 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Eavesdroppers Reason: Agentic Eavesdropping Attacks on Semantic Communication
May 04, 2026Semantic communication (SemCom) has emerged as a promising paradigm for next-generation networks. However, its typical end-to-end joint source--channel coding (JSCC) architecture also raises serious privacy concerns. To guide future secure SemCom design, it is important to understand how serious such leakage can be. Nevertheless, existing eavesdropping attacks mainly rely on fixed-configuration solvers and often require instantaneous wiretap channel state information (CSI) to achieve effective privacy inference. This may lead future secure SemCom designs to overlook potentially severe risks. To address this, we propose a large language model (LLM)-orchestrated agentic eavesdropper. Specifically, the proposed eavesdropper forms a closed-loop workflow with three functional agents. The optimization agent adaptively performs joint semantic-and-channel inversion to recover private information from the intercepted signal without requiring wiretap CSI. The perception agent evaluates the effectiveness of the optimization agent and assesses whether the recovered private semantics are reasonable, providing feedback to the optimization agent. The refinement agent further analyzes the recovered content and uses a generative prior to refine promising candidates into more realistic and complete private reconstructions while preserving consistency with the intercepted signal. Simulation results over a MIMO Rayleigh fading channel show that the proposed eavesdropper achieves more than $75\%$ eavesdropping success rate at $\mathrm{SNR}\geq 5$~dB even without wiretap CSI, highlighting a severe privacy threat that future secure SemCom systems must address.
Improving Local Feature Matching by Entropy-inspired Scale Adaptability and Flow-endowed Local Consistency
Apr 08, 2026Recent semi-dense image matching methods have achieved remarkable success, but two long-standing issues still impair their performance. At the coarse stage, the over-exclusion issue of their mutual nearest neighbor (MNN) matching layer makes them struggle to handle cases with scale difference between images. To this end, we comprehensively revisit the matching mechanism and make a key observation that the hint concealed in the score matrix can be exploited to indicate the scale ratio. Based on this, we propose a scale-aware matching module which is exceptionally effective but introduces negligible overhead. At the fine stage, we point out that existing methods neglect the local consistency of final matches, which undermines their robustness. To this end, rather than independently predicting the correspondence for each source pixel, we reformulate the fine stage as a cascaded flow refinement problem and introduce a novel gradient loss to encourage local consistency of the flow field. Extensive experiments demonstrate that our novel matching pipeline, with these proposed modifications, achieves robust and accurate matching performance on downstream tasks.
DexRepNet++: Learning Dexterous Robotic Manipulation with Geometric and Spatial Hand-Object Representations
Feb 25, 2026Robotic dexterous manipulation is a challenging problem due to high degrees of freedom (DoFs) and complex contacts of multi-fingered robotic hands. Many existing deep reinforcement learning (DRL) based methods aim at improving sample efficiency in high-dimensional output action spaces. However, existing works often overlook the role of representations in achieving generalization of a manipulation policy in the complex input space during the hand-object interaction. In this paper, we propose DexRep, a novel hand-object interaction representation to capture object surface features and spatial relations between hands and objects for dexterous manipulation skill learning. Based on DexRep, policies are learned for three dexterous manipulation tasks, i.e. grasping, in-hand reorientation, bimanual handover, and extensive experiments are conducted to verify the effectiveness. In simulation, for grasping, the policy learned with 40 objects achieves a success rate of 87.9% on more than 5000 unseen objects of diverse categories, significantly surpassing existing work trained with thousands of objects; for the in-hand reorientation and handover tasks, the policies also boost the success rates and other metrics of existing hand-object representations by 20% to 40%. The grasp policies with DexRep are deployed to the real world under multi-camera and single-camera setups and demonstrate a small sim-to-real gap.
* Accepted by IEEE Transactions on Robotics (T-RO), 2026
Strategy-Supervised Autonomous Laparoscopic Camera Control via Event-Driven Graph Mining
Feb 24, 2026Autonomous laparoscopic camera control must maintain a stable and safe surgical view under rapid tool-tissue interactions while remaining interpretable to surgeons. We present a strategy-grounded framework that couples high-level vision-language inference with low-level closed-loop control. Offline, raw surgical videos are parsed into camera-relevant temporal events (e.g., interaction, working-distance deviation, and view-quality degradation) and structured as attributed event graphs. Mining these graphs yields a compact set of reusable camera-handling strategy primitives, which provide structured supervision for learning. Online, a fine-tuned Vision-Language Model (VLM) processes the live laparoscopic view to predict the dominant strategy and discrete image-based motion commands, executed by an IBVS-RCM controller under strict safety constraints; optional speech input enables intuitive human-in-the-loop conditioning. On a surgeon-annotated dataset, event parsing achieves reliable temporal localization (F1-score 0.86), and the mined strategies show strong semantic alignment with expert interpretation (cluster purity 0.81). Extensive ex vivo experiments on silicone phantoms and porcine tissues demonstrate that the proposed system outperforms junior surgeons in standardized camera-handling evaluations, reducing field-of-view centering error by 35.26% and image shaking by 62.33%, while preserving smooth motion and stable working-distance regulation.
