 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuz-RL: A Fuzzy-Guided Robust Framework for Safe Reinforcement Learning under Uncertainty
Feb 24, 2026Safe Reinforcement Learning (RL) is crucial for achieving high performance while ensuring safety in real-world applications. However, the complex interplay of multiple uncertainty sources in real environments poses significant challenges for interpretable risk assessment and robust decision-making. To address these challenges, we propose Fuz-RL, a fuzzy measure-guided robust framework for safe RL. Specifically, our framework develops a novel fuzzy Bellman operator for estimating robust value functions using Choquet integrals. Theoretically, we prove that solving the Fuz-RL problem (in Constrained Markov Decision Process (CMDP) form) is equivalent to solving distributionally robust safe RL problems (in robust CMDP form), effectively avoiding min-max optimization. Empirical analyses on safe-control-gym and safety-gymnasium scenarios demonstrate that Fuz-RL effectively integrates with existing safe RL baselines in a model-free manner, significantly improving both safety and control performance under various types of uncertainties in observation, action, and dynamics.
Buffer Matters: Unleashing the Power of Off-Policy Reinforcement Learning in Large Language Model Reasoning
Feb 24, 2026Traditional on-policy Reinforcement Learning with Verifiable Rewards (RLVR) frameworks suffer from experience waste and reward homogeneity, which directly hinders learning efficiency on difficult samples during large language models post-training. In this paper, we introduce Batch Adaptation Policy Optimization (BAPO), an off-policy RLVR framework to improve the data efficiency in large language models post-training. It dynamically selects training batches by re-evaluating historically difficult samples and reusing high-quality ones, while holding a lower bound guarantee for policy improvement. Extensive experiments further demonstrate that BAPO achieves an average 12.5% improvement over GRPO across mathematics, planning, and visual reasoning tasks. Crucially, BAPO successfully resolves 40.7% of problems that base models consistently fail to solve.
RECITYGEN -- Interactive and Generative Participatory Urban Design Tool with Latent Diffusion and Segment Anything
Feb 04, 2026Urban design profoundly impacts public spaces and community engagement. Traditional top-down methods often overlook public input, creating a gap in design aspirations and reality. Recent advancements in digital tools, like City Information Modelling and augmented reality, have enabled a more participatory process involving more stakeholders in urban design. Further, deep learning and latent diffusion models have lowered barriers for design generation, providing even more opportunities for participatory urban design. Combining state-of-the-art latent diffusion models with interactive semantic segmentation, we propose RECITYGEN, a novel tool that allows users to interactively create variational street view images of urban environments using text prompts. In a pilot project in Beijing, users employed RECITYGEN to suggest improvements for an ongoing Urban Regeneration project. Despite some limitations, RECITYGEN has shown significant potential in aligning with public preferences, indicating a shift towards more dynamic and inclusive urban planning methods. The source code for the project can be found at RECITYGEN GitHub.
Sophia: A Persistent Agent Framework of Artificial Life
Dec 20, 2025
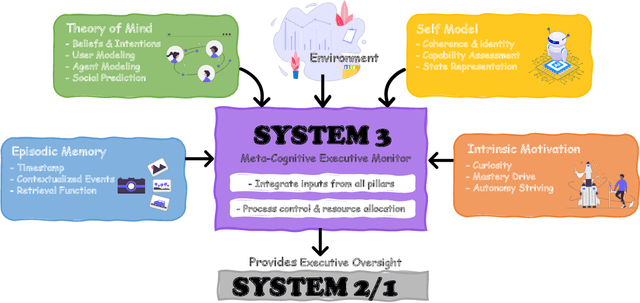
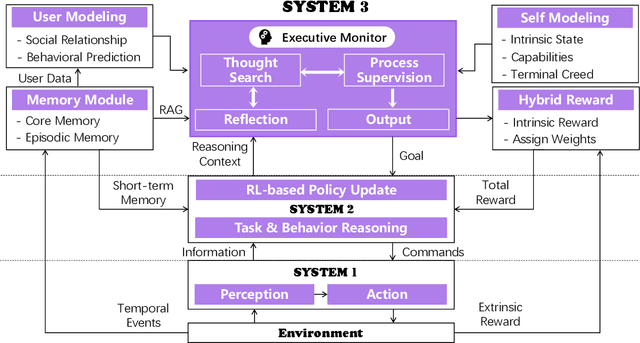
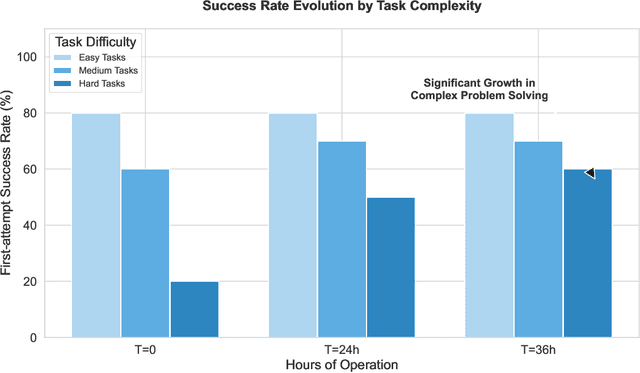
The development of LLMs has elevated AI agents from task-specific tools to long-lived, decision-making entities. Yet, most architectures remain static and reactive, tethered to manually defined, narrow scenarios. These systems excel at perception (System 1) and deliberation (System 2) but lack a persistent meta-layer to maintain identity, verify reasoning, and align short-term actions with long-term survival. We first propose a third stratum, System 3, that presides over the agent's narrative identity and long-horizon adaptation. The framework maps selected psychological constructs to concrete computational modules, thereby translating abstract notions of artificial life into implementable design requirements. The ideas coalesce in Sophia, a "Persistent Agent" wrapper that grafts a continuous self-improvement loop onto any LLM-centric System 1/2 stack. Sophia is driven by four synergistic mechanisms: process-supervised thought search, narrative memory, user and self modeling, and a hybrid reward system. Together, they transform repetitive reasoning into a self-driven, autobiographical process, enabling identity