 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointAD+: Learning Hierarchical Representations for Zero-shot 3D Anomaly Detection
Sep 03, 2025In this paper, we aim to transfer CLIP's robust 2D generalization capabilities to identify 3D anomalies across unseen objects of highly diverse class semantics. To this end, we propose a unified framework to comprehensively detect and segment 3D anomalies by leveraging both point- and pixel-level information. We first design PointAD, which leverages point-pixel correspondence to represent 3D anomalies through their associated rendering pixel representations. This approach is referred to as implicit 3D representation, as it focuses solely on rendering pixel anomalies but neglects the inherent spatial relationships within point clouds. Then, we propose PointAD+ to further broaden the interpretation of 3D anomalies by introducing explicit 3D representation, emphasizing spatial abnormality to uncover abnormal spatial relationships. Hence, we propose G-aggregation to involve geometry information to enable the aggregated point representations spatially aware. To simultaneously capture rendering and spatial abnormality, PointAD+ proposes hierarchical representation learning, incorporating implicit and explicit anomaly semantics into hierarchical text prompts: rendering prompts for the rendering layer and geometry prompts for the geometry layer. A cross-hierarchy contrastive alignment is further introduced to promote the interaction between the rendering and geometry layers, facilitating mutual anomaly learning. Finally, PointAD+ integrates anomaly semantics from both layers to capture the generalized anomaly semantics. During the test, PointAD+ can integrate RGB information in a plug-and-play manner and further improve its detection performance. Extensive experiments demonstrate the superiority of PointAD+ in ZS 3D anomaly detection across unseen objects with highly diverse class semantics, achieving a holistic understanding of abnormality.
CoCoL: A Communication Efficient Decentralized Collaborative Method for Multi-Robot Systems
Aug 28, 2025



Collaborative learning enhances the performance and adaptability of multi-robot systems in complex tasks but faces significant challenges due to high communication overhead and data heterogeneity inherent in multi-robot tasks. To this end, we propose CoCoL, a Communication efficient decentralized Collaborative Learning method tailored for multi-robot systems with heterogeneous local datasets. Leveraging a mirror descent framework, CoCoL achieves remarkable communication efficiency with approximate Newton-type updates by capturing the similarity between objective functions of robots, and reduces computational costs through inexact sub-problem solutions. Furthermore, the integration of a gradient tracking scheme ensures its robustness against data heterogeneity. Experimental results on three representative multi robot collaborative learning tasks show the superiority of the proposed CoCoL in significantly reducing both the number of communication rounds and total bandwidth consumption while maintaining state-of-the-art accuracy. These benefits are particularly evident in challenging scenarios involving non-IID (non-independent and identically distributed) data distribution, streaming data, and time-varying network topologies.
Enhancing LLMs for Time Series Forecasting via Structure-Guided Cross-Modal Alignment
May 19, 2025



The emerging paradigm of leveraging pretrained large language models (LLMs) for time series forecasting has predominantly employed linguistic-temporal modality alignment strategies through token-level or layer-wise feature mapping. However, these approaches fundamentally neglect a critical insight: the core competency of LLMs resides not merely in processing localized token features but in their inherent capacity to model holistic sequence structures. This paper posits that effective cross-modal alignment necessitates structural consistency at the sequence level. We propose the Structure-Guided Cross-Modal Alignment (SGCMA), a framework that fully exploits and aligns the state-transition graph structures shared by time-series and linguistic data as sequential modalities, thereby endowing time series with language-like properties and delivering stronger generalization after modality alignment. SGCMA consists of two key components, namely Structure Alignment and Semantic Alignment. In Structure Alignment, a state transition matrix is learned from text data through Hidden Markov Models (HMMs), and a shallow transformer-based Maximum Entropy Markov Model (MEMM) receives the hot-start transition matrix and annotates each temporal patch into state probability, ensuring that the temporal representation sequence inherits language-like sequential dynamics. In Semantic Alignment, cross-attention is applied between temporal patches and the top-k tokens within each state, and the ultimate temporal embeddings are derived by the expected value of these embeddings using a weighted average based on state probabilities. Experiments on multiple benchmarks demonstrate that SGCMA achieves state-of-the-art performance, offering a novel approach to cross-modal alignment in time series forecasting.
FairDD: Fair Dataset Distillation via Synchronized Matching
Nov 29, 2024