LOONG: Online Time-Optimal Autonomous Flight for MAVs in Cluttered Environments
Jan 12, 2026Autonomous flight of micro air vehicles (MAVs) in unknown, cluttered environments remains challenging for time-critical missions due to conservative maneuvering strategies. This article presents an integrated planning and control framework for high-speed, time-optimal autonomous flight of MAVs in cluttered environments. In each replanning cycle (100 Hz), a time-optimal trajectory under polynomial presentation is generated as a reference, with the time-allocation process accelerated by imitation learning. Subsequently, a time-optimal model predictive contouring control (MPCC) incorporates safe flight corridor (SFC) constraints at variable horizon steps to enable aggressive yet safe maneuvering, while fully exploiting the MAV's dynamics. We validate the proposed framework extensively on a custom-built LiDAR-based MAV platform. Simulation results demonstrate superior aggressiveness compared to the state of the art, while real-world experiments achieve a peak speed of 18 m/s in a cluttered environment and succeed in 10 consecutive trials from diverse start points. The video is available at the following link: https://youtu.be/vexXXhv99oQ.
Rethinking Secure Semantic Communications in the Age of Generative and Agentic AI: Threats and Opportunities
Jan 06, 2026Semantic communication (SemCom) improves communication efficiency by transmitting task-relevant information instead of raw bits and is expected to be a key technology for 6G networks. Recent advances in generative AI (GenAI) further enhance SemCom by enabling robust semantic encoding and decoding under limited channel conditions. However, these efficiency gains also introduce new security and privacy vulnerabilities. Due to the broadcast nature of wireless channels, eavesdroppers can also use powerful GenAI-based semantic decoders to recover private information from intercepted signals. Moreover, rapid advances in agentic AI enable eavesdroppers to perform long-term and adaptive inference through the integration of memory, external knowledge, and reasoning capabilities. This allows eavesdroppers to further infer user private behavior and intent beyond the transmitted content. Motivated by these emerging challenges, this paper comprehensively rethinks the security and privacy of SemCom systems in the age of generative and agentic AI. We first present a systematic taxonomy of eavesdropping threat models in SemCom systems. Then, we provide insights into how GenAI and agentic AI can enhance eavesdropping threats. Meanwhile, we also highlight potential opportunities for leveraging GenAI and agentic AI to design privacy-preserving SemCom systems.
DeepGuard: Defending Deep Joint Source-Channel Coding Against Eavesdropping at Physical-Layer
Dec 21, 2025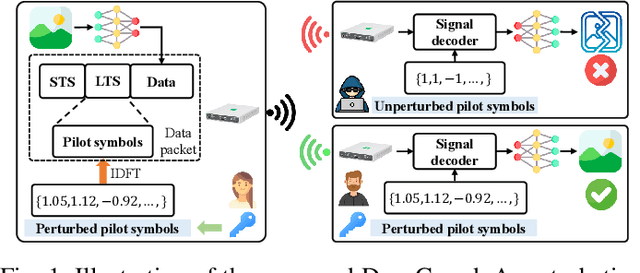
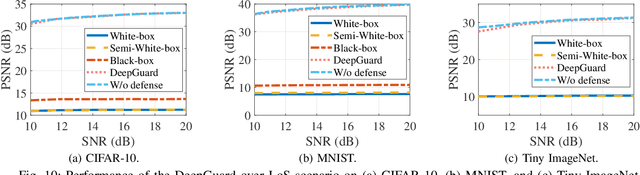
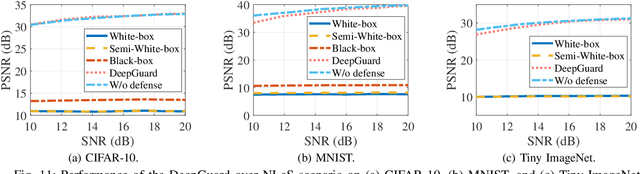

Deep joint source-channel coding (DeepJSCC) has emerged as a promising paradigm for efficient and robust information transmission. However, its intrinsic characteristics also pose new security challenges, notably an increased vulnerability to eavesdropping attacks. Existing studies on defending against eavesdropping attacks in DeepJSCC, while demonstrating certain effectiveness, often incur considerable computational overhead or introduce performance trade-offs that may adversely affect legitimate users. In this paper, we present DeepGuard, to the best of our knowledge, the first physical-layer defense framework for DeepJSCC against eavesdropping attacks, validated through over-the-air experiments using software-defined radios (SDRs). Considering that existing eavesdropping attacks against DeepJSCC are limited to simulation under ideal channels, we take a step further by identifying and implementing four representative types of attacks under various configurations in orthogonal frequency-division multiplexing systems. These attacks are evaluated over-the-air under diverse scenarios, allowing us to comprehensively characterize the real-world threat landscape. To mitigate these threats, DeepGuard introduces a novel preamble perturbation mechanism that modifies the preamble shared only between legitimate transceivers. To realize it, we first conduct a theoretical analysis of the perturbation's impact on the signals intercepted by the eavesdropper. Building upon this, we develop an end-to-end perturbation optimization algorithm that significantly degrades eavesdropping performance while preserving reliable communication for legitimate users. We prototype DeepGuard using SDRs and conduct extensive over-the-air experiments in practical scenarios. Extensive experiments demonstrate that DeepGuard effectively mitigates eavesdropping threats.
