 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGRAG: Distributed Graph-based Retrieval-Augmented Generation in Edge-Cloud Systems
May 26, 2025Retrieval-Augmented Generation (RAG) has emerged as a promising approach to enhance the capabilities of language models by integrating external knowledge. Due to the diversity of data sources and the constraints of memory and computing resources, real-world data is often scattered in multiple devices. Conventional RAGs that store massive amounts of scattered data centrally face increasing privacy concerns and high computational costs. Additionally, RAG in a central node raises latency issues when searching over a large-scale knowledge base. To address these challenges, we propose a distributed Knowledge Graph-based RAG approach, referred to as DGRAG, in an edge-cloud system, where each edge device maintains a local knowledge base without the need to share it with the cloud, instead sharing only summaries of its knowledge. Specifically, DGRAG has two main phases. In the Distributed Knowledge Construction phase, DGRAG organizes local knowledge using knowledge graphs, generating subgraph summaries and storing them in a summary database in the cloud as information sharing. In the Collaborative Retrieval and Generation phase, DGRAG first performs knowledge retrieval and answer generation locally, and a gate mechanism determines whether the query is beyond the scope of local knowledge or processing capabilities. For queries that exceed the local knowledge scope, the cloud retrieves knowledge from the most relevant edges based on the summaries and generates a more precise answer. Experimental results demonstrate the effectiveness of the proposed DGRAG approach in significantly improving the quality of question-answering tasks over baseline approaches.
Empowering Agentic Video Analytics Systems with Video Language Models
May 02, 2025

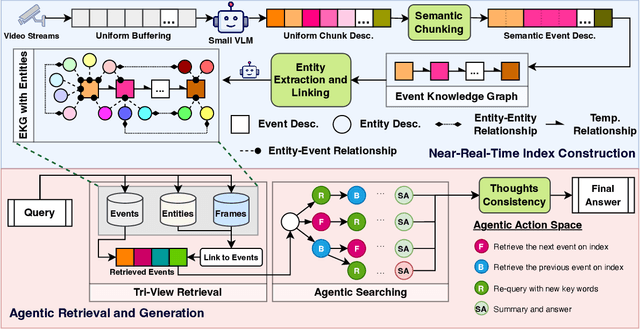
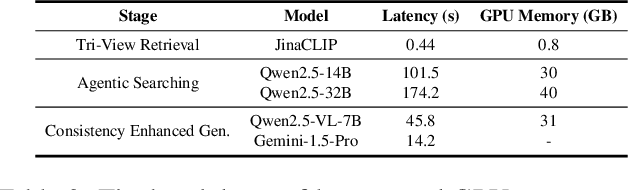
AI-driven video analytics has become increasingly pivotal across diverse domains. However, existing systems are often constrained to specific, predefined tasks, limiting their adaptability in open-ended analytical scenarios. The recent emergence of Video-Language Models (VLMs) as transformative technologies offers significant potential for enabling open-ended video understanding, reasoning, and analytics. Nevertheless, their limited context windows present challenges when processing ultra-long video content, which is prevalent in real-world applications. To address this, we introduce AVAS, a VLM-powered system designed for open-ended, advanced video analytics. AVAS incorporates two key innovations: (1) the near real-time construction of Event Knowledge Graphs (EKGs) for efficient indexing of long or continuous video streams, and (2) an agentic retrieval-generation mechanism that leverages EKGs to handle complex and diverse queries. Comprehensive evaluations on public benchmarks, LVBench and VideoMME-Long, demonstrate that AVAS achieves state-of-the-art performance, attaining 62.3% and 64.1% accuracy, respectively, significantly surpassing existing VLM and video Retrieval-Augmented Generation (RAG) systems. Furthermore, to evaluate video analytics in ultra-long and open-world video scenarios, we introduce a new benchmark, AVAS-100. This benchmark comprises 8 videos, each exceeding 10 hours in duration, along with 120 manually annotated, diverse, and complex question-answer pairs. On AVAS-100, AVAS achieves top-tier performance with an accuracy of 75.8%.
