 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim2Real Deep Transfer for Per-Device CFO Calibration
Jan 15, 2026Carrier Frequency Offset (CFO) estimation in Orthogonal Frequency Division Multiplexing (OFDM) systems faces significant performance degradation across heterogeneous software-defined radio (SDR) platforms due to uncalibrated hardware impairments. Existing deep neural network (DNN)-based approaches lack device-level adaptation, limiting their practical deployment. This paper proposes a Sim2Real transfer learning framework for per-device CFO calibration, combining simulation-driven pretraining with lightweight receiver adaptation. A backbone DNN is pre-trained on synthetic OFDM signals incorporating parametric hardware distortions (e.g., phase noise, IQ imbalance), enabling generalized feature learning without costly cross-device data collection. Subsequently, only the regression layers are fine-tuned using $1,000$ real frames per target device, preserving hardware-agnostic knowledge while adapting to device-specific impairments. Experiments across three SDR families (USRP B210, USRP N210, HackRF One) achieve $30\times$ BER reduction compared to conventional CP-based methods under indoor multipath conditions. The framework bridges the simulation-to-reality gap for robust CFO estimation, enabling cost-effective deployment in heterogeneous wireless systems.
VICTOR: Dataset Copyright Auditing in Video Recognition Systems
Dec 16, 2025Video recognition systems are increasingly being deployed in daily life, such as content recommendation and security monitoring. To enhance video recognition development, many institutions have released high-quality public datasets with open-source licenses for training advanced models. At the same time, these datasets are also susceptible to misuse and infringement. Dataset copyright auditing is an effective solution to identify such unauthorized use. However, existing dataset copyright solutions primarily focus on the image domain; the complex nature of video data leaves dataset copyright auditing in the video domain unexplored. Specifically, video data introduces an additional temporal dimension, which poses significant challenges to the effectiveness and stealthiness of existing methods. In this paper, we propose VICTOR, the first dataset copyright auditing approach for video recognition systems. We develop a general and stealthy sample modification strategy that enhances the output discrepancy of the target model. By modifying only a small proportion of samples (e.g., 1%), VICTOR amplifies the impact of published modified samples on the prediction behavior of the target models. Then, the difference in the model's behavior for published modified and unpublished original samples can serve as a key basis for dataset auditing. Extensive experiments on multiple models and datasets highlight the superiority of VICTOR. Finally, we show that VICTOR is robust in the presence of several perturbation mechanisms to the training videos or the target models.
Reverse Thinking Enhances Missing Information Detection in Large Language Models
Dec 11, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various reasoning tasks, yet they often struggle with problems involving missing information, exhibiting issues such as incomplete responses, factual errors, and hallucinations. While forward reasoning approaches like Chain-of-Thought (CoT) and Tree-of-Thought (ToT) have shown success in structured problem-solving, they frequently fail to systematically identify and recover omitted information. In this paper, we explore the potential of reverse thinking methodologies to enhance LLMs' performance on missing information detection tasks. Drawing inspiration from recent work on backward reasoning, we propose a novel framework that guides LLMs through reverse thinking to identify necessary conditions and pinpoint missing elements. Our approach transforms the challenging task of missing information identification into a more manageable backward reasoning problem, significantly improving model accuracy. Experimental results demonstrate that our reverse thinking approach achieves substantial performance gains compared to traditional forward reasoning methods, providing a promising direction for enhancing LLMs' logical completeness and reasoning robustness.
