 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCStereo: Audio-Visual Contextual and Contrastive Learning for Binaural Audio Generation
Jan 06, 2025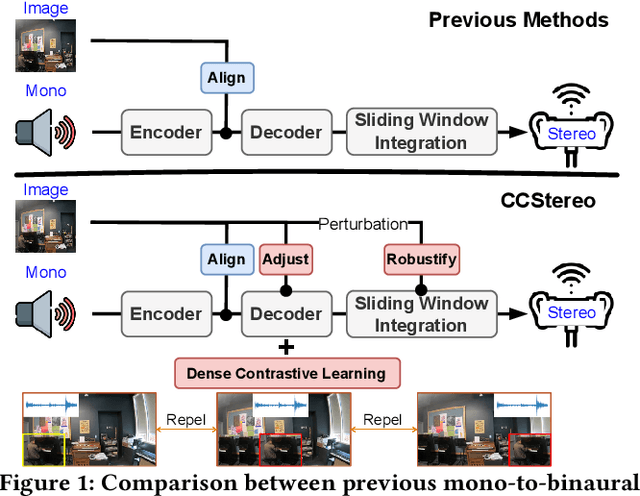
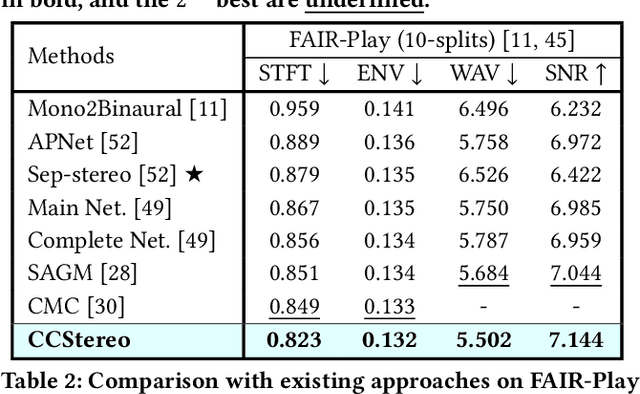
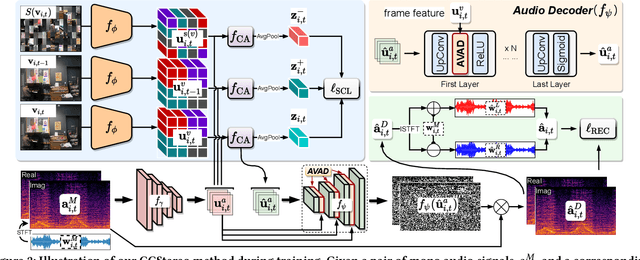
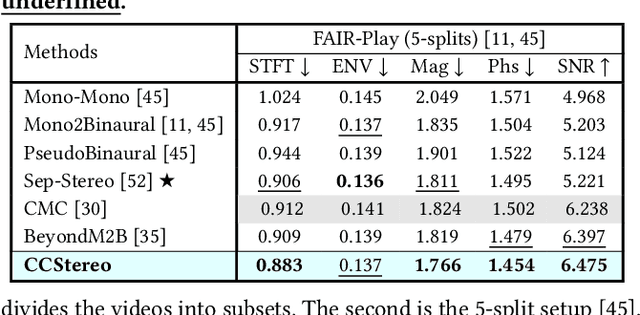
Binaural audio generation (BAG) aims to convert monaural audio to stereo audio using visual prompts, requiring a deep understanding of spatial and semantic information. However, current models risk overfitting to room environments and lose fine-grained spatial details. In this paper, we propose a new audio-visual binaural generation model incorporating an audio-visual conditional normalisation layer that dynamically aligns the mean and variance of the target difference audio features using visual context, along with a new contrastive learning method to enhance spatial sensitivity by mining negative samples from shuffled visual features. We also introduce a cost-efficient way to utilise test-time augmentation in video data to enhance performance. Our approach achieves state-of-the-art generation accuracy on the FAIR-Play and MUSIC-Stereo benchmarks.