Graph Probability Aggregation Clustering
Feb 27, 2025Traditional clustering methods typically focus on either cluster-wise global clustering or point-wise local clustering to reveal the intrinsic structures in unlabeled data. Global clustering optimizes an objective function to explore the relationships between clusters, but this approach may inevitably lead to coarse partition. In contrast, local clustering heuristically groups data based on detailed point relationships, but it tends to be less coherence and efficient. To bridge the gap between these two concepts and utilize the strengths of both, we propose Graph Probability Aggregation Clustering (GPAC), a graph-based fuzzy clustering algorithm. GPAC unifies the global clustering objective function with a local clustering constraint. The entire GPAC framework is formulated as a multi-constrained optimization problem, which can be solved using the Lagrangian method. Through the optimization process, the probability of a sample belonging to a specific cluster is iteratively calculated by aggregating information from neighboring samples within the graph. We incorporate a hard assignment variable into the objective function to further improve the convergence and stability of optimization. Furthermore, to efficiently handle large-scale datasets, we introduce an acceleration program that reduces the computational complexity from quadratic to linear, ensuring scalability. Extensive experiments conducted on synthetic, real-world, and deep learning datasets demonstrate that GPAC not only exceeds existing state-of-the-art methods in clustering performance but also excels in computational efficiency, making it a powerful tool for complex clustering challenges.
Set a Thief to Catch a Thief: Combating Label Noise through Noisy Meta Learning
Feb 22, 2025Learning from noisy labels (LNL) aims to train high-performance deep models using noisy datasets. Meta learning based label correction methods have demonstrated remarkable performance in LNL by designing various meta label rectification tasks. However, extra clean validation set is a prerequisite for these methods to perform label correction, requiring extra labor and greatly limiting their practicality. To tackle this issue, we propose a novel noisy meta label correction framework STCT, which counterintuitively uses noisy data to correct label noise, borrowing the spirit in the saying ``Set a Thief to Catch a Thief''. The core idea of STCT is to leverage noisy data which is i.i.d. with the training data as a validation set to evaluate model performance and perform label correction in a meta learning framework, eliminating the need for extra clean data. By decoupling the complex bi-level optimization in meta learning into representation learning and label correction, STCT is solved through an alternating training strategy between noisy meta correction and semi-supervised representation learning. Extensive experiments on synthetic and real-world datasets demonstrate the outstanding performance of STCT, particularly in high noise rate scenarios. STCT achieves 96.9% label correction and 95.2% classification performance on CIFAR-10 with 80% symmetric noise, significantly surpassing the current state-of-the-art.
Retrieval-augmented Generation for GenAI-enabled Semantic Communications
Dec 27, 2024



Semantic communication (SemCom) is an emerging paradigm aiming at transmitting only task-relevant semantic information to the receiver, which can significantly improve communication efficiency. Recent advancements in generative artificial intelligence (GenAI) have empowered GenAI-enabled SemCom (GenSemCom) to further expand its potential in various applications. However, current GenSemCom systems still face challenges such as semantic inconsistency, limited adaptability to diverse tasks and dynamic environments, and the inability to leverage insights from past transmission. Motivated by the success of retrieval-augmented generation (RAG) in the domain of GenAI, this paper explores the integration of RAG in GenSemCom systems. Specifically, we first provide a comprehensive review of existing GenSemCom systems and the fundamentals of RAG techniques. We then discuss how RAG can be integrated into GenSemCom. Following this, we conduct a case study on semantic image transmission using an RAG-enabled diffusion-based SemCom system, demonstrating the effectiveness of the proposed integration. Finally, we outline future directions for advancing RAG-enabled GenSemCom systems.
Deep Probability Aggregation Clustering
Jul 07, 2024Combining machine clustering with deep models has shown remarkable superiority in deep clustering. It modifies the data processing pipeline into two alternating phases: feature clustering and model training. However, such alternating schedule may lead to instability and computational burden issues. We propose a centerless clustering algorithm called Probability Aggregation Clustering (PAC) to proactively adapt deep learning technologies, enabling easy deployment in online deep clustering. PAC circumvents the cluster center and aligns the probability space and distribution space by formulating clustering as an optimization problem with a novel objective function. Based on the computation mechanism of the PAC, we propose a general online probability aggregation module to perform stable and flexible feature clustering over mini-batch data and further construct a deep visual clustering framework deep PAC (DPAC). Extensive experiments demonstrate that PAC has superior clustering robustness and performance and DPAC remarkably outperforms the state-of-the-art deep clustering methods.