VICTOR: Dataset Copyright Auditing in Video Recognition Systems
Dec 16, 2025Video recognition systems are increasingly being deployed in daily life, such as content recommendation and security monitoring. To enhance video recognition development, many institutions have released high-quality public datasets with open-source licenses for training advanced models. At the same time, these datasets are also susceptible to misuse and infringement. Dataset copyright auditing is an effective solution to identify such unauthorized use. However, existing dataset copyright solutions primarily focus on the image domain; the complex nature of video data leaves dataset copyright auditing in the video domain unexplored. Specifically, video data introduces an additional temporal dimension, which poses significant challenges to the effectiveness and stealthiness of existing methods. In this paper, we propose VICTOR, the first dataset copyright auditing approach for video recognition systems. We develop a general and stealthy sample modification strategy that enhances the output discrepancy of the target model. By modifying only a small proportion of samples (e.g., 1%), VICTOR amplifies the impact of published modified samples on the prediction behavior of the target models. Then, the difference in the model's behavior for published modified and unpublished original samples can serve as a key basis for dataset auditing. Extensive experiments on multiple models and datasets highlight the superiority of VICTOR. Finally, we show that VICTOR is robust in the presence of several perturbation mechanisms to the training videos or the target models.
SenseRay-3D: Generalizable and Physics-Informed Framework for End-to-End Indoor Propagation Modeling
Nov 15, 2025Modeling indoor radio propagation is crucial for wireless network planning and optimization. However, existing approaches often rely on labor-intensive manual modeling of geometry and material properties, resulting in limited scalability and efficiency. To overcome these challenges, this paper presents SenseRay-3D, a generalizable and physics-informed end-to-end framework that predicts three-dimensional (3D) path-loss heatmaps directly from RGB-D scans, thereby eliminating the need for explicit geometry reconstruction or material annotation. The proposed framework builds a sensing-driven voxelized scene representation that jointly encodes occupancy, electromagnetic material characteristics, and transmitter-receiver geometry, which is processed by a SwinUNETR-based neural network to infer environmental path-loss relative to free-space path-loss. A comprehensive synthetic indoor propagation dataset is further developed to validate the framework and to serve as a standardized benchmark for future research. Experimental results show that SenseRay-3D achieves a mean absolute error of 4.27 dB on unseen environments and supports real-time inference at 217 ms per sample, demonstrating its scalability, efficiency, and physical consistency. SenseRay-3D paves a new path for sense-driven, generalizable, and physics-consistent modeling of indoor propagation, marking a major leap beyond our pioneering EM DeepRay framework.
Orientation Learning and Adaptation towards Simultaneous Incorporation of Multiple Local Constraints
Oct 09, 2025Orientation learning plays a pivotal role in many tasks. However, the rotation group SO(3) is a Riemannian manifold. As a result, the distortion caused by non-Euclidean geometric nature introduces difficulties to the incorporation of local constraints, especially for the simultaneous incorporation of multiple local constraints. To address this issue, we propose the Angle-Axis Space-based orientation representation method to solve several orientation learning problems, including orientation adaptation and minimization of angular acceleration. Specifically, we propose a weighted average mechanism in SO(3) based on the angle-axis representation method. Our main idea is to generate multiple trajectories by considering different local constraints at different basepoints. Then these multiple trajectories are fused to generate a smooth trajectory by our proposed weighted average mechanism, achieving the goal to incorporate multiple local constraints simultaneously. Compared with existing solution, ours can address the distortion issue and make the off-theshelf Euclidean learning algorithm be re-applicable in non-Euclidean space. Simulation and Experimental evaluations validate that our solution can not only adapt orientations towards arbitrary desired via-points and cope with angular acceleration constraints, but also incorporate multiple local constraints simultaneously to achieve extra benefits, e.g., achieving smaller acceleration costs.