 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCT: Low-Rank Hypernet for Unified Chest CT Analysis
Apr 03, 2026Non-contrast chest CTs offer a rich opportunity for both conventional pulmonary and opportunistic extra-pulmonary screening. While Multi-Task Learning (MTL) can unify these diverse tasks, standard hard-parameter sharing approaches are often suboptimal for modeling distinct pathologies. We propose HyperCT, a framework that dynamically adapts a Vision Transformer backbone via a Hypernetwork. To ensure computational efficiency, we integrate Low-Rank Adaptation (LoRA), allowing the model to regress task-specific low-rank weight updates rather than full parameters. Validated on a large-scale dataset of radiological and cardiological tasks, \method{} outperforms various strong baselines, offering a unified, parameter-efficient solution for holistic patient assessment. Our code is available at https://github.com/lfb-1/HyperCT.
Cross- and Intra-image Prototypical Learning for Multi-label Disease Diagnosis and Interpretation
Nov 07, 2024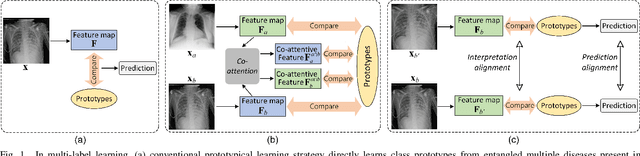
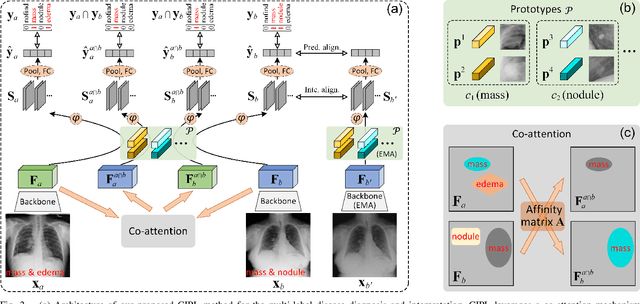
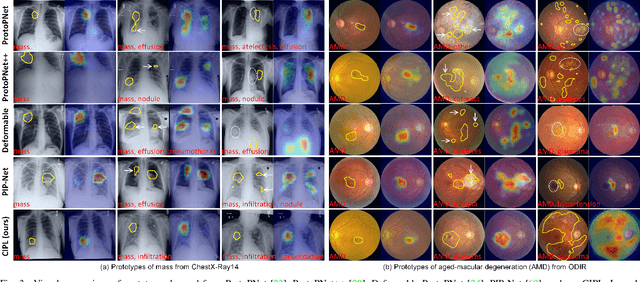
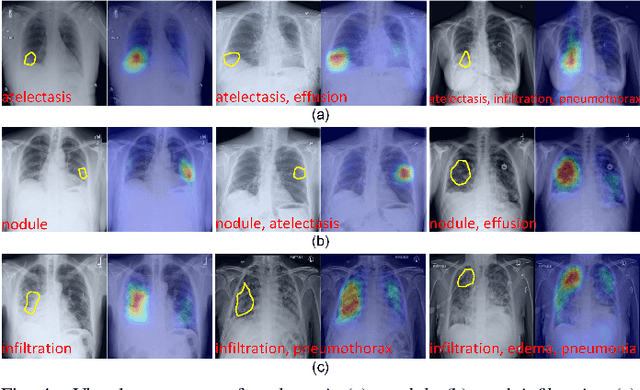
Recent advances in prototypical learning have shown remarkable potential to provide useful decision interpretations associating activation maps and predictions with class-specific training prototypes. Such prototypical learning has been well-studied for various single-label diseases, but for quite relevant and more challenging multi-label diagnosis, where multiple diseases are often concurrent within an image, existing prototypical learning models struggle to obtain meaningful activation maps and effective class prototypes due to the entanglement of the multiple diseases. In this paper, we present a novel Cross- and Intra-image Prototypical Learning (CIPL) framework, for accurate multi-label disease diagnosis and interpretation from medical images. CIPL takes advantage of common cross-image semantics to disentangle the multiple diseases when learning the prototypes, allowing a comprehensive understanding of complicated pathological lesions. Furthermore, we propose a new two-level alignment-based regularisation strategy that effectively leverages consistent intra-image information to enhance interpretation robustness and predictive performance. Extensive experiments show that our CIPL attains the state-of-the-art (SOTA) classification accuracy in two public multi-label benchmarks of disease diagnosis: thoracic radiography and fundus images. Quantitative interpretability results show that CIPL also has superiority in weakly-supervised thoracic disease localisation over other leading saliency- and prototype-based explanation methods.