Hierarchical Schedule Optimization for Fast and Robust Diffusion Model Sampling
Nov 12, 2025


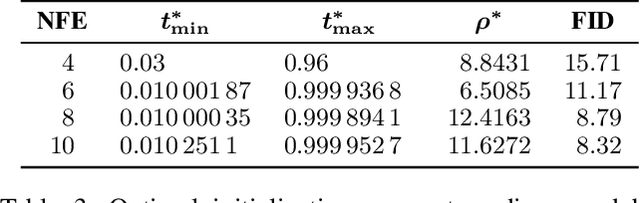
Diffusion probabilistic models have set a new standard for generative fidelity but are hindered by a slow iterative sampling process. A powerful training-free strategy to accelerate this process is Schedule Optimization, which aims to find an optimal distribution of timesteps for a fixed and small Number of Function Evaluations (NFE) to maximize sample quality. To this end, a successful schedule optimization method must adhere to four core principles: effectiveness, adaptivity, practical robustness, and computational efficiency. However, existing paradigms struggle to satisfy these principles simultaneously, motivating the need for a more advanced solution. To overcome these limitations, we propose the Hierarchical-Schedule-Optimizer (HSO), a novel and efficient bi-level optimization framework. HSO reframes the search for a globally optimal schedule into a more tractable problem by iteratively alternating between two synergistic levels: an upper-level global search for an optimal initialization strategy and a lower-level local optimization for schedule refinement. This process is guided by two key innovations: the Midpoint Error Proxy (MEP), a solver-agnostic and numerically stable objective for effective local optimization, and the Spacing-Penalized Fitness (SPF) function, which ensures practical robustness by penalizing pathologically close timesteps. Extensive experiments show that HSO sets a new state-of-the-art for training-free sampling in the extremely low-NFE regime. For instance, with an NFE of just 5, HSO achieves a remarkable FID of 11.94 on LAION-Aesthetics with Stable Diffusion v2.1. Crucially, this level of performance is attained not through costly retraining, but with a one-time optimization cost of less than 8 seconds, presenting a highly practical and efficient paradigm for diffusion model acceleration.
PointAD+: Learning Hierarchical Representations for Zero-shot 3D Anomaly Detection
Sep 03, 2025In this paper, we aim to transfer CLIP's robust 2D generalization capabilities to identify 3D anomalies across unseen objects of highly diverse class semantics. To this end, we propose a unified framework to comprehensively detect and segment 3D anomalies by leveraging both point- and pixel-level information. We first design PointAD, which leverages point-pixel correspondence to represent 3D anomalies through their associated rendering pixel representations. This approach is referred to as implicit 3D representation, as it focuses solely on rendering pixel anomalies but neglects the inherent spatial relationships within point clouds. Then, we propose PointAD+ to further broaden the interpretation of 3D anomalies by introducing explicit 3D representation, emphasizing spatial abnormality to uncover abnormal spatial relationships. Hence, we propose G-aggregation to involve geometry information to enable the aggregated point representations spatially aware. To simultaneously capture rendering and spatial abnormality, PointAD+ proposes hierarchical representation learning, incorporating implicit and explicit anomaly semantics into hierarchical text prompts: rendering prompts for the rendering layer and geometry prompts for the geometry layer. A cross-hierarchy contrastive alignment is further introduced to promote the interaction between the rendering and geometry layers, facilitating mutual anomaly learning. Finally, PointAD+ integrates anomaly semantics from both layers to capture the generalized anomaly semantics. During the test, PointAD+ can integrate RGB information in a plug-and-play manner and further improve its detection performance. Extensive experiments demonstrate the superiority of PointAD+ in ZS 3D anomaly detection across unseen objects with highly diverse class semantics, achieving a holistic understanding of abnormality.
