 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Autoregressive Modelling for Monocular Depth Estimation
Dec 27, 2025We propose a monocular depth estimation method based on visual autoregressive (VAR) priors, offering an alternative to diffusion-based approaches. Our method adapts a large-scale text-to-image VAR model and introduces a scale-wise conditional upsampling mechanism with classifier-free guidance. Our approach performs inference in ten fixed autoregressive stages, requiring only 74K synthetic samples for fine-tuning, and achieves competitive results. We report state-of-the-art performance in indoor benchmarks under constrained training conditions, and strong performance when applied to outdoor datasets. This work establishes autoregressive priors as a complementary family of geometry-aware generative models for depth estimation, highlighting advantages in data scalability, and adaptability to 3D vision tasks. Code available at "https://github.com/AmirMaEl/VAR-Depth".
Evaluating Multiple Instance Learning Strategies for Automated Sebocyte Droplet Counting
Sep 05, 2025


Sebocytes are lipid-secreting cells whose differentiation is marked by the accumulation of intracellular lipid droplets, making their quantification a key readout in sebocyte biology. Manual counting is labor-intensive and subjective, motivating automated solutions. Here, we introduce a simple attention-based multiple instance learning (MIL) framework for sebocyte image analysis. Nile Red-stained sebocyte images were annotated into 14 classes according to droplet counts, expanded via data augmentation to about 50,000 cells. Two models were benchmarked: a baseline multi-layer perceptron (MLP) trained on aggregated patch-level counts, and an attention-based MIL model leveraging ResNet-50 features with instance weighting. Experiments using five-fold cross-validation showed that the baseline MLP achieved more stable performance (mean MAE = 5.6) compared with the attention-based MIL, which was less consistent (mean MAE = 10.7) but occasionally superior in specific folds. These findings indicate that simple bag-level aggregation provides a robust baseline for slide-level droplet counting, while attention-based MIL requires task-aligned pooling and regularization to fully realize its potential in sebocyte image analysis.
TransPrune: Token Transition Pruning for Efficient Large Vision-Language Model
Jul 28, 2025Large Vision-Language Models (LVLMs) have advanced multimodal learning but face high computational costs due to the large number of visual tokens, motivating token pruning to improve inference efficiency. The key challenge lies in identifying which tokens are truly important. Most existing approaches rely on attention-based criteria to estimate token importance. However, they inherently suffer from certain limitations, such as positional bias. In this work, we explore a new perspective on token importance based on token transitions in LVLMs. We observe that the transition of token representations provides a meaningful signal of semantic information. Based on this insight, we propose TransPrune, a training-free and efficient token pruning method. Specifically, TransPrune progressively prunes tokens by assessing their importance through a combination of Token Transition Variation (TTV)-which measures changes in both the magnitude and direction of token representations-and Instruction-Guided Attention (IGA), which measures how strongly the instruction attends to image tokens via attention. Extensive experiments demonstrate that TransPrune achieves comparable multimodal performance to original LVLMs, such as LLaVA-v1.5 and LLaVA-Next, across eight benchmarks, while reducing inference TFLOPs by more than half. Moreover, TTV alone can serve as an effective criterion without relying on attention, achieving performance comparable to attention-based methods. The code will be made publicly available upon acceptance of the paper at https://github.com/liaolea/TransPrune.
Risk Estimation of Knee Osteoarthritis Progression via Predictive Multi-task Modelling from Efficient Diffusion Model using X-ray Images
Jun 17, 2025Medical imaging plays a crucial role in assessing knee osteoarthritis (OA) risk by enabling early detection and disease monitoring. Recent machine learning methods have improved risk estimation (i.e., predicting the likelihood of disease progression) and predictive modelling (i.e., the forecasting of future outcomes based on current data) using medical images, but clinical adoption remains limited due to their lack of interpretability. Existing approaches that generate future images for risk estimation are complex and impractical. Additionally, previous methods fail to localize anatomical knee landmarks, limiting interpretability. We address these gaps with a new interpretable machine learning method to estimate the risk of knee OA progression via multi-task predictive modelling that classifies future knee OA severity and predicts anatomical knee landmarks from efficiently generated high-quality future images. Such image generation is achieved by leveraging a diffusion model in a class-conditioned latent space to forecast disease progression, offering a visual representation of how particular health conditions may evolve. Applied to the Osteoarthritis Initiative dataset, our approach improves the state-of-the-art (SOTA) by 2\%, achieving an AUC of 0.71 in predicting knee OA progression while offering ~9% faster inference time.