Effective Segmentation of Post-Treatment Gliomas Using Simple Approaches: Artificial Sequence Generation and Ensemble Models
Sep 12, 2024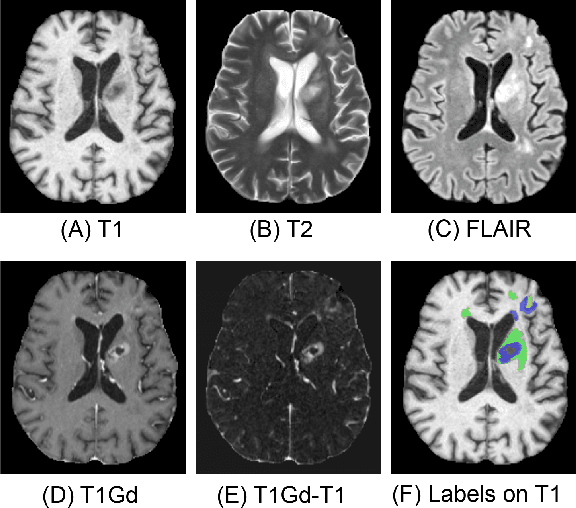
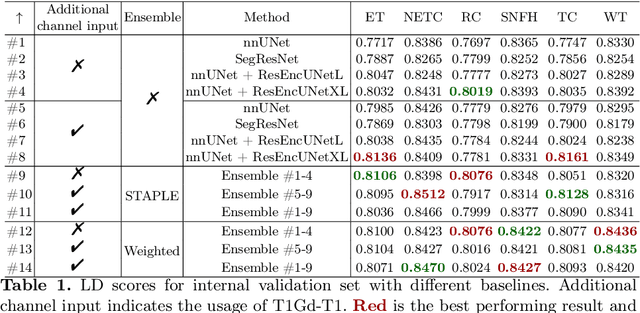
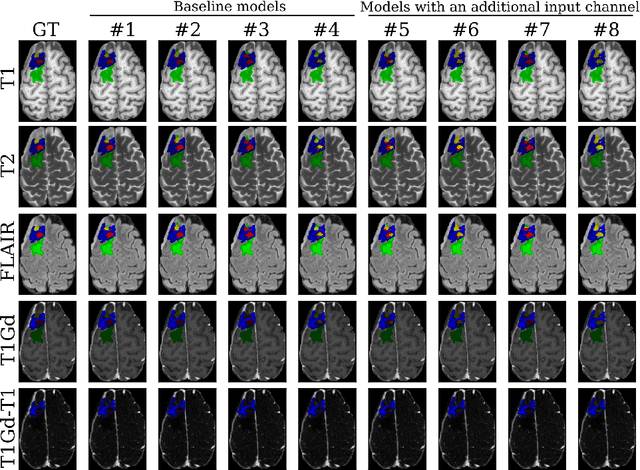
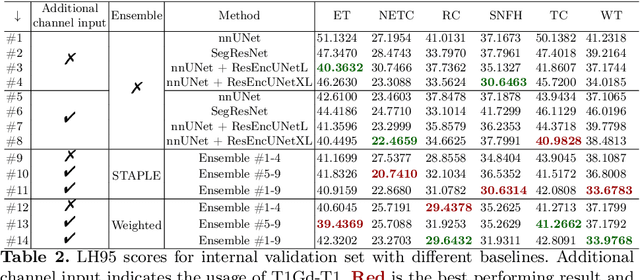
Segmentation is a crucial task in the medical imaging field and is often an important primary step or even a prerequisite to the analysis of medical volumes. Yet treatments such as surgery complicate the accurate delineation of regions of interest. The BraTS Post-Treatment 2024 Challenge published the first public dataset for post-surgery glioma segmentation and addresses the aforementioned issue by fostering the development of automated segmentation tools for glioma in MRI data. In this effort, we propose two straightforward approaches to enhance the segmentation performances of deep learning-based methodologies. First, we incorporate an additional input based on a simple linear combination of the available MRI sequences input, which highlights enhancing tumors. Second, we employ various ensembling methods to weigh the contribution of a battery of models. Our results demonstrate that these approaches significantly improve segmentation performance compared to baseline models, underscoring the effectiveness of these simple approaches in improving medical image segmentation tasks.