Cross- and Intra-image Prototypical Learning for Multi-label Disease Diagnosis and Interpretation
Nov 07, 2024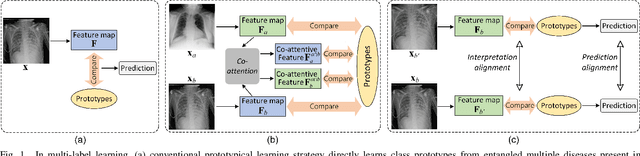
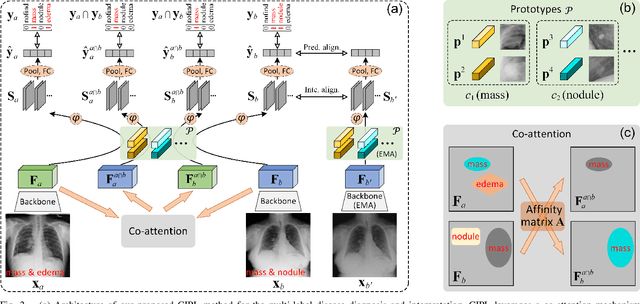
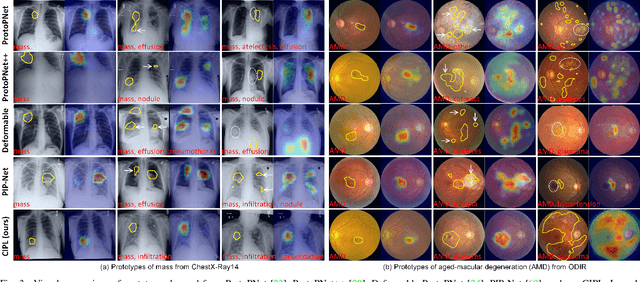
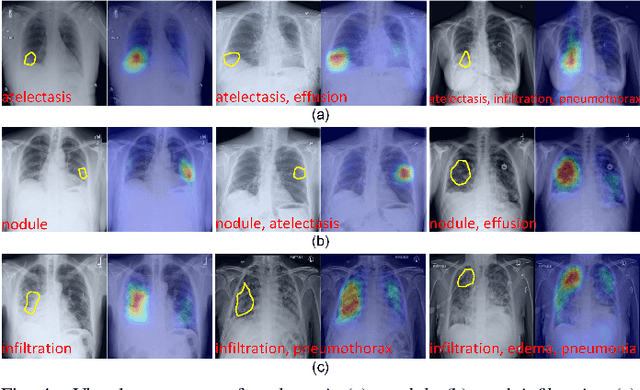
Recent advances in prototypical learning have shown remarkable potential to provide useful decision interpretations associating activation maps and predictions with class-specific training prototypes. Such prototypical learning has been well-studied for various single-label diseases, but for quite relevant and more challenging multi-label diagnosis, where multiple diseases are often concurrent within an image, existing prototypical learning models struggle to obtain meaningful activation maps and effective class prototypes due to the entanglement of the multiple diseases. In this paper, we present a novel Cross- and Intra-image Prototypical Learning (CIPL) framework, for accurate multi-label disease diagnosis and interpretation from medical images. CIPL takes advantage of common cross-image semantics to disentangle the multiple diseases when learning the prototypes, allowing a comprehensive understanding of complicated pathological lesions. Furthermore, we propose a new two-level alignment-based regularisation strategy that effectively leverages consistent intra-image information to enhance interpretation robustness and predictive performance. Extensive experiments show that our CIPL attains the state-of-the-art (SOTA) classification accuracy in two public multi-label benchmarks of disease diagnosis: thoracic radiography and fundus images. Quantitative interpretability results show that CIPL also has superiority in weakly-supervised thoracic disease localisation over other leading saliency- and prototype-based explanation methods.
ItTakesTwo: Leveraging Peer Representations for Semi-supervised LiDAR Semantic Segmentation
Jul 09, 2024



The costly and time-consuming annotation process to produce large training sets for modelling semantic LiDAR segmentation methods has motivated the development of semi-supervised learning (SSL) methods. However, such SSL approaches often concentrate on employing consistency learning only for individual LiDAR representations. This narrow focus results in limited perturbations that generally fail to enable effective consistency learning. Additionally, these SSL approaches employ contrastive learning based on the sampling from a limited set of positive and negative embedding samples. This paper introduces a novel semi-supervised LiDAR semantic segmentation framework called ItTakesTwo (IT2). IT2 is designed to ensure consistent predictions from peer LiDAR representations, thereby improving the perturbation effectiveness in consistency learning. Furthermore, our contrastive learning employs informative samples drawn from a distribution of positive and negative embeddings learned from the entire training set. Results on public benchmarks show that our approach achieves remarkable improvements over the previous state-of-the-art (SOTA) methods in the field. The code is available at: https://github.com/yyliu01/IT2.
