 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderload: Defending against Latency Attacks for Object Detectors on Edge Devices
Dec 03, 2024Object detection is a fundamental enabler for many real-time downstream applications such as autonomous driving, augmented reality and supply chain management. However, the algorithmic backbone of neural networks is brittle to imperceptible perturbations in the system inputs, which were generally known as misclassifying attacks. By targeting the real-time processing capability, a new class of latency attacks are reported recently. They exploit new attack surfaces in object detectors by creating a computational bottleneck in the post-processing module, that leads to cascading failure and puts the real-time downstream tasks at risks. In this work, we take an initial attempt to defend against this attack via background-attentive adversarial training that is also cognizant of the underlying hardware capabilities. We first draw system-level connections between latency attack and hardware capacity across heterogeneous GPU devices. Based on the particular adversarial behaviors, we utilize objectness loss as a proxy and build background attention into the adversarial training pipeline, and achieve a reasonable balance between clean and robust accuracy. The extensive experiments demonstrate the defense effectiveness of restoring real-time processing capability from $13$ FPS to $43$ FPS on Jetson Orin NX, with a better trade-off between the clean and robust accuracy.
SAMG: State-Action-Aware Offline-to-Online Reinforcement Learning with Offline Model Guidance
Oct 24, 2024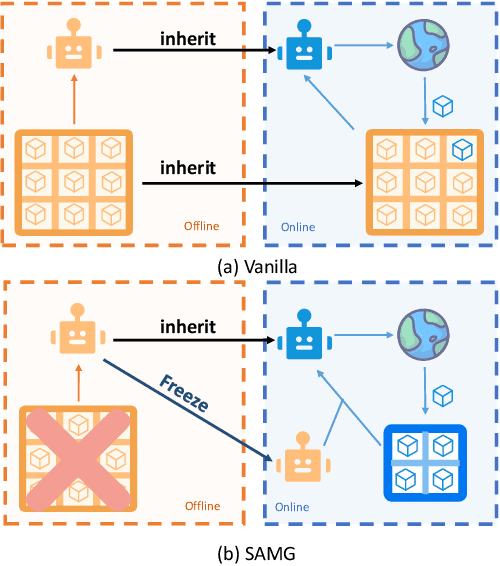
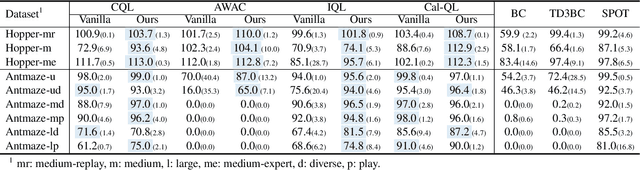
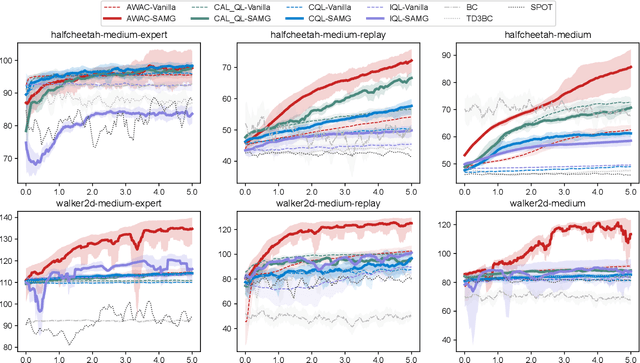

The offline-to-online (O2O) paradigm in reinforcement learning (RL) utilizes pre-trained models on offline datasets for subsequent online fine-tuning. However, conventional O2O RL algorithms typically require maintaining and retraining the large offline datasets to mitigate the effects of out-of-distribution (OOD) data, which limits their efficiency in exploiting online samples. To address this challenge, we introduce a new paradigm called SAMG: State-Action-Conditional Offline-to-Online Reinforcement Learning with Offline Model Guidance. In particular, rather than directly training on offline data, SAMG freezes the pre-trained offline critic to provide offline values for each state-action pair to deliver compact offline information. This framework eliminates the need for retraining with offline data by freezing and leveraging these values of the offline model. These are then incorporated with the online target critic using a Bellman equation weighted by a policy state-action-aware coefficient. This coefficient, derived from a conditional variational auto-encoder (C-VAE), aims to capture the reliability of the offline data on a state-action level. SAMG could be easily integrated with existing Q-function based O2O RL algorithms. Theoretical analysis shows good optimality and lower estimation error of SAMG. Empirical evaluations demonstrate that SAMG outperforms four state-of-the-art O2O RL algorithms in the D4RL benchmark.