 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoRefiner: Improving Autoregressive Video Diffusion Models via Reflective Refinement Over the Stochastic Sampling Path
Dec 15, 2025Autoregressive video diffusion models (AR-VDMs) show strong promise as scalable alternatives to bidirectional VDMs, enabling real-time and interactive applications. Yet there remains room for improvement in their sample fidelity. A promising solution is inference-time alignment, which optimizes the noise space to improve sample fidelity without updating model parameters. Yet, optimization- or search-based methods are computationally impractical for AR-VDMs. Recent text-to-image (T2I) works address this via feedforward noise refiners that modulate sampled noises in a single forward pass. Can such noise refiners be extended to AR-VDMs? We identify the failure of naively extending T2I noise refiners to AR-VDMs and propose AutoRefiner-a noise refiner tailored for AR-VDMs, with two key designs: pathwise noise refinement and a reflective KV-cache. Experiments demonstrate that AutoRefiner serves as an efficient plug-in for AR-VDMs, effectively enhancing sample fidelity by refining noise along stochastic denoising paths.
Schrodinger Audio-Visual Editor: Object-Level Audiovisual Removal
Dec 14, 2025Joint editing of audio and visual content is crucial for precise and controllable content creation. This new task poses challenges due to the limitations of paired audio-visual data before and after targeted edits, and the heterogeneity across modalities. To address the data and modeling challenges in joint audio-visual editing, we introduce SAVEBench, a paired audiovisual dataset with text and mask conditions to enable object-grounded source-to-target learning. With SAVEBench, we train the Schrodinger Audio-Visual Editor (SAVE), an end-to-end flow-matching model that edits audio and video in parallel while keeping them aligned throughout processing. SAVE incorporates a Schrodinger Bridge that learns a direct transport from source to target audiovisual mixtures. Our evaluation demonstrates that the proposed SAVE model is able to remove the target objects in audio and visual content while preserving the remaining content, with stronger temporal synchronization and audiovisual semantic correspondence compared with pairwise combinations of an audio editor and a video editor.
Coherent Audio-Visual Editing via Conditional Audio Generation Following Video Edits
Dec 08, 2025We introduce a novel pipeline for joint audio-visual editing that enhances the coherence between edited video and its accompanying audio. Our approach first applies state-of-the-art video editing techniques to produce the target video, then performs audio editing to align with the visual changes. To achieve this, we present a new video-to-audio generation model that conditions on the source audio, target video, and a text prompt. We extend the model architecture to incorporate conditional audio input and propose a data augmentation strategy that improves training efficiency. Furthermore, our model dynamically adjusts the influence of the source audio based on the complexity of the edits, preserving the original audio structure where possible. Experimental results demonstrate that our method outperforms existing approaches in maintaining audio-visual alignment and content integrity.
SONA: Learning Conditional, Unconditional, and Mismatching-Aware Discriminator
Oct 06, 2025Deep generative models have made significant advances in generating complex content, yet conditional generation remains a fundamental challenge. Existing conditional generative adversarial networks often struggle to balance the dual objectives of assessing authenticity and conditional alignment of input samples within their conditional discriminators. To address this, we propose a novel discriminator design that integrates three key capabilities: unconditional discrimination, matching-aware supervision to enhance alignment sensitivity, and adaptive weighting to dynamically balance all objectives. Specifically, we introduce Sum of Naturalness and Alignment (SONA), which employs separate projections for naturalness (authenticity) and alignment in the final layer with an inductive bias, supported by dedicated objective functions and an adaptive weighting mechanism. Extensive experiments on class-conditional generation tasks show that \ours achieves superior sample quality and conditional alignment compared to state-of-the-art methods. Furthermore, we demonstrate its effectiveness in text-to-image generation, confirming the versatility and robustness of our approach.
SoundReactor: Frame-level Online Video-to-Audio Generation
Oct 02, 2025



Prevailing Video-to-Audio (V2A) generation models operate offline, assuming an entire video sequence or chunks of frames are available beforehand. This critically limits their use in interactive applications such as live content creation and emerging generative world models. To address this gap, we introduce the novel task of frame-level online V2A generation, where a model autoregressively generates audio from video without access to future video frames. Furthermore, we propose SoundReactor, which, to the best of our knowledge, is the first simple yet effective framework explicitly tailored for this task. Our design enforces end-to-end causality and targets low per-frame latency with audio-visual synchronization. Our model's backbone is a decoder-only causal transformer over continuous audio latents. For vision conditioning, it leverages grid (patch) features extracted from the smallest variant of the DINOv2 vision encoder, which are aggregated into a single token per frame to maintain end-to-end causality and efficiency. The model is trained through a diffusion pre-training followed by consistency fine-tuning to accelerate the diffusion head decoding. On a benchmark of diverse gameplay videos from AAA titles, our model successfully generates semantically and temporally aligned, high-quality full-band stereo audio, validated by both objective and human evaluations. Furthermore, our model achieves low per-frame waveform-level latency (26.3ms with the head NFE=1, 31.5ms with NFE=4) on 30FPS, 480p videos using a single H100. Demo samples are available at https://koichi-saito-sony.github.io/soundreactor/.