Knockout: A simple way to handle missing inputs
Jun 03, 2024

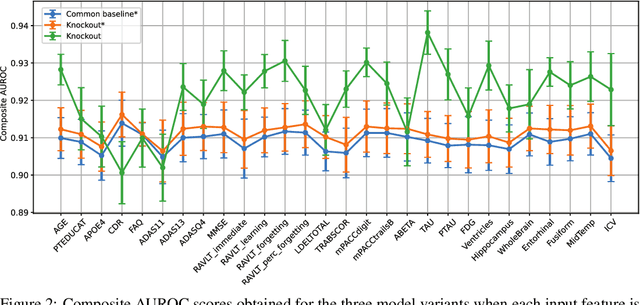

Deep learning models can extract predictive and actionable information from complex inputs. The richer the inputs, the better these models usually perform. However, models that leverage rich inputs (e.g., multi-modality) can be difficult to deploy widely, because some inputs may be missing at inference. Current popular solutions to this problem include marginalization, imputation, and training multiple models. Marginalization can obtain calibrated predictions but it is computationally costly and therefore only feasible for low dimensional inputs. Imputation may result in inaccurate predictions because it employs point estimates for missing variables and does not work well for high dimensional inputs (e.g., images). Training multiple models whereby each model takes different subsets of inputs can work well but requires knowing missing input patterns in advance. Furthermore, training and retaining multiple models can be costly. We propose an efficient way to learn both the conditional distribution using full inputs and the marginal distributions. Our method, Knockout, randomly replaces input features with appropriate placeholder values during training. We provide a theoretical justification of Knockout and show that it can be viewed as an implicit marginalization strategy. We evaluate Knockout in a wide range of simulations and real-world datasets and show that it can offer strong empirical performance.
Mixture of Gaussian-distributed Prototypes with Generative Modelling for Interpretable Image Classification
Nov 30, 2023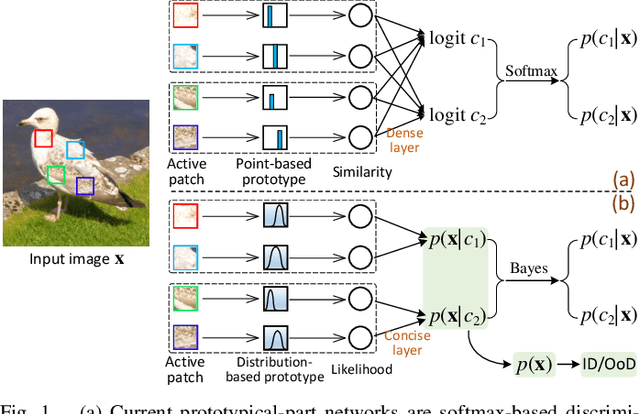
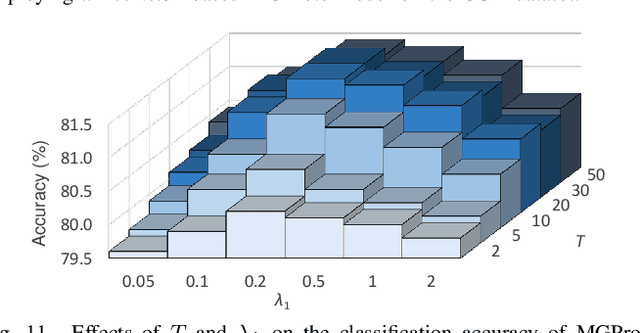
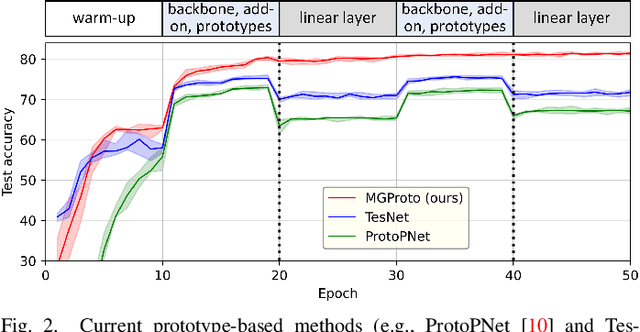
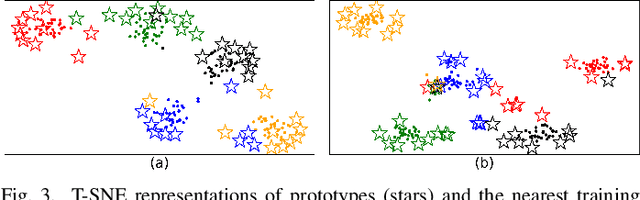
Prototypical-part interpretable methods, e.g., ProtoPNet, enhance interpretability by connecting classification predictions to class-specific training prototypes, thereby offering an intuitive insight into their decision-making. Current methods rely on a discriminative classifier trained with point-based learning techniques that provide specific values for prototypes. Such prototypes have relatively low representation power due to their sparsity and potential redundancy, with each prototype containing no variability measure. In this paper, we present a new generative learning of prototype distributions, named Mixture of Gaussian-distributed Prototypes (MGProto), which are represented by Gaussian mixture models (GMM). Such an approach enables the learning of more powerful prototype representations since each learned prototype will own a measure of variability, which naturally reduces the sparsity given the spread of the distribution around each prototype, and we also integrate a prototype diversity objective function into the GMM optimisation to reduce redundancy. Incidentally, the generative nature of MGProto offers a new and effective way for detecting out-of-distribution samples. To improve the compactness of MGProto, we further propose to prune Gaussian-distributed prototypes with a low prior. Experiments on CUB-200-2011, Stanford Cars, Stanford Dogs, and Oxford-IIIT Pets datasets show that MGProto achieves state-of-the-art classification and OoD detection performances with encouraging interpretability results.