FeDeRA:Efficient Fine-tuning of Language Models in Federated Learning Leveraging Weight Decomposition
Apr 30, 2024Pre-trained Language Models (PLMs) have shown excellent performance on various downstream tasks after fine-tuning. Nevertheless, the escalating concerns surrounding user privacy have posed significant challenges to centralized training reliant on extensive data collection. Federated learning, which only requires training on the clients and aggregates weights on the server without sharing data, has emerged as a solution. However, the substantial parameter size of PLMs places a significant burden on the computational resources of client devices, while also leading to costly communication expenses. Introducing Parameter-Efficient Fine-Tuning(PEFT) into federated learning can effectively address this problem. However, we observe that the non-IID data in federated learning leads to a gap in performance between the PEFT method and full parameter fine-tuning(FFT). To overcome this, we propose FeDeRA, an improvement over the Low-Rank Adaption(LoRA) method in federated learning. FeDeRA uses the same adapter module as LoRA. However, the difference lies in FeDeRA's initialization of the adapter module by performing Singular Value Decomposition (SVD) on the pre-trained matrix and selecting its principal components. We conducted extensive experiments, using RoBERTa and DeBERTaV3, on six datasets, comparing the methods including FFT and the other three different PEFT methods. FeDeRA outperforms all other PEFT methods and is comparable to or even surpasses the performance of FFT method. We also deployed federated learning on Jetson AGX Orin and compared the time required by different methods to achieve the target accuracy on specific tasks. Compared to FFT, FeDeRA reduces the training time by 95.9\%, 97.9\%, 96.9\% and 97.3\%, 96.5\%, 96.5\% respectively on three tasks using RoBERTa and DeBERTaV3. The overall experiments indicate that FeDeRA achieves good performance while also maintaining efficiency.
FaceStudio: Put Your Face Everywhere in Seconds
Dec 06, 2023This study investigates identity-preserving image synthesis, an intriguing task in image generation that seeks to maintain a subject's identity while adding a personalized, stylistic touch. Traditional methods, such as Textual Inversion and DreamBooth, have made strides in custom image creation, but they come with significant drawbacks. These include the need for extensive resources and time for fine-tuning, as well as the requirement for multiple reference images. To overcome these challenges, our research introduces a novel approach to identity-preserving synthesis, with a particular focus on human images. Our model leverages a direct feed-forward mechanism, circumventing the need for intensive fine-tuning, thereby facilitating quick and efficient image generation. Central to our innovation is a hybrid guidance framework, which combines stylized images, facial images, and textual prompts to guide the image generation process. This unique combination enables our model to produce a variety of applications, such as artistic portraits and identity-blended images. Our experimental results, including both qualitative and quantitative evaluations, demonstrate the superiority of our method over existing baseline models and previous works, particularly in its remarkable efficiency and ability to preserve the subject's identity with high fidelity.
Confidant: Customizing Transformer-based LLMs via Collaborative Edge Training
Nov 22, 2023Transformer-based large language models (LLMs) have demonstrated impressive capabilities in a variety of natural language processing (NLP) tasks. Nonetheless, it is challenging to deploy and fine-tune LLMs on mobile edge devices with limited computing, memory, and energy budgets. In this paper, we propose Confidant, a multi-backend collaborative training framework for customizing state-of-the-art LLMs on commodity mobile devices like smartphones. Confidant partitions an LLM into several sub-models so that each fits into a mobile device's memory. A pipeline parallel training mechanism is further developed to ensure fast and efficient distributed training. In addition, we propose a novel backend scheduler to allocate different attention heads to heterogeneous compute hardware, including mobile CPU and GPUs, to maximize the compute resource utilization on each edge device. Our preliminary experimental results show that Confidant achieves at most 45.3% memory reduction and 8.03x inference speedup in practical settings.
AccEPT: An Acceleration Scheme for Speeding Up Edge Pipeline-parallel Training
Nov 10, 2023



It is usually infeasible to fit and train an entire large deep neural network (DNN) model using a single edge device due to the limited resources. To facilitate intelligent applications across edge devices, researchers have proposed partitioning a large model into several sub-models, and deploying each of them to a different edge device to collaboratively train a DNN model. However, the communication overhead caused by the large amount of data transmitted from one device to another during training, as well as the sub-optimal partition point due to the inaccurate latency prediction of computation at each edge device can significantly slow down training. In this paper, we propose AccEPT, an acceleration scheme for accelerating the edge collaborative pipeline-parallel training. In particular, we propose a light-weight adaptive latency predictor to accurately estimate the computation latency of each layer at different devices, which also adapts to unseen devices through continuous learning. Therefore, the proposed latency predictor leads to better model partitioning which balances the computation loads across participating devices. Moreover, we propose a bit-level computation-efficient data compression scheme to compress the data to be transmitted between devices during training. Our numerical results demonstrate that our proposed acceleration approach is able to significantly speed up edge pipeline parallel training up to 3 times faster in the considered experimental settings.