TITAN-Guide: Taming Inference-Time AligNment for Guided Text-to-Video Diffusion Models
Aug 01, 2025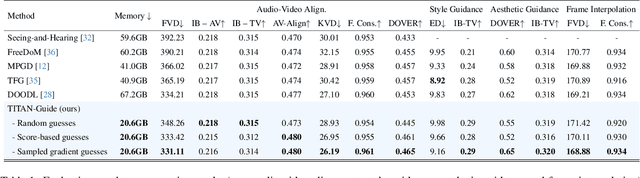



In the recent development of conditional diffusion models still require heavy supervised fine-tuning for performing control on a category of tasks. Training-free conditioning via guidance with off-the-shelf models is a favorable alternative to avoid further fine-tuning on the base model. However, the existing training-free guidance frameworks either have heavy memory requirements or offer sub-optimal control due to rough estimation. These shortcomings limit the applicability to control diffusion models that require intense computation, such as Text-to-Video (T2V) diffusion models. In this work, we propose Taming Inference Time Alignment for Guided Text-to-Video Diffusion Model, so-called TITAN-Guide, which overcomes memory space issues, and provides more optimal control in the guidance process compared to the counterparts. In particular, we develop an efficient method for optimizing diffusion latents without backpropagation from a discriminative guiding model. In particular, we study forward gradient descents for guided diffusion tasks with various options on directional directives. In our experiments, we demonstrate the effectiveness of our approach in efficiently managing memory during latent optimization, while previous methods fall short. Our proposed approach not only minimizes memory requirements but also significantly enhances T2V performance across a range of diffusion guidance benchmarks. Code, models, and demo are available at https://titanguide.github.io.
Step-by-Step Video-to-Audio Synthesis via Negative Audio Guidance
Jun 26, 2025We propose a novel step-by-step video-to-audio generation method that sequentially produces individual audio tracks, each corresponding to a specific sound event in the video. Our approach mirrors traditional Foley workflows, aiming to capture all sound events induced by a given video comprehensively. Each generation step is formulated as a guided video-to-audio synthesis task, conditioned on a target text prompt and previously generated audio tracks. This design is inspired by the idea of concept negation from prior compositional generation frameworks. To enable this guided generation, we introduce a training framework that leverages pre-trained video-to-audio models and eliminates the need for specialized paired datasets, allowing training on more accessible data. Experimental results demonstrate that our method generates multiple semantically distinct audio tracks for a single input video, leading to higher-quality composite audio synthesis than existing baselines.
Vid-CamEdit: Video Camera Trajectory Editing with Generative Rendering from Estimated Geometry
Jun 16, 2025We introduce Vid-CamEdit, a novel framework for video camera trajectory editing, enabling the re-synthesis of monocular videos along user-defined camera paths. This task is challenging due to its ill-posed nature and the limited multi-view video data for training. Traditional reconstruction methods struggle with extreme trajectory changes, and existing generative models for dynamic novel view synthesis cannot handle in-the-wild videos. Our approach consists of two steps: estimating temporally consistent geometry, and generative rendering guided by this geometry. By integrating geometric priors, the generative model focuses on synthesizing realistic details where the estimated geometry is uncertain. We eliminate the need for extensive 4D training data through a factorized fine-tuning framework that separately trains spatial and temporal components using multi-view image and video data. Our method outperforms baselines in producing plausible videos from novel camera trajectories, especially in extreme extrapolation scenarios on real-world footage.
Dyadic Mamba: Long-term Dyadic Human Motion Synthesis
May 14, 2025Generating realistic dyadic human motion from text descriptions presents significant challenges, particularly for extended interactions that exceed typical training sequence lengths. While recent transformer-based approaches have shown promising results for short-term dyadic motion synthesis, they struggle with longer sequences due to inherent limitations in positional encoding schemes. In this paper, we introduce Dyadic Mamba, a novel approach that leverages State-Space Models (SSMs) to generate high-quality dyadic human motion of arbitrary length. Our method employs a simple yet effective architecture that facilitates information flow between individual motion sequences through concatenation, eliminating the need for complex cross-attention mechanisms. We demonstrate that Dyadic Mamba achieves competitive performance on standard short-term benchmarks while significantly outperforming transformer-based approaches on longer sequences. Additionally, we propose a new benchmark for evaluating long-term motion synthesis quality, providing a standardized framework for future research. Our results demonstrate that SSM-based architectures offer a promising direction for addressing the challenging task of long-term dyadic human motion synthesis from text descriptions.
Forging and Removing Latent-Noise Diffusion Watermarks Using a Single Image
Apr 27, 2025Watermarking techniques are vital for protecting intellectual property and preventing fraudulent use of media. Most previous watermarking schemes designed for diffusion models embed a secret key in the initial noise. The resulting pattern is often considered hard to remove and forge into unrelated images. In this paper, we propose a black-box adversarial attack without presuming access to the diffusion model weights. Our attack uses only a single watermarked example and is based on a simple observation: there is a many-to-one mapping between images and initial noises. There are regions in the clean image latent space pertaining to each watermark that get mapped to the same initial noise when inverted. Based on this intuition, we propose an adversarial attack to forge the watermark by introducing perturbations to the images such that we can enter the region of watermarked images. We show that we can also apply a similar approach for watermark removal by learning perturbations to exit this region. We report results on multiple watermarking schemes (Tree-Ring, RingID, WIND, and Gaussian Shading) across two diffusion models (SDv1.4 and SDv2.0). Our results demonstrate the effectiveness of the attack and expose vulnerabilities in the watermarking methods, motivating future research on improving them.