continuity and transparent behavioral explanations. Although the paper is primarily conceptual, we provide a compact engineering prototype to anchor the discussion. Quantitatively, Sophia independently initiates and executes various intrinsic tasks while achieving an 80% reduction in reasoning steps for recurring operations. Notably, meta-cognitive persistence yielded a 40% gain in success for high-complexity tasks, effectively bridging the performance gap between simple and sophisticated goals. Qualitatively, System 3 exhibited a coherent narrative identity and an innate capacity for task organization. By fusing psychological insight with a lightweight reinforcement-learning core, the persistent agent architecture advances a possible practical pathway toward artificial life.
VICTOR: Dataset Copyright Auditing in Video Recognition Systems
Dec 16, 2025Video recognition systems are increasingly being deployed in daily life, such as content recommendation and security monitoring. To enhance video recognition development, many institutions have released high-quality public datasets with open-source licenses for training advanced models. At the same time, these datasets are also susceptible to misuse and infringement. Dataset copyright auditing is an effective solution to identify such unauthorized use. However, existing dataset copyright solutions primarily focus on the image domain; the complex nature of video data leaves dataset copyright auditing in the video domain unexplored. Specifically, video data introduces an additional temporal dimension, which poses significant challenges to the effectiveness and stealthiness of existing methods. In this paper, we propose VICTOR, the first dataset copyright auditing approach for video recognition systems. We develop a general and stealthy sample modification strategy that enhances the output discrepancy of the target model. By modifying only a small proportion of samples (e.g., 1%), VICTOR amplifies the impact of published modified samples on the prediction behavior of the target models. Then, the difference in the model's behavior for published modified and unpublished original samples can serve as a key basis for dataset auditing. Extensive experiments on multiple models and datasets highlight the superiority of VICTOR. Finally, we show that VICTOR is robust in the presence of several perturbation mechanisms to the training videos or the target models.
Executable Analytic Concepts as the Missing Link Between VLM Insight and Precise Manipulation
Oct 09, 2025Enabling robots to perform precise and generalized manipulation in unstructured environments remains a fundamental challenge in embodied AI. While Vision-Language Models (VLMs) have demonstrated remarkable capabilities in semantic reasoning and task planning, a significant gap persists between their high-level understanding and the precise physical execution required for real-world manipulation. To bridge this "semantic-to-physical" gap, we introduce GRACE, a novel framework that grounds VLM-based reasoning through executable analytic concepts (EAC)-mathematically defined blueprints that encode object affordances, geometric constraints, and semantics of manipulation. Our approach integrates a structured policy scaffolding pipeline that turn natural language instructions and visual information into an instantiated EAC, from which we derive grasp poses, force directions and plan physically feasible motion trajectory for robot execution. GRACE thus provides a unified and interpretable interface between high-level instruction understanding and low-level robot control, effectively enabling precise and generalizable manipulation through semantic-physical grounding. Extensive experiments demonstrate that GRACE achieves strong zero-shot generalization across a variety of articulated objects in both simulated and real-world environments, without requiring task-specific training.
On-Device Training of PV Power Forecasting Models in a Smart Meter for Grid Edge Intelligence
Jul 09, 2025In this paper, an edge-side model training study is conducted on a resource-limited smart meter. The motivation of grid-edge intelligence and the concept of on-device training are introduced. Then, the technical preparation steps for on-device training are described. A case study on the task of photovoltaic power forecasting is presented, where two representative machine learning models are investigated: a gradient boosting tree model and a recurrent neural network model. To adapt to the resource-limited situation in the smart meter, "mixed"- and "reduced"-precision training schemes are also devised. Experiment results demonstrate the feasibility of economically achieving grid-edge intelligence via the existing advanced metering infrastructures.