Choice Outweighs Effort: Facilitating Complementary Knowledge Fusion in Federated Learning via Re-calibration and Merit-discrimination
Aug 25, 2025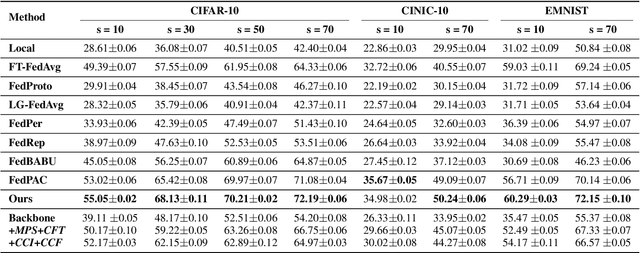
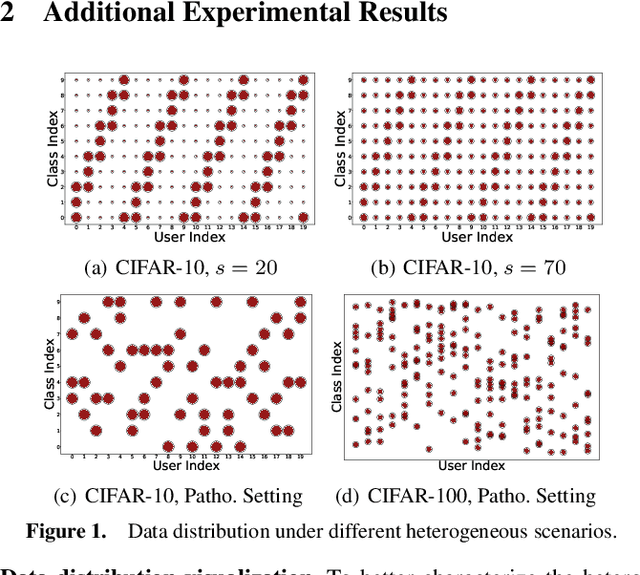

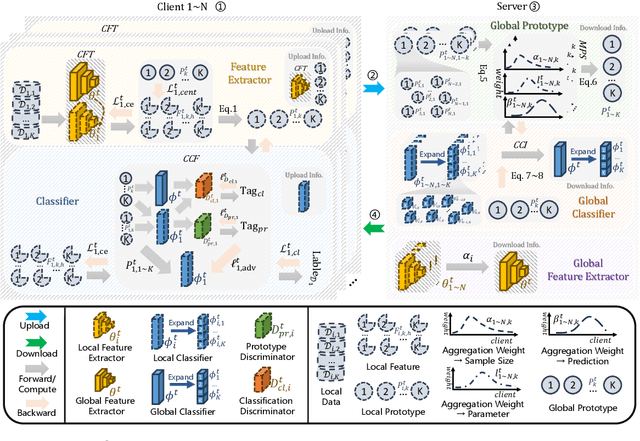
Cross-client data heterogeneity in federated learning induces biases that impede unbiased consensus condensation and the complementary fusion of generalization- and personalization-oriented knowledge. While existing approaches mitigate heterogeneity through model decoupling and representation center loss, they often rely on static and restricted metrics to evaluate local knowledge and adopt global alignment too rigidly, leading to consensus distortion and diminished model adaptability. To address these limitations, we propose FedMate, a method that implements bilateral optimization: On the server side, we construct a dynamic global prototype, with aggregation weights calibrated by holistic integration of sample size, current parameters, and future prediction; a category-wise classifier is then fine-tuned using this prototype to preserve global consistency. On the client side, we introduce complementary classification fusion to enable merit-based discrimination training and incorporate cost-aware feature transmission to balance model performance and communication efficiency. Experiments on five datasets of varying complexity demonstrate that FedMate outperforms state-of-the-art methods in harmonizing generalization and adaptation. Additionally, semantic segmentation experiments on autonomous driving datasets validate the method's real-world scalability.