CPM: Class-conditional Prompting Machine for Audio-visual Segmentation
Jul 07, 2024



Audio-visual segmentation (AVS) is an emerging task that aims to accurately segment sounding objects based on audio-visual cues. The success of AVS learning systems depends on the effectiveness of cross-modal interaction. Such a requirement can be naturally fulfilled by leveraging transformer-based segmentation architecture due to its inherent ability to capture long-range dependencies and flexibility in handling different modalities. However, the inherent training issues of transformer-based methods, such as the low efficacy of cross-attention and unstable bipartite matching, can be amplified in AVS, particularly when the learned audio query does not provide a clear semantic clue. In this paper, we address these two issues with the new Class-conditional Prompting Machine (CPM). CPM improves the bipartite matching with a learning strategy combining class-agnostic queries with class-conditional queries. The efficacy of cross-modal attention is upgraded with new learning objectives for the audio, visual and joint modalities. We conduct experiments on AVS benchmarks, demonstrating that our method achieves state-of-the-art (SOTA) segmentation accuracy.
Enhancing Multi-modal Learning: Meta-learned Cross-modal Knowledge Distillation for Handling Missing Modalities
May 12, 2024



In multi-modal learning, some modalities are more influential than others, and their absence can have a significant impact on classification/segmentation accuracy. Hence, an important research question is if it is possible for trained multi-modal models to have high accuracy even when influential modalities are absent from the input data. In this paper, we propose a novel approach called Meta-learned Cross-modal Knowledge Distillation (MCKD) to address this research question. MCKD adaptively estimates the importance weight of each modality through a meta-learning process. These dynamically learned modality importance weights are used in a pairwise cross-modal knowledge distillation process to transfer the knowledge from the modalities with higher importance weight to the modalities with lower importance weight. This cross-modal knowledge distillation produces a highly accurate model even with the absence of influential modalities. Differently from previous methods in the field, our approach is designed to work in multiple tasks (e.g., segmentation and classification) with minimal adaptation. Experimental results on the Brain tumor Segmentation Dataset 2018 (BraTS2018) and the Audiovision-MNIST classification dataset demonstrate the superiority of MCKD over current state-of-the-art models. Particularly in BraTS2018, we achieve substantial improvements of 3.51\% for enhancing tumor, 2.19\% for tumor core, and 1.14\% for the whole tumor in terms of average segmentation Dice score.
Mixture of Gaussian-distributed Prototypes with Generative Modelling for Interpretable Image Classification
Nov 30, 2023Prototypical-part interpretable methods, e.g., ProtoPNet, enhance interpretability by connecting classification predictions to class-specific training prototypes, thereby offering an intuitive insight into their decision-making. Current methods rely on a discriminative classifier trained with point-based learning techniques that provide specific values for prototypes. Such prototypes have relatively low representation power due to their sparsity and potential redundancy, with each prototype containing no variability measure. In this paper, we present a new generative learning of prototype distributions, named Mixture of Gaussian-distributed Prototypes (MGProto), which are represented by Gaussian mixture models (GMM). Such an approach enables the learning of more powerful prototype representations since each learned prototype will own a measure of variability, which naturally reduces the sparsity given the spread of the distribution around each prototype, and we also integrate a prototype diversity objective function into the GMM optimisation to reduce redundancy. Incidentally, the generative nature of MGProto offers a new and effective way for detecting out-of-distribution samples. To improve the compactness of MGProto, we further propose to prune Gaussian-distributed prototypes with a low prior. Experiments on CUB-200-2011, Stanford Cars, Stanford Dogs, and Oxford-IIIT Pets datasets show that MGProto achieves state-of-the-art classification and OoD detection performances with encouraging interpretability results.