Condensing large datasets into smaller synthetic counterparts has demonstrated its promise for image classification. However, previous research has overlooked a crucial concern in image recognition: ensuring that models trained on condensed datasets are unbiased towards protected attributes (PA), such as gender and race. Our investigation reveals that dataset distillation (DD) fails to alleviate the unfairness towards minority groups within original datasets. Moreover, this bias typically worsens in the condensed datasets due to their smaller size. To bridge the research gap, we propose a novel fair dataset distillation (FDD) framework, namely FairDD, which can be seamlessly applied to diverse matching-based DD approaches, requiring no modifications to their original architectures. The key innovation of FairDD lies in synchronously matching synthetic datasets to PA-wise groups of original datasets, rather than indiscriminate alignment to the whole distributions in vanilla DDs, dominated by majority groups. This synchronized matching allows synthetic datasets to avoid collapsing into majority groups and bootstrap their balanced generation to all PA groups. Consequently, FairDD could effectively regularize vanilla DDs to favor biased generation toward minority groups while maintaining the accuracy of target attributes. Theoretical analyses and extensive experimental evaluations demonstrate that FairDD significantly improves fairness compared to vanilla DD methods, without sacrificing classification accuracy. Its consistent superiority across diverse DDs, spanning Distribution and Gradient Matching, establishes it as a versatile FDD approach.
Large Language Model Guided Knowledge Distillation for Time Series Anomaly Detection
Jan 26, 2024Self-supervised methods have gained prominence in time series anomaly detection due to the scarcity of available annotations. Nevertheless, they typically demand extensive training data to acquire a generalizable representation map, which conflicts with scenarios of a few available samples, thereby limiting their performance. To overcome the limitation, we propose \textbf{AnomalyLLM}, a knowledge distillation-based time series anomaly detection approach where the student network is trained to mimic the features of the large language model (LLM)-based teacher network that is pretrained on large-scale datasets. During the testing phase, anomalies are detected when the discrepancy between the features of the teacher and student networks is large. To circumvent the student network from learning the teacher network's feature of anomalous samples, we devise two key strategies. 1) Prototypical signals are incorporated into the student network to consolidate the normal feature extraction. 2) We use synthetic anomalies to enlarge the representation gap between the two networks. AnomalyLLM demonstrates state-of-the-art performance on 15 datasets, improving accuracy by at least 14.5\% in the UCR dataset.
Label-Free Multivariate Time Series Anomaly Detection
Dec 17, 2023Anomaly detection in multivariate time series (MTS) has been widely studied in one-class classification (OCC) setting. The training samples in OCC are assumed to be normal, which is difficult to guarantee in practical situations. Such a case may degrade the performance of OCC-based anomaly detection methods which fit the training distribution as the normal distribution. In this paper, we propose MTGFlow, an unsupervised anomaly detection approach for MTS anomaly detection via dynamic Graph and entity-aware normalizing Flow. MTGFlow first estimates the density of the entire training samples and then identifies anomalous instances based on the density of the test samples within the fitted distribution. This relies on a widely accepted assumption that anomalous instances exhibit more sparse densities than normal ones, with no reliance on the clean training dataset. However, it is intractable to directly estimate the density due to complex dependencies among entities and their diverse inherent characteristics. To mitigate this, we utilize the graph structure learning model to learn interdependent and evolving relations among entities, which effectively captures complex and accurate distribution patterns of MTS. In addition, our approach incorporates the unique characteristics of individual entities by employing an entity-aware normalizing flow. This enables us to represent each entity as a parameterized normal distribution. Furthermore, considering that some entities present similar characteristics, we propose a cluster strategy that capitalizes on the commonalities of entities with similar characteristics, resulting in more precise and detailed density estimation. We refer to this cluster-aware extension as MTGFlow_cluster. Extensive experiments are conducted on six widely used benchmark datasets, in which MTGFlow and MTGFlow cluster demonstrate their superior detection performance.
MTGFlow: Unsupervised Multivariate Time Series Anomaly Detection via Dynamic Graph and Entity-aware Normalizing Flow
Aug 03, 2022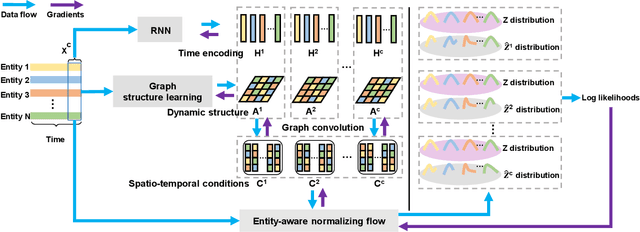

