in various sets of target classes, but they only output the DOA and temporal activation of preset classes that are trained before inference. To customize target classes after training, we tackle zero- and few-shot SELD tasks, in which we set new classes with a text sample or a few audio samples. While zero-shot sound classification tasks are achievable by embedding from contrastive language-audio pretraining (CLAP), zero-shot SELD tasks require assigning an activity and a DOA to each embedding, especially in overlapping cases. To tackle the assignment problem in overlapping cases, we propose an embed-ACCDOA model, which is trained to output track-wise CLAP embedding and corresponding activity-coupled Cartesian direction-of-arrival (ACCDOA). In our experimental evaluations on zero- and few-shot SELD tasks, the embed-ACCDOA model showed a better location-dependent scores than a straightforward combination of the CLAP audio encoder and a DOA estimation model. Moreover, the proposed combination of the embed-ACCDOA model and CLAP audio encoder with zero- or few-shot samples performed comparably to an official baseline system trained with complete train data in an evaluation dataset.