PIG: Physically-based Multi-Material Interaction with 3D Gaussians
Jun 09, 20253D Gaussian Splatting has achieved remarkable success in reconstructing both static and dynamic 3D scenes. However, in a scene represented by 3D Gaussian primitives, interactions between objects suffer from inaccurate 3D segmentation, imprecise deformation among different materials, and severe rendering artifacts. To address these challenges, we introduce PIG: Physically-Based Multi-Material Interaction with 3D Gaussians, a novel approach that combines 3D object segmentation with the simulation of interacting objects in high precision. Firstly, our method facilitates fast and accurate mapping from 2D pixels to 3D Gaussians, enabling precise 3D object-level segmentation. Secondly, we assign unique physical properties to correspondingly segmented objects within the scene for multi-material coupled interactions. Finally, we have successfully embedded constraint scales into deformation gradients, specifically clamping the scaling and rotation properties of the Gaussian primitives to eliminate artifacts and achieve geometric fidelity and visual consistency. Experimental results demonstrate that our method not only outperforms the state-of-the-art (SOTA) in terms of visual quality, but also opens up new directions and pipelines for the field of physically realistic scene generation.
SSR: Enhancing Depth Perception in Vision-Language Models via Rationale-Guided Spatial Reasoning
May 18, 2025



Despite impressive advancements in Visual-Language Models (VLMs) for multi-modal tasks, their reliance on RGB inputs limits precise spatial understanding. Existing methods for integrating spatial cues, such as point clouds or depth, either require specialized sensors or fail to effectively exploit depth information for higher-order reasoning. To this end, we propose a novel Spatial Sense and Reasoning method, dubbed SSR, a novel framework that transforms raw depth data into structured, interpretable textual rationales. These textual rationales serve as meaningful intermediate representations to significantly enhance spatial reasoning capabilities. Additionally, we leverage knowledge distillation to compress the generated rationales into compact latent embeddings, which facilitate resource-efficient and plug-and-play integration into existing VLMs without retraining. To enable comprehensive evaluation, we introduce a new dataset named SSR-CoT, a million-scale visual-language reasoning dataset enriched with intermediate spatial reasoning annotations, and present SSRBench, a comprehensive multi-task benchmark. Extensive experiments on multiple benchmarks demonstrate SSR substantially improves depth utilization and enhances spatial reasoning, thereby advancing VLMs toward more human-like multi-modal understanding. Our project page is at https://yliu-cs.github.io/SSR.
2DGS-Avatar: Animatable High-fidelity Clothed Avatar via 2D Gaussian Splatting
Mar 04, 2025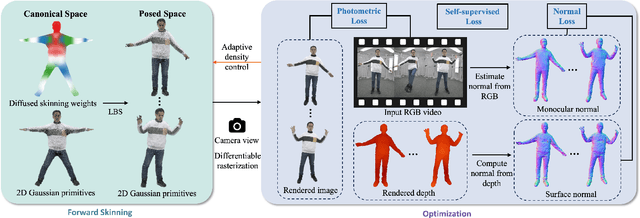
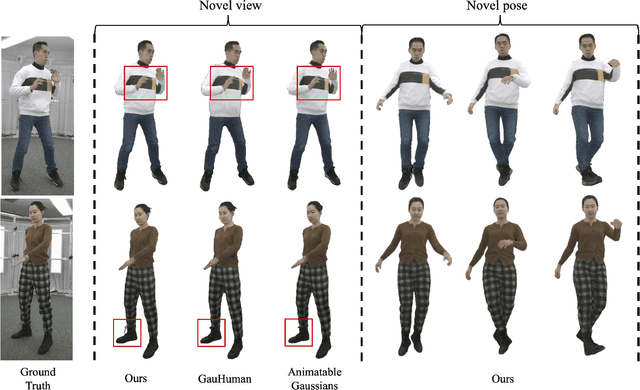

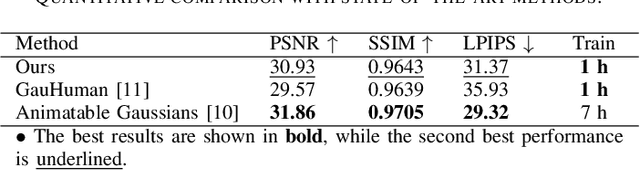
Real-time rendering of high-fidelity and animatable avatars from monocular videos remains a challenging problem in computer vision and graphics. Over the past few years, the Neural Radiance Field (NeRF) has made significant progress in rendering quality but behaves poorly in run-time performance due to the low efficiency of volumetric rendering. Recently, methods based on 3D Gaussian Splatting (3DGS) have shown great potential in fast training and real-time rendering. However, they still suffer from artifacts caused by inaccurate geometry. To address these problems, we propose 2DGS-Avatar, a novel approach based on 2D Gaussian Splatting (2DGS) for modeling animatable clothed avatars with high-fidelity and fast training performance. Given monocular RGB videos as input, our method generates an avatar that can be driven by poses and rendered in real-time. Compared to 3DGS-based methods, our 2DGS-Avatar retains the advantages of fast training and rendering while also capturing detailed, dynamic, and photo-realistic appearances. We conduct abundant experiments on popular datasets such as AvatarRex and THuman4.0, demonstrating impressive performance in both qualitative and quantitative metrics.