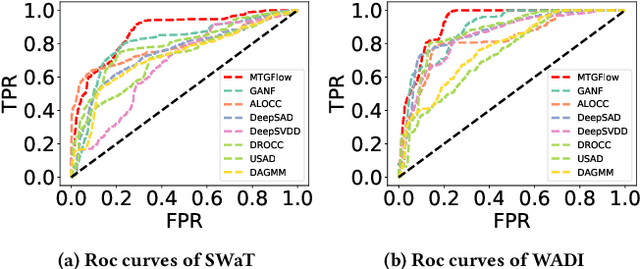

Multivariate time series anomaly detection has been extensively studied under the semi-supervised setting, where a training dataset with all normal instances is required. However, preparing such a dataset is very laborious since each single data instance should be fully guaranteed to be normal. It is, therefore, desired to explore multivariate time series anomaly detection methods based on the dataset without any label knowledge. In this paper, we propose MTGFlow, an unsupervised anomaly detection approach for Multivariate Time series anomaly detection via dynamic Graph and entity-aware normalizing Flow, leaning only on a widely accepted hypothesis that abnormal instances exhibit sparse densities than the normal. However, the complex interdependencies among entities and the diverse inherent characteristics of each entity pose significant challenges on the density estimation, let alone to detect anomalies based on the estimated possibility distribution. To tackle these problems, we propose to learn the mutual and dynamic relations among entities via a graph structure learning model, which helps to model accurate distribution of multivariate time series. Moreover, taking account of distinct characteristics of the individual entities, an entity-aware normalizing flow is developed to describe each entity into a parameterized normal distribution, thereby producing fine-grained density estimation. Incorporating these two strategies, MTGFlowachieves superior anomaly detection performance. Experiments on the real-world datasets are conducted, demonstrating that MTGFlow outperforms the state-of-the-art (SOTA) by 5.0% and 1.6% AUROC for SWaT and WADI datasets respectively. Also, through the anomaly scores contributed by individual entities, MTGFlow can provide explanation information for the detection results.
Few-shot learning with improved local representations via bias rectify module
Nov 01, 2021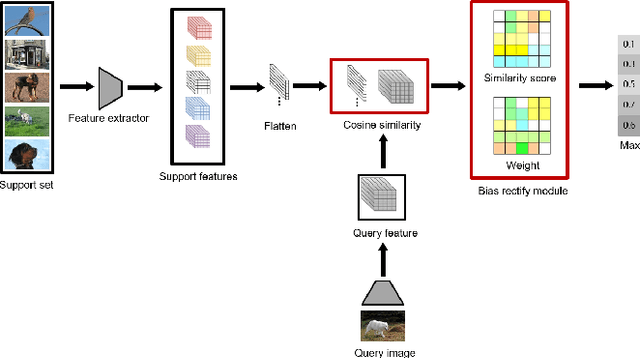


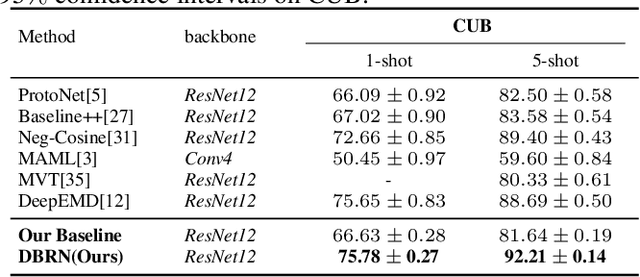
Recent approaches based on metric learning have achieved great progress in few-shot learning. However, most of them are limited to image-level representation manners, which fail to properly deal with the intra-class variations and spatial knowledge and thus produce undesirable performance. In this paper we propose a Deep Bias Rectify Network (DBRN) to fully exploit the spatial information that exists in the structure of the feature representations. We first employ a bias rectify module to alleviate the adverse impact caused by the intra-class variations. bias rectify module is able to focus on the features that are more discriminative for classification by given different weights. To make full use of the training data, we design a prototype augment mechanism that can make the prototypes generated from the support set to be more representative. To validate the effectiveness of our method, we conducted extensive experiments on various popular few-shot classification benchmarks and our methods can outperform state-of-the-art methods.