Generative Noisy-Label Learning by Implicit Dicriminative Approximation with Partial Label Prior
Aug 02, 2023The learning with noisy labels has been addressed with both discriminative and generative models. Although discriminative models have dominated the field due to their simpler modeling and more efficient computational training processes, generative models offer a more effective means of disentangling clean and noisy labels and improving the estimation of the label transition matrix. However, generative approaches maximize the joint likelihood of noisy labels and data using a complex formulation that only indirectly optimizes the model of interest associating data and clean labels. Additionally, these approaches rely on generative models that are challenging to train and tend to use uninformative clean label priors. In this paper, we propose a new generative noisy-label learning approach that addresses these three issues. First, we propose a new model optimisation that directly associates data and clean labels. Second, the generative model is implicitly estimated using a discriminative model, eliminating the inefficient training of a generative model. Third, we propose a new informative label prior inspired by partial label learning as supervision signal for noisy label learning. Extensive experiments on several noisy-label benchmarks demonstrate that our generative model provides state-of-the-art results while maintaining a similar computational complexity as discriminative models.
A Closer Look at Audio-Visual Semantic Segmentation
Apr 11, 2023Audio-visual segmentation (AVS) is a complex task that involves accurately segmenting the corresponding sounding object based on audio-visual queries. Successful audio-visual learning requires two essential components: 1) an unbiased dataset with high-quality pixel-level multi-class labels, and 2) a model capable of effectively linking audio information with its corresponding visual object. However, these two requirements are only partially addressed by current methods, with training sets containing biased audio-visual data, and models that generalise poorly beyond this biased training set. In this work, we propose a new strategy to build cost-effective and relatively unbiased audio-visual semantic segmentation benchmarks. Our strategy, called Visual Post-production (VPO), explores the observation that it is not necessary to have explicit audio-visual pairs extracted from single video sources to build such benchmarks. We also refine the previously proposed AVSBench to transform it into the audio-visual semantic segmentation benchmark AVSBench-Single+. Furthermore, this paper introduces a new pixel-wise audio-visual contrastive learning method to enable a better generalisation of the model beyond the training set. We verify the validity of the VPO strategy by showing that state-of-the-art (SOTA) models trained with datasets built by matching audio and visual data from different sources or with datasets containing audio and visual data from the same video source produce almost the same accuracy. Then, using the proposed VPO benchmarks and AVSBench-Single+, we show that our method produces more accurate audio-visual semantic segmentation than SOTA models. Code and dataset will be available.