FairDD: Fair Dataset Distillation via Synchronized Matching
Nov 29, 2024



Condensing large datasets into smaller synthetic counterparts has demonstrated its promise for image classification. However, previous research has overlooked a crucial concern in image recognition: ensuring that models trained on condensed datasets are unbiased towards protected attributes (PA), such as gender and race. Our investigation reveals that dataset distillation (DD) fails to alleviate the unfairness towards minority groups within original datasets. Moreover, this bias typically worsens in the condensed datasets due to their smaller size. To bridge the research gap, we propose a novel fair dataset distillation (FDD) framework, namely FairDD, which can be seamlessly applied to diverse matching-based DD approaches, requiring no modifications to their original architectures. The key innovation of FairDD lies in synchronously matching synthetic datasets to PA-wise groups of original datasets, rather than indiscriminate alignment to the whole distributions in vanilla DDs, dominated by majority groups. This synchronized matching allows synthetic datasets to avoid collapsing into majority groups and bootstrap their balanced generation to all PA groups. Consequently, FairDD could effectively regularize vanilla DDs to favor biased generation toward minority groups while maintaining the accuracy of target attributes. Theoretical analyses and extensive experimental evaluations demonstrate that FairDD significantly improves fairness compared to vanilla DD methods, without sacrificing classification accuracy. Its consistent superiority across diverse DDs, spanning Distribution and Gradient Matching, establishes it as a versatile FDD approach.
Radar and Camera Fusion for Object Detection and Tracking: A Comprehensive Survey
Oct 24, 2024



Multi-modal fusion is imperative to the implementation of reliable object detection and tracking in complex environments. Exploiting the synergy of heterogeneous modal information endows perception systems the ability to achieve more comprehensive, robust, and accurate performance. As a nucleus concern in wireless-vision collaboration, radar-camera fusion has prompted prospective research directions owing to its extensive applicability, complementarity, and compatibility. Nonetheless, there still lacks a systematic survey specifically focusing on deep fusion of radar and camera for object detection and tracking. To fill this void, we embark on an endeavor to comprehensively review radar-camera fusion in a holistic way. First, we elaborate on the fundamental principles, methodologies, and applications of radar-camera fusion perception. Next, we delve into the key techniques concerning sensor calibration, modal representation, data alignment, and fusion operation. Furthermore, we provide a detailed taxonomy covering the research topics related to object detection and tracking in the context of radar and camera technologies.Finally, we discuss the emerging perspectives in the field of radar-camera fusion perception and highlight the potential areas for future research.
Dataset Distillation-based Hybrid Federated Learning on Non-IID Data
Sep 26, 2024In federated learning, the heterogeneity of client data has a great impact on the performance of model training. Many heterogeneity issues in this process are raised by non-independently and identically distributed (Non-IID) data. This study focuses on the issue of label distribution skew. To address it, we propose a hybrid federated learning framework called HFLDD, which integrates dataset distillation to generate approximately independent and equally distributed (IID) data, thereby improving the performance of model training. Particularly, we partition the clients into heterogeneous clusters, where the data labels among different clients within a cluster are unbalanced while the data labels among different clusters are balanced. The cluster headers collect distilled data from the corresponding cluster members, and conduct model training in collaboration with the server. This training process is like traditional federated learning on IID data, and hence effectively alleviates the impact of Non-IID data on model training. Furthermore, we compare our proposed method with typical baseline methods on public datasets. Experimental results demonstrate that when the data labels are severely imbalanced, the proposed HFLDD outperforms the baseline methods in terms of both test accuracy and communication cost.
Secure Semantic Communication for Image Transmission in the Presence of Eavesdroppers
Apr 18, 2024Semantic communication (SemCom) has emerged as a key technology for the forthcoming sixth-generation (6G) network, attributed to its enhanced communication efficiency and robustness against channel noise. However, the open nature of wireless channels renders them vulnerable to eavesdropping, posing a serious threat to privacy. To address this issue, we propose a novel secure semantic communication (SemCom) approach for image transmission, which integrates steganography technology to conceal private information within non-private images (host images). Specifically, we propose an invertible neural network (INN)-based signal steganography approach, which embeds channel input signals of a private image into those of a host image before transmission. This ensures that the original private image can be reconstructed from the received signals at the legitimate receiver, while the eavesdropper can only decode the information of the host image. Simulation results demonstrate that the proposed approach maintains comparable reconstruction quality of both host and private images at the legitimate receiver, compared to scenarios without any secure mechanisms. Experiments also show that the eavesdropper is only able to reconstruct host images, showcasing the enhanced security provided by our approach.