CLOC: Contrastive Learning for Ordinal Classification with Multi-Margin N-pair Loss
Apr 22, 2025In ordinal classification, misclassifying neighboring ranks is common, yet the consequences of these errors are not the same. For example, misclassifying benign tumor categories is less consequential, compared to an error at the pre-cancerous to cancerous threshold, which could profoundly influence treatment choices. Despite this, existing ordinal classification methods do not account for the varying importance of these margins, treating all neighboring classes as equally significant. To address this limitation, we propose CLOC, a new margin-based contrastive learning method for ordinal classification that learns an ordered representation based on the optimization of multiple margins with a novel multi-margin n-pair loss (MMNP). CLOC enables flexible decision boundaries across key adjacent categories, facilitating smooth transitions between classes and reducing the risk of overfitting to biases present in the training data. We provide empirical discussion regarding the properties of MMNP and show experimental results on five real-world image datasets (Adience, Historical Colour Image Dating, Knee Osteoarthritis, Indian Diabetic Retinopathy Image, and Breast Carcinoma Subtyping) and one synthetic dataset simulating clinical decision bias. Our results demonstrate that CLOC outperforms existing ordinal classification methods and show the interpretability and controllability of CLOC in learning meaningful, ordered representations that align with clinical and practical needs.
AI-Powered Prediction of Nanoparticle Pharmacokinetics: A Multi-View Learning Approach
Mar 18, 2025The clinical translation of nanoparticle-based treatments remains limited due to the unpredictability of (nanoparticle) NP pharmacokinetics$\unicode{x2014}$how they distribute, accumulate, and clear from the body. Predicting these behaviours is challenging due to complex biological interactions and the difficulty of obtaining high-quality experimental datasets. Existing AI-driven approaches rely heavily on data-driven learning but fail to integrate crucial knowledge about NP properties and biodistribution mechanisms. We introduce a multi-view deep learning framework that enhances pharmacokinetic predictions by incorporating prior knowledge of key NP properties such as size and charge into a cross-attention mechanism, enabling context-aware feature selection and improving generalization despite small datasets. To further enhance prediction robustness, we employ an ensemble learning approach, combining deep learning with XGBoost (XGB) and Random Forest (RF), which significantly outperforms existing AI models. Our interpretability analysis reveals key physicochemical properties driving NP biodistribution, providing biologically meaningful insights into possible mechanisms governing NP behaviour in vivo rather than a black-box model. Furthermore, by bridging machine learning with physiologically based pharmacokinetic (PBPK) modelling, this work lays the foundation for data-efficient AI-driven drug discovery and precision nanomedicine.
Set a Thief to Catch a Thief: Combating Label Noise through Noisy Meta Learning
Feb 22, 2025Learning from noisy labels (LNL) aims to train high-performance deep models using noisy datasets. Meta learning based label correction methods have demonstrated remarkable performance in LNL by designing various meta label rectification tasks. However, extra clean validation set is a prerequisite for these methods to perform label correction, requiring extra labor and greatly limiting their practicality. To tackle this issue, we propose a novel noisy meta label correction framework STCT, which counterintuitively uses noisy data to correct label noise, borrowing the spirit in the saying ``Set a Thief to Catch a Thief''. The core idea of STCT is to leverage noisy data which is i.i.d. with the training data as a validation set to evaluate model performance and perform label correction in a meta learning framework, eliminating the need for extra clean data. By decoupling the complex bi-level optimization in meta learning into representation learning and label correction, STCT is solved through an alternating training strategy between noisy meta correction and semi-supervised representation learning. Extensive experiments on synthetic and real-world datasets demonstrate the outstanding performance of STCT, particularly in high noise rate scenarios. STCT achieves 96.9% label correction and 95.2% classification performance on CIFAR-10 with 80% symmetric noise, significantly surpassing the current state-of-the-art.
Leveraging Labelled Data Knowledge: A Cooperative Rectification Learning Network for Semi-supervised 3D Medical Image Segmentation
Feb 17, 2025Semi-supervised 3D medical image segmentation aims to achieve accurate segmentation using few labelled data and numerous unlabelled data. The main challenge in the design of semi-supervised learning methods consists in the effective use of the unlabelled data for training. A promising solution consists of ensuring consistent predictions across different views of the data, where the efficacy of this strategy depends on the accuracy of the pseudo-labels generated by the model for this consistency learning strategy. In this paper, we introduce a new methodology to produce high-quality pseudo-labels for a consistency learning strategy to address semi-supervised 3D medical image segmentation. The methodology has three important contributions. The first contribution is the Cooperative Rectification Learning Network (CRLN) that learns multiple prototypes per class to be used as external knowledge priors to adaptively rectify pseudo-labels at the voxel level. The second contribution consists of the Dynamic Interaction Module (DIM) to facilitate pairwise and cross-class interactions between prototypes and multi-resolution image features, enabling the production of accurate voxel-level clues for pseudo-label rectification. The third contribution is the Cooperative Positive Supervision (CPS), which optimises uncertain representations to align with unassertive representations of their class distributions, improving the model's accuracy in classifying uncertain regions. Extensive experiments on three public 3D medical segmentation datasets demonstrate the effectiveness and superiority of our semi-supervised learning method.