BRAIxDet: Learning to Detect Malignant Breast Lesion with Incomplete Annotations
Feb 02, 2023



Methods to detect malignant lesions from screening mammograms are usually trained with fully annotated datasets, where images are labelled with the localisation and classification of cancerous lesions. However, real-world screening mammogram datasets commonly have a subset that is fully annotated and another subset that is weakly annotated with just the global classification (i.e., without lesion localisation). Given the large size of such datasets, researchers usually face a dilemma with the weakly annotated subset: to not use it or to fully annotate it. The first option will reduce detection accuracy because it does not use the whole dataset, and the second option is too expensive given that the annotation needs to be done by expert radiologists. In this paper, we propose a middle-ground solution for the dilemma, which is to formulate the training as a weakly- and semi-supervised learning problem that we refer to as malignant breast lesion detection with incomplete annotations. To address this problem, our new method comprises two stages, namely: 1) pre-training a multi-view mammogram classifier with weak supervision from the whole dataset, and 2) extending the trained classifier to become a multi-view detector that is trained with semi-supervised student-teacher learning, where the training set contains fully and weakly-annotated mammograms. We provide extensive detection results on two real-world screening mammogram datasets containing incomplete annotations, and show that our proposed approach achieves state-of-the-art results in the detection of malignant breast lesions with incomplete annotations.
Learning Support and Trivial Prototypes for Interpretable Image Classification
Jan 08, 2023



Prototypical part network (ProtoPNet) methods have been designed to achieve interpretable classification by associating predictions with a set of training prototypes, which we refer to as trivial (i.e., easy-to-learn) prototypes because they are trained to lie far from the classification boundary in the feature space. Note that it is possible to make an analogy between ProtoPNet and support vector machine (SVM) given that the classification from both methods relies on computing similarity with a set of training points (i.e., trivial prototypes in ProtoPNet, and support vectors in SVM). However, while trivial prototypes are located far from the classification boundary, support vectors are located close to this boundary, and we argue that this discrepancy with the well-established SVM theory can result in ProtoPNet models with suboptimal classification accuracy. In this paper, we aim to improve the classification accuracy of ProtoPNet with a new method to learn support prototypes that lie near the classification boundary in the feature space, as suggested by the SVM theory. In addition, we target the improvement of classification interpretability with a new model, named ST-ProtoPNet, which exploits our support prototypes and the trivial prototypes to provide complementary interpretability information. Experimental results on CUB-200-2011, Stanford Cars, and Stanford Dogs datasets demonstrate that the proposed method achieves state-of-the-art classification accuracy and produces more visually meaningful and diverse prototypes.
Asymmetric Co-teaching with Multi-view Consensus for Noisy Label Learning
Jan 01, 2023



Learning with noisy-labels has become an important research topic in computer vision where state-of-the-art (SOTA) methods explore: 1) prediction disagreement with co-teaching strategy that updates two models when they disagree on the prediction of training samples; and 2) sample selection to divide the training set into clean and noisy sets based on small training loss. However, the quick convergence of co-teaching models to select the same clean subsets combined with relatively fast overfitting of noisy labels may induce the wrong selection of noisy label samples as clean, leading to an inevitable confirmation bias that damages accuracy. In this paper, we introduce our noisy-label learning approach, called Asymmetric Co-teaching (AsyCo), which introduces novel prediction disagreement that produces more consistent divergent results of the co-teaching models, and a new sample selection approach that does not require small-loss assumption to enable a better robustness to confirmation bias than previous methods. More specifically, the new prediction disagreement is achieved with the use of different training strategies, where one model is trained with multi-class learning and the other with multi-label learning. Also, the new sample selection is based on multi-view consensus, which uses the label views from training labels and model predictions to divide the training set into clean and noisy for training the multi-class model and to re-label the training samples with multiple top-ranked labels for training the multi-label model. Extensive experiments on synthetic and real-world noisy-label datasets show that AsyCo improves over current SOTA methods.