Learnable Cross-modal Knowledge Distillation for Multi-modal Learning with Missing Modality
Oct 02, 2023The problem of missing modalities is both critical and non-trivial to be handled in multi-modal models. It is common for multi-modal tasks that certain modalities contribute more compared to other modalities, and if those important modalities are missing, the model performance drops significantly. Such fact remains unexplored by current multi-modal approaches that recover the representation from missing modalities by feature reconstruction or blind feature aggregation from other modalities, instead of extracting useful information from the best performing modalities. In this paper, we propose a Learnable Cross-modal Knowledge Distillation (LCKD) model to adaptively identify important modalities and distil knowledge from them to help other modalities from the cross-modal perspective for solving the missing modality issue. Our approach introduces a teacher election procedure to select the most ``qualified'' teachers based on their single modality performance on certain tasks. Then, cross-modal knowledge distillation is performed between teacher and student modalities for each task to push the model parameters to a point that is beneficial for all tasks. Hence, even if the teacher modalities for certain tasks are missing during testing, the available student modalities can accomplish the task well enough based on the learned knowledge from their automatically elected teacher modalities. Experiments on the Brain Tumour Segmentation Dataset 2018 (BraTS2018) shows that LCKD outperforms other methods by a considerable margin, improving the state-of-the-art performance by 3.61% for enhancing tumour, 5.99% for tumour core, and 3.76% for whole tumour in terms of segmentation Dice score.
Generative Noisy-Label Learning by Implicit Dicriminative Approximation with Partial Label Prior
Aug 02, 2023The learning with noisy labels has been addressed with both discriminative and generative models. Although discriminative models have dominated the field due to their simpler modeling and more efficient computational training processes, generative models offer a more effective means of disentangling clean and noisy labels and improving the estimation of the label transition matrix. However, generative approaches maximize the joint likelihood of noisy labels and data using a complex formulation that only indirectly optimizes the model of interest associating data and clean labels. Additionally, these approaches rely on generative models that are challenging to train and tend to use uninformative clean label priors. In this paper, we propose a new generative noisy-label learning approach that addresses these three issues. First, we propose a new model optimisation that directly associates data and clean labels. Second, the generative model is implicitly estimated using a discriminative model, eliminating the inefficient training of a generative model. Third, we propose a new informative label prior inspired by partial label learning as supervision signal for noisy label learning. Extensive experiments on several noisy-label benchmarks demonstrate that our generative model provides state-of-the-art results while maintaining a similar computational complexity as discriminative models.
Multi-modal Learning with Missing Modality via Shared-Specific Feature Modelling
Jul 26, 2023



The missing modality issue is critical but non-trivial to be solved by multi-modal models. Current methods aiming to handle the missing modality problem in multi-modal tasks, either deal with missing modalities only during evaluation or train separate models to handle specific missing modality settings. In addition, these models are designed for specific tasks, so for example, classification models are not easily adapted to segmentation tasks and vice versa. In this paper, we propose the Shared-Specific Feature Modelling (ShaSpec) method that is considerably simpler and more effective than competing approaches that address the issues above. ShaSpec is designed to take advantage of all available input modalities during training and evaluation by learning shared and specific features to better represent the input data. This is achieved from a strategy that relies on auxiliary tasks based on distribution alignment and domain classification, in addition to a residual feature fusion procedure. Also, the design simplicity of ShaSpec enables its easy adaptation to multiple tasks, such as classification and segmentation. Experiments are conducted on both medical image segmentation and computer vision classification, with results indicating that ShaSpec outperforms competing methods by a large margin. For instance, on BraTS2018, ShaSpec improves the SOTA by more than 3% for enhancing tumour, 5% for tumour core and 3% for whole tumour.
A Closer Look at Audio-Visual Semantic Segmentation
Apr 11, 2023Audio-visual segmentation (AVS) is a complex task that involves accurately segmenting the corresponding sounding object based on audio-visual queries. Successful audio-visual learning requires two essential components: 1) an unbiased dataset with high-quality pixel-level multi-class labels, and 2) a model capable of effectively linking audio information with its corresponding visual object. However, these two requirements are only partially addressed by current methods, with training sets containing biased audio-visual data, and models that generalise poorly beyond this biased training set. In this work, we propose a new strategy to build cost-effective and relatively unbiased audio-visual semantic segmentation benchmarks. Our strategy, called Visual Post-production (VPO), explores the observation that it is not necessary to have explicit audio-visual pairs extracted from single video sources to build such benchmarks. We also refine the previously proposed AVSBench to transform it into the audio-visual semantic segmentation benchmark AVSBench-Single+. Furthermore, this paper introduces a new pixel-wise audio-visual contrastive learning method to enable a better generalisation of the model beyond the training set. We verify the validity of the VPO strategy by showing that state-of-the-art (SOTA) models trained with datasets built by matching audio and visual data from different sources or with datasets containing audio and visual data from the same video source produce almost the same accuracy. Then, using the proposed VPO benchmarks and AVSBench-Single+, we show that our method produces more accurate audio-visual semantic segmentation than SOTA models. Code and dataset will be available.