Coverage-Constrained Human-AI Cooperation with Multiple Experts
Nov 18, 2024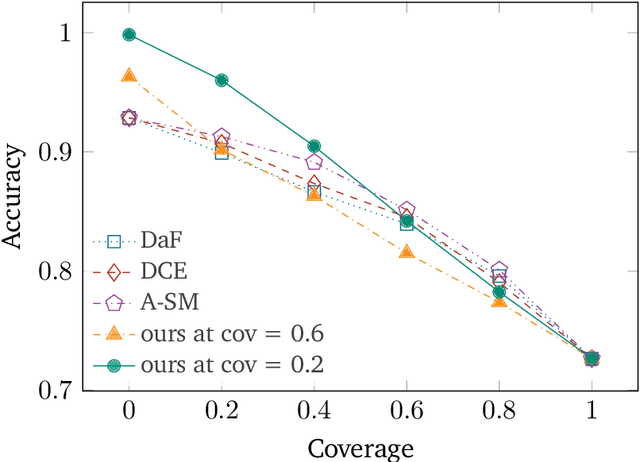

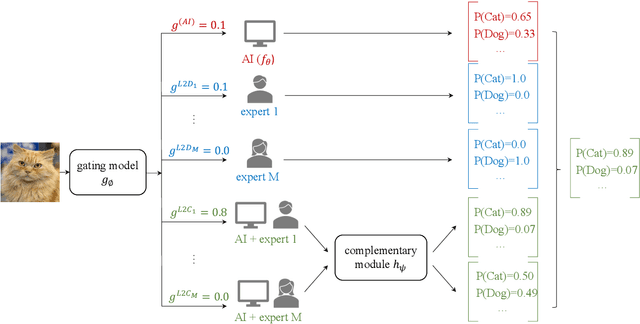
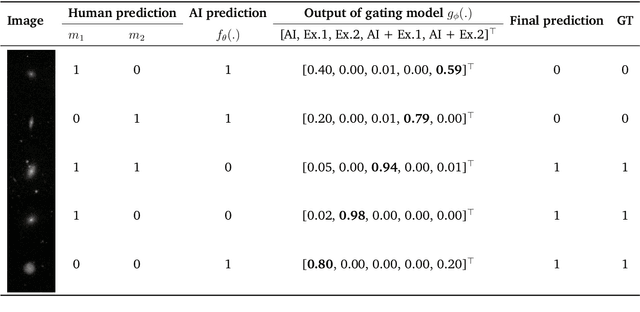
Human-AI cooperative classification (HAI-CC) approaches aim to develop hybrid intelligent systems that enhance decision-making in various high-stakes real-world scenarios by leveraging both human expertise and AI capabilities. Current HAI-CC methods primarily focus on learning-to-defer (L2D), where decisions are deferred to human experts, and learning-to-complement (L2C), where AI and human experts make predictions cooperatively. However, a notable research gap remains in effectively exploring both L2D and L2C under diverse expert knowledge to improve decision-making, particularly when constrained by the cooperation cost required to achieve a target probability for AI-only selection (i.e., coverage). In this paper, we address this research gap by proposing the Coverage-constrained Learning to Defer and Complement with Specific Experts (CL2DC) method. CL2DC makes final decisions through either AI prediction alone or by deferring to or complementing a specific expert, depending on the input data. Furthermore, we propose a coverage-constrained optimisation to control the cooperation cost, ensuring it approximates a target probability for AI-only selection. This approach enables an effective assessment of system performance within a specified budget. Also, CL2DC is designed to address scenarios where training sets contain multiple noisy-label annotations without any clean-label references. Comprehensive evaluations on both synthetic and real-world datasets demonstrate that CL2DC achieves superior performance compared to state-of-the-art HAI-CC methods.
Fair Distillation: Teaching Fairness from Biased Teachers in Medical Imaging
Nov 18, 2024



Deep learning has achieved remarkable success in image classification and segmentation tasks. However, fairness concerns persist, as models often exhibit biases that disproportionately affect demographic groups defined by sensitive attributes such as race, gender, or age. Existing bias-mitigation techniques, including Subgroup Re-balancing, Adversarial Training, and Domain Generalization, aim to balance accuracy across demographic groups, but often fail to simultaneously improve overall accuracy, group-specific accuracy, and fairness due to conflicts among these interdependent objectives. We propose the Fair Distillation (FairDi) method, a novel fairness approach that decomposes these objectives by leveraging biased ``teacher'' models, each optimized for a specific demographic group. These teacher models then guide the training of a unified ``student'' model, which distills their knowledge to maximize overall and group-specific accuracies, while minimizing inter-group disparities. Experiments on medical imaging datasets show that FairDi achieves significant gains in both overall and group-specific accuracy, along with improved fairness, compared to existing methods. FairDi is adaptable to various medical tasks, such as classification and segmentation, and provides an effective solution